
unigrams
bigrams
computed keywords
Here is the briefest of descriptions outlining the size and scope of this data set called curated-blockchain_discussions-2025.
As a part of a study affectionately called Project Human Values, a colleague -- Jarek Nabrzyski -- asked me to collect and curate a set of documents written by people from the Etherium/Blockchain community. He gave me a list of URLs, and then I used an Internet spider program (wget) to locally cache the documents. (See the contents of the ./bin directory for more detail.) I then used a tool of my own design -- The Distant Reader -- to transform the cache into a data set -- a "study carrel".
The study carrel includes almost 3,400 items for a total of about 5 million words. (The Bible is about 800,000 words long.) These items are browsable from the ./txt directory. All of the analysis is/was derived from the content of the ./txt directory.
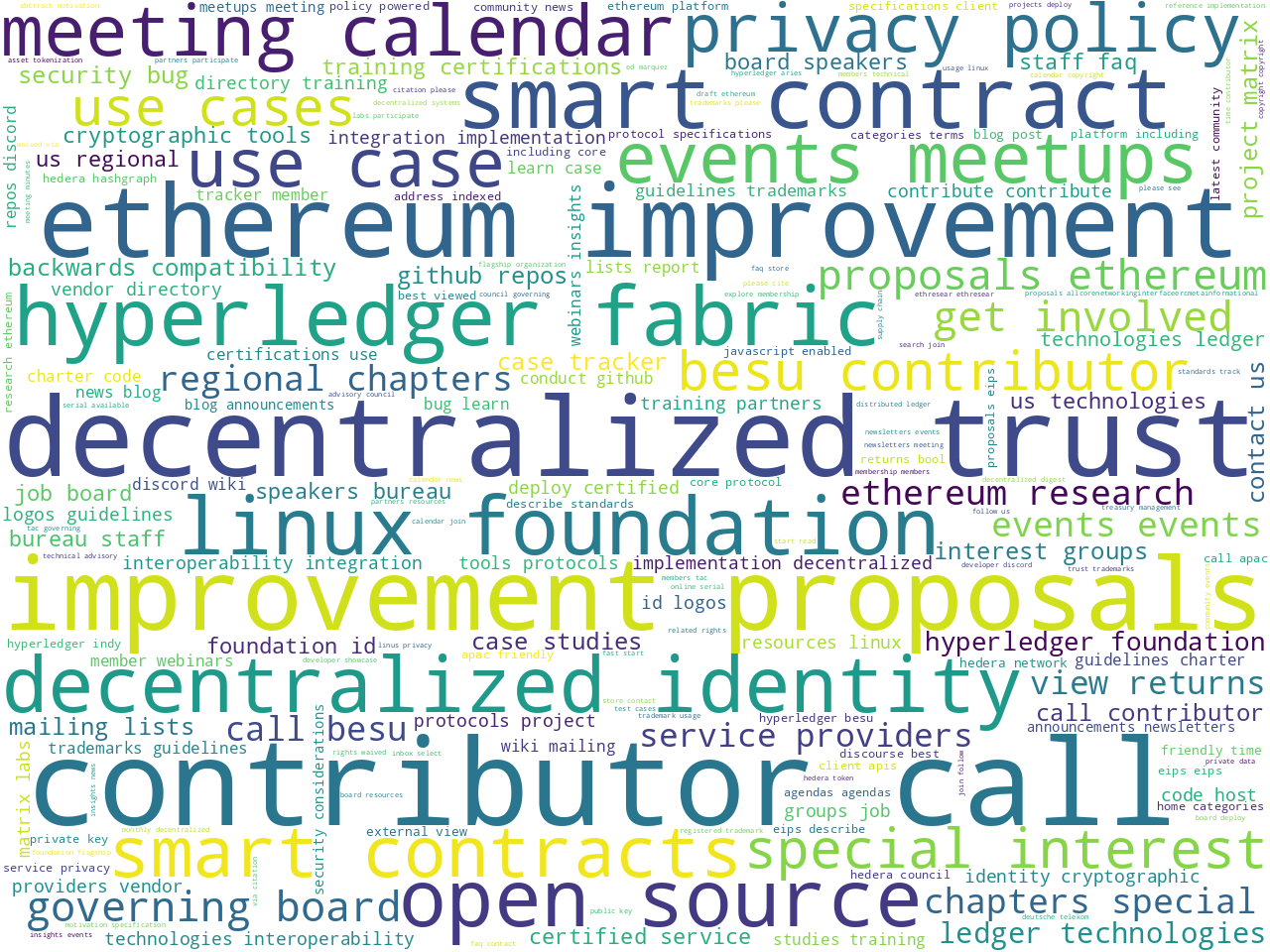
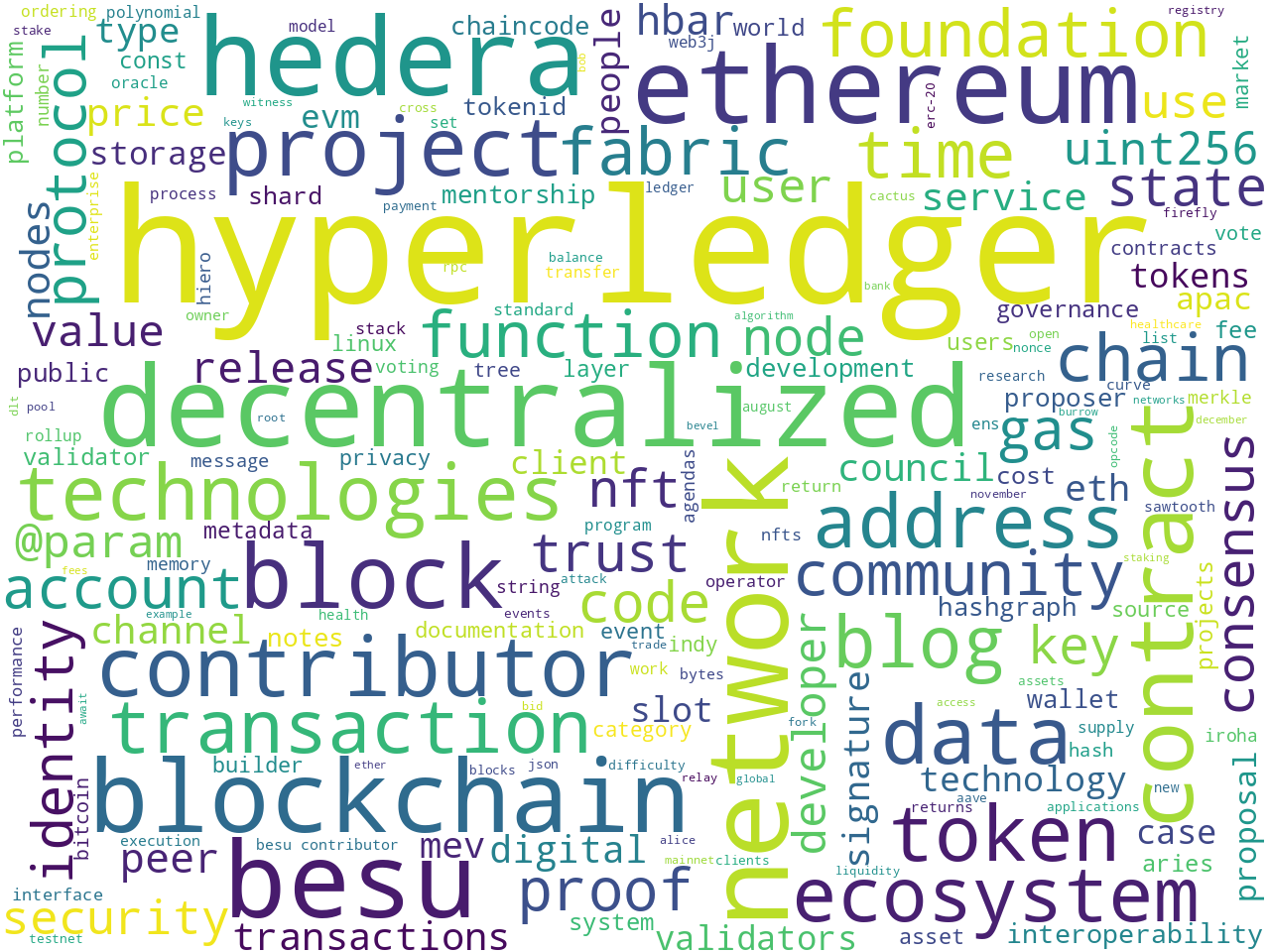
Word clouds depicting the frequency of unigrams, bigrams, and computed keywords begin to describe what is discucssed in the corpus:
unigrams |
bigrams |
computed keywords |
Topic modeling -- an unsupervised machine learning process used to cluster documents -- was applied to the corpus. After reducing our corpus to only include nouns, and after topic modeling on eight topics, we might say the corpus is about the following "themes":
| labels | weights | features |
|---|---|---|
| hyperledger | 0.09669 | hyperledger project blockchain foundation technology blog community trust |
| block | 0.0946 | block proof transaction node chain state validator datum |
| time | 0.08221 | block time ethereum builder price user protocol proposer |
| eip | 0.07043 | eip ethereum contract transaction gas proposal improvement code |
| address | 0.05173 | address contract function erc token uint nft param |
| peer | 0.03694 | peer channel chaincode fabric node network organization transaction |
| hedera | 0.03361 | hedera network developer ecosystem hbar web service nft |
| besu | 0.02739 | besu contributor call meeting agenda release time cookie |
This table can be visualized as a pie chart illustrating the degree each topic is a part of the whole. Furthermore, the model can be augmented with author values, pivoted, and visualized as a bar graph thus illustrating the degree each author discussed the computed topics. See below:
