Anna Karenina by Leo Tolstoy: A Close and Distant Reading
For a good time, I decided to read Leo Tolstoy's Anna Karenina, but I assert there are many different types of reading, and I plan to apply both close as well as distant reading to the work. This essay describes what I learned from the processes.
If I am going to use the traditional (close) reading process to Anna Karenina, then I prefer to have a physical book because I find using the traditional reading process on a computer to be problematic. That said, I still downloaded a transcribed translation of Anna Karenina from Project Gutenberg (and cached locally, just in case). I then removed the license statements from the translation, formatted the result a bit, and created a rudimentary plain text version. I then poured the plain text in to a word processor, marked up the result in terms of title, chapter, and body values. This added formatting to the text. I then exported the formatted text as a PDF file and an EPub file. The PDF version is amenable to printing and thus somewhat amenable to traditional reading. The EPub version is more amenable to reading on various digital devices. In my copius spare time, I may apply a page layout process called "imposition" to the PDF file, print sets of signatures, and actually bind the book. I suppose I could break down and buy Anna Karenina in book form, but I haven't gotten around to it, yet.
While my traditional reading process was going on, I applied distant reading to the Anna Karenina. To do this I needed to create a data set amenable to computer analysis. Thus, I divided the work into individual files each one being a chapter, created a rudimentary metadata file describing them, and fed the result to a system of my own design -- the Distant Reader. From the result I learned and modeled the novel in a variety of ways.
For example, Anna Karenina is made up of eight parts, and each part is divided into a number of chapters; the book is divided into just less than 250 chapters and the whole work is about 369,000 words long. Based my experience, Anna Karenina is longer than many novels. As a case in point, Melville's Moby Dick, with 218,000 words, is often considered "long". On the other hand, the Bible is about 800,000 words long. Now, ask yourself, "About how many Moby Dick's fit into one Anna Karenina?" Moreover, assuming the typical scholarly journal article is between 5,000 and 7,000 words long, ask yourself, "How long are each of the chapters in Anna Karenina compared to scholarly journal articles? Longer? Shorter? By how much?" Why are all of these questions important? They are important because the answers to these question are immediately obvious when the works in question are manifested in printed forms, but when works are manfiested digitally, it is very difficult to decern lengths. Put another way, when reading anything you will probably want to know, "How much time will it take me to read this item?", and decerning lengths is a large part of addressing that question.
Readability is an additional factor when it comes to decerning the amount of time it may take to apply traditional reading to an item. In this case, I assert Anna Karenina has a Flesch Readability Score of around 72 -- where 0 denotes nobody can read the item and 100 denotes anybody can read the item. The Flesch Readability Score is based on many things: number of words, number of sentences, lengths of words, lengths of sentences, and the complexity or "density" of the vocabulary. Based on my experience, Anna Karenina is rather typical for popular works of fiction. Emma by Austen and Moby Dick also have readability scores in the 70s. Shakespeare's Sonnets have scores in the 90s because the words are short, the sentences are short, and the vocabulary is small. Scholarly journal articles seem to be in the 50s or 60s. Items with poor optical character recognition have scores that are even lower. Again, knowing the readability of an item helps one estimate the amount of time it will take to read it. When one has in hand a physically printed item, understanding readability is easier to decern than when the item is digitally manifested.
What is Anna Karenina about? As a librarian, I often ask myself this question of literary collections, such as a set of chapters from a given book, and there are many many was to address this question. Addressing the question bibliographically is a traditional approach. List the authors, titles, dates, keywords (subjects), and summarizes/abstracts of each item, read the results, and interpret aboutness. Such is what this data sets's index.txt and index.json files do. The human-readable index.txt file is easy to... read, but the list is long. Remember, there are 260 chapters to interpret. The computer-amenable index.json file contains the same information but in a more malleable form. In either case, one can use these files as surrogats for the chapters and garner aboutness. For extra credit, use a program like jq to transform the index.json file into a single paragarph for the purposes of traditional reading. For extra extra credit, tranform the index.json file into eight paragraphs, each being a summary of each book part.
Not incidentlly, the summaries in the index.txt and index.json files were derived from a process called "generative-AI". I then used this same process to summarize the summarizes. More specifically, I requested the sytem to return as if the summarizer were a helpful librarian and the summary was only two paragraphs long. Below is the result. I do not assert any truth in the result, only somethingn plausible. The redsult is intended to be food for thought.
The provided text covers pivotal plot points from Leo Tolstoy's Anna Karenina, focusing primarily on the intersecting lives of Stepan Oblonsky, Konstantin Levin, and Anna Karenina. The narrative begins with Oblonsky's marital infidelity and the resulting domestic strife, which introduces his sister Anna and her eventual entanglement with Count Vronsky. This affair leads to Anna’s social ostracization and profound personal crisis, culminating in her tragic end. Parallel to this, the text follows Levin's philosophical and emotional journey, detailing his courtship and marriage to Kitty Shcherbatskaya, his struggles with agricultural management, and his deep spiritual quest for meaning in life, which provides a thematic counterpoint to Anna’s story.
Beyond the central arcs, the summary touches on numerous subplots and secondary characters, such as Dolly Oblonsky's hardships, Sergei Ivanovich's intellectual pursuits, and the complexities of Russian high society. The text also highlights key events like Levin's participation in peasant farm work, the provincial elections, and Anna's desperate attempt to see her son. Ultimately, the narrative weaves together themes of love, faith, societal norms, and personal redemption, illustrating the contrast between Anna's destructive passion and Levin's search for existential peace through marriage and hard work.
Probably the most simplistic method to measure aboutness is to count and tabulate a collection's frequency of unigrams, bigrams, and keywords. Below are word clouds illustrating these frequencies (sans stop words), and I might assert Anna Karenina is about people, and maybe some of those people are named Anna, Kitty, Vronsky, Alexey, and Stephan. Be forewarned, the counting and tabulating of ngram frequencies is often considered sophmoric when it comes to denoting aboutness, but the process is quick and easy.
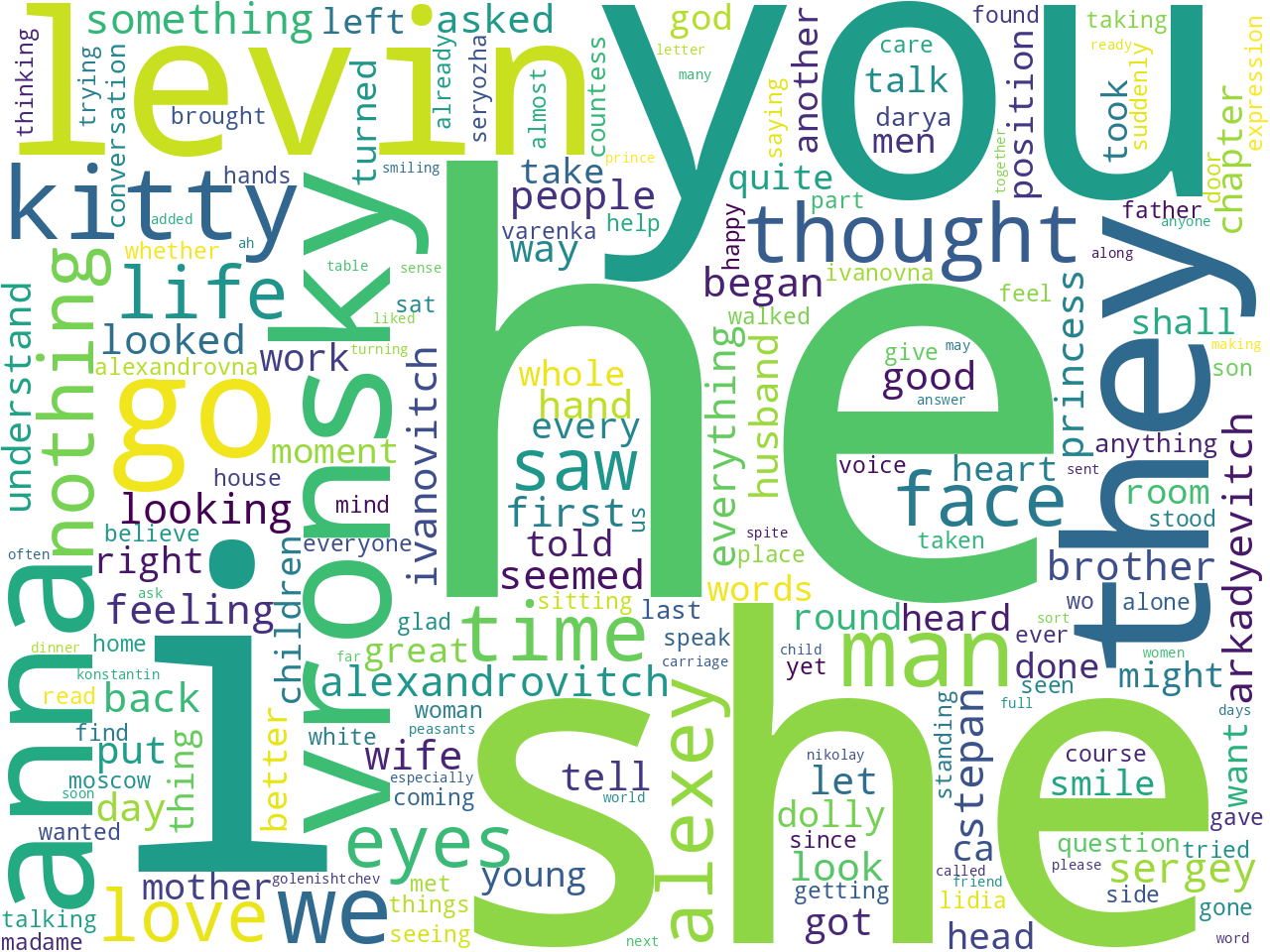 unigrams |
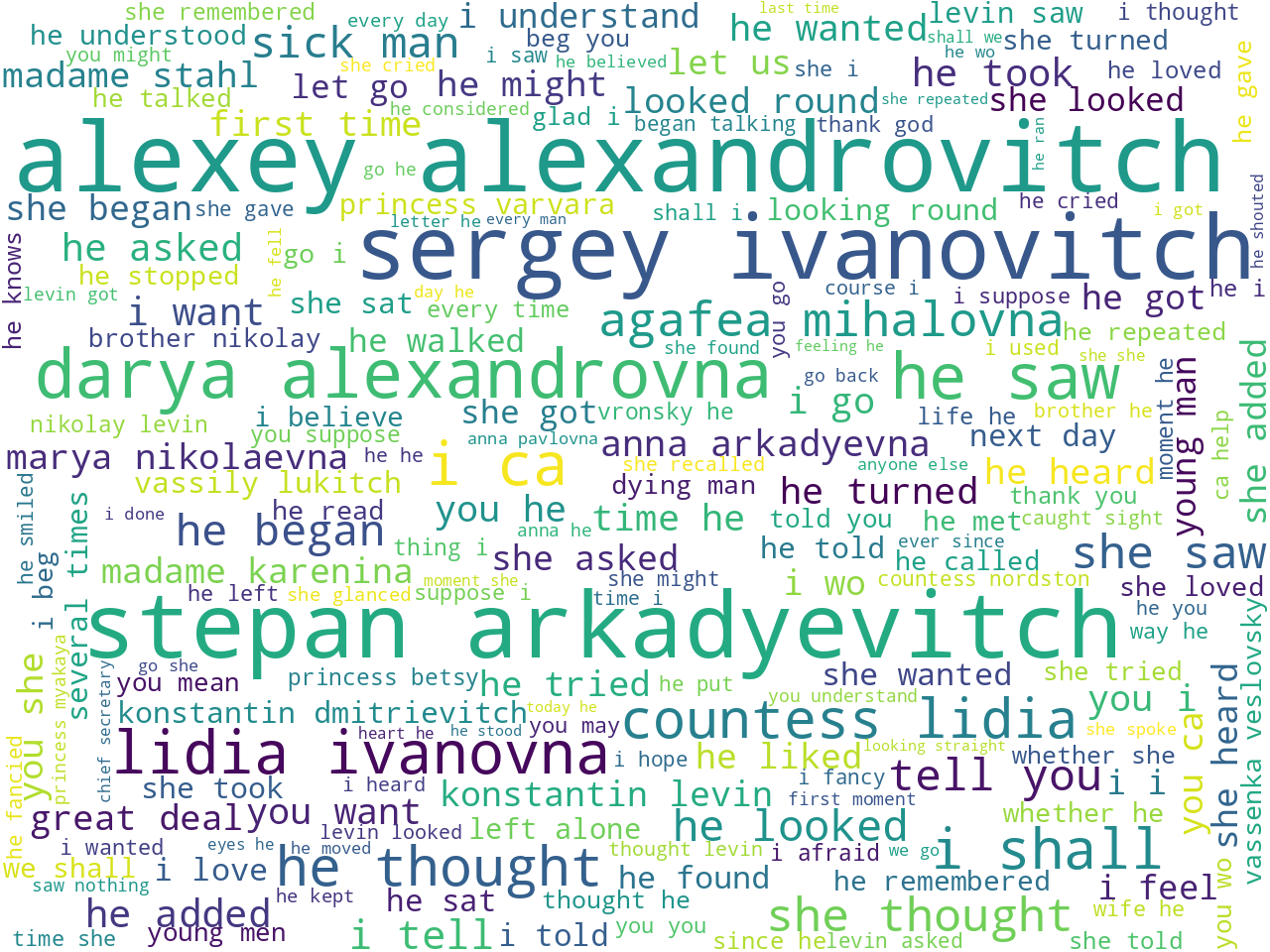 bigrams |
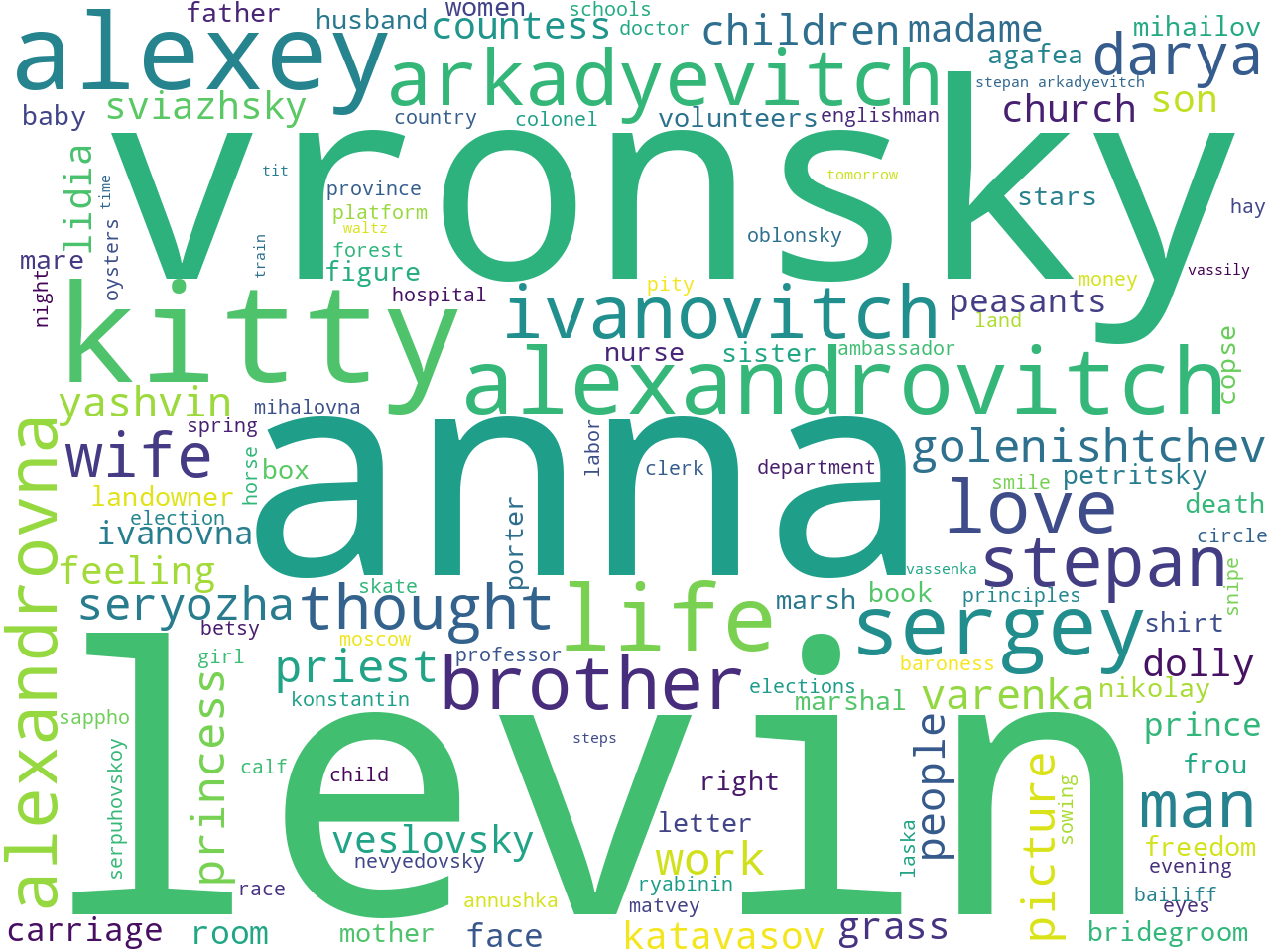 keywords |
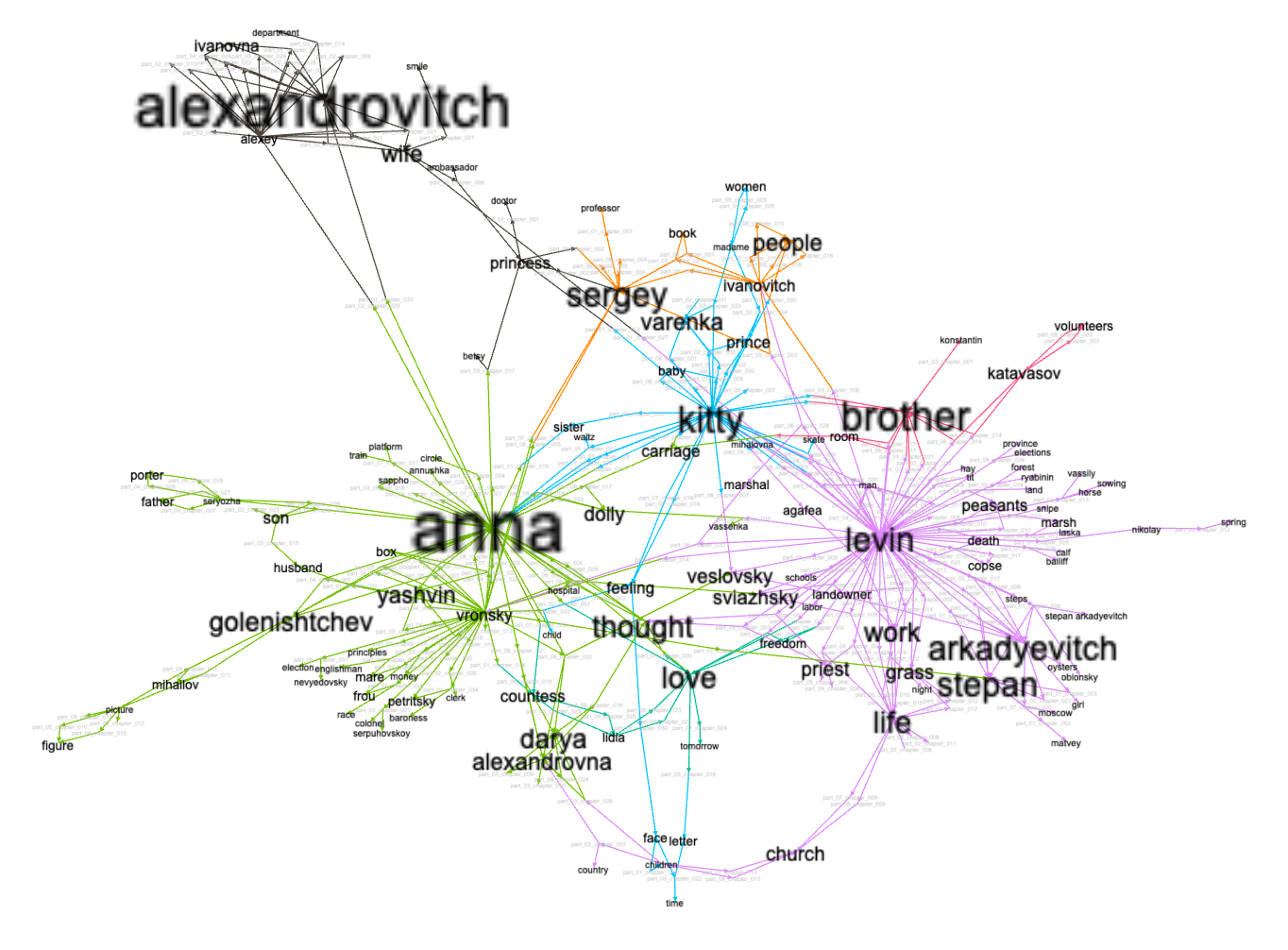
Creating network graphs is a way to model chapters and their associated keywords. Both chapters and keywords can be considered nodes in a network, and the association of chapters with keywords can be considered edges. I createed such a network. I then measured the degrees of each keyword and altered the size of the keyword accordingly. Similarly, I measured the modularity of the network to identify logical clusters ("neighborhoods"). The result is below. Naturally, it echoes the values of the keywords word cloud (above), but, in addition, the visualization illustrates the significance of the given keywords and their relationships to others. For example, Anna has a strong relationship with Kitty, and Kitty has a strong relationship with Levin, but Anna does not have a strong (if any) relationship with "brother", while Kitty and Levin share a relationship with "brother". Network graphs can bring to light many different relationships and their significance. This visualization is just one.
Another popular method to denote the aboutness of a collection is "topic modeling". Topic modeling is an unsupervised machine learning process used to enumerate latent themes in a corpus. It is a type of machine learning called "clustering". Given the fact that Anna Karenina is divided into eight parts, I assumed there might be eight distinct themes in the work. Thus I modeled for eight topics and the resulting topics included: "anna", "levin", "kitty", "sergey", "life", "veslovsky", "alexey", and "vronsky". See below, and notice how the topics echo the word clouds above. Mind you, these topics ought to be read as short-hand for a set of hyphenated words. For example, "anna" ought to be interpreted as "anna-vronsky-face-stepan-arkadyevitch-eyes-smile-something". Similarly, "levin" ought to be intepreted as "levin-life-man-kitty-nothing-thought-brother-nikolay". And so on. Notice how the labels echo the keyword values in the word cloud and network visualizations above.
| labels | weights | features |
|---|---|---|
| anna | 0.39974 | anna vronsky face stepan arkadyevitch eyes smile something |
| levin | 0.18715 | levin life man kitty nothing thought brother nikolay |
| kitty | 0.11633 | kitty dolly darya alexandrovna children varenka mother seryozha |
| sergey | 0.11539 | levin sergey ivanovitch people katavasov sviazhsky conversation konstantin |
| life | 0.0778 | levin life thought god church priest time men |
| veslovsky | 0.07304 | levin veslovsky time man peasants peasant horses thought |
| alexey | 0.07189 | alexey alexandrovitch lidia ivanovna countess wife love time |
| vronsky | 0.06493 | vronsky golenishtchev picture anna mihailov man painting expression |
Each of the modeled topics are associated with "weights" -- scores denoting the size of the topic compared to the whole. Consequently, the model can be visualized as a pie chart illustrating the size of thje given topics, below. From the result you can see the "anna" topic is about one third of the whole, and four of the eight topics (half of the topics) consume three quarters of the whole. In short, much of the work is about a small number of things.
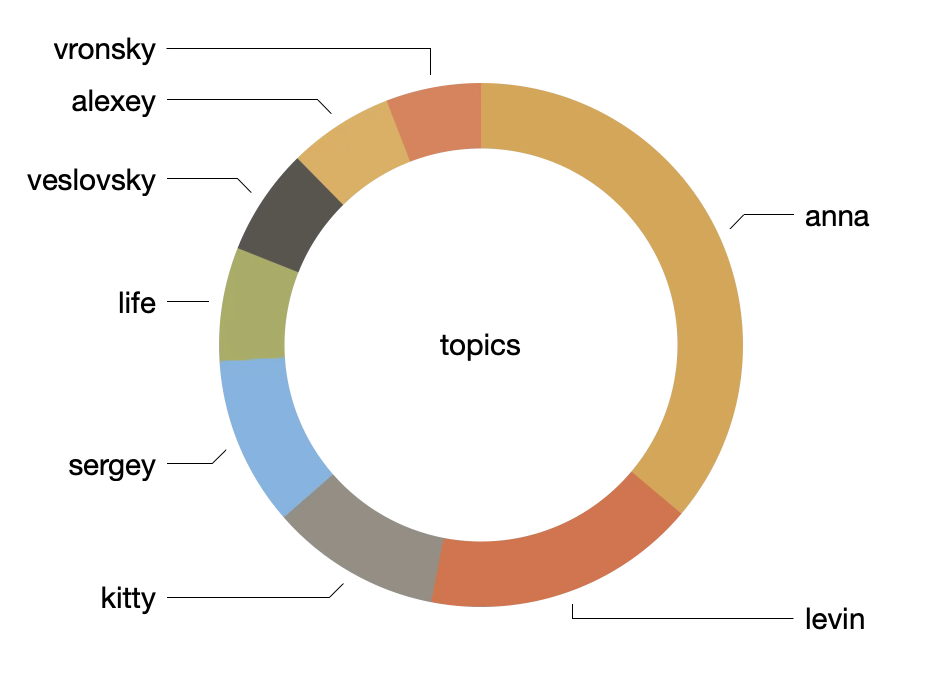
In this reading, topic modeling was done against chapters and chapters are manifested as files. Moreover, it is possible to reverse-engineer the topic model to return the most significant files (chapters) associated with a given topic. Such is what I did with the "anna" topic, and I assert the eight files listed below are a lot about "anna-vronsky-face-stepan-arkadyevitch-eyes-smile-something". Individually open the files and use your Web browser to search for things like "anna", "vronsky", "face", etc., and I believe you will discover these words appear rather frequently. (Hmmm. Notice how many of these eight files (chapters) come from Parts 4 and 5. Interesting?)
- Part 5 (Chapter 33)
- Part 4 (Chapter 33)
- Part 4 (Chapter 31)
- Part 4 (Chapter 28)
- Part 5 (Chapter 8)
- Part 1 (Chapter 18)
- Part 5 (Chapter 31)
- Part 5 (Chapter 32)
When topic modeling, metadata values can be associated with files to garder additional insights. In this case, part names and chapter titles were associated with each file. Once topic modeling is done one can pivot the model on the metadata values to measure the degree topics are associated with them. Doing so in this case one can address questions such as, "How do the topics manifest themselves from part to part, and how do topics manifest themselves over time?" The results are illustrated below.
For example, given the topics compared to parts visualization, we can see how the topic of "anna" decreases at the parts progress. The size of the "kitty" is constant across the parts, while the "life" topic increases. In my mind, mostd interestingly, Part 4 and Part 5 have the same ratio of topics. I assert somethign significantly different happens in Part 4 and Part 5. I wonder what it is. The line chart illusdtrates very the same thing. The light blue line denotes "anna", and you can see how it very gradually decreases of the course of the novel. You can also see how the line chart significanlty changes during Part 4 and Part 5 where the topics "levin" and "vronsky" dominate. Again, what happens in Part 4 and Part 5?
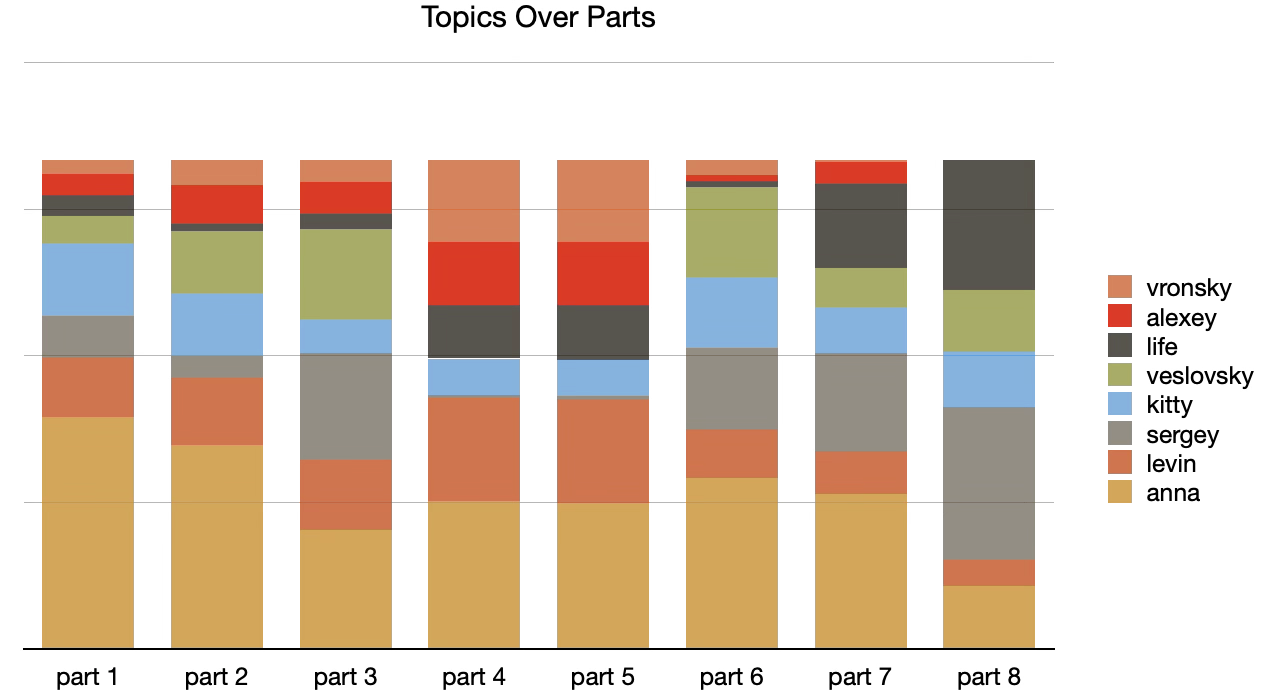

Eric Lease Morgan <eric_morgan@infomotions.com>
November 9, 2025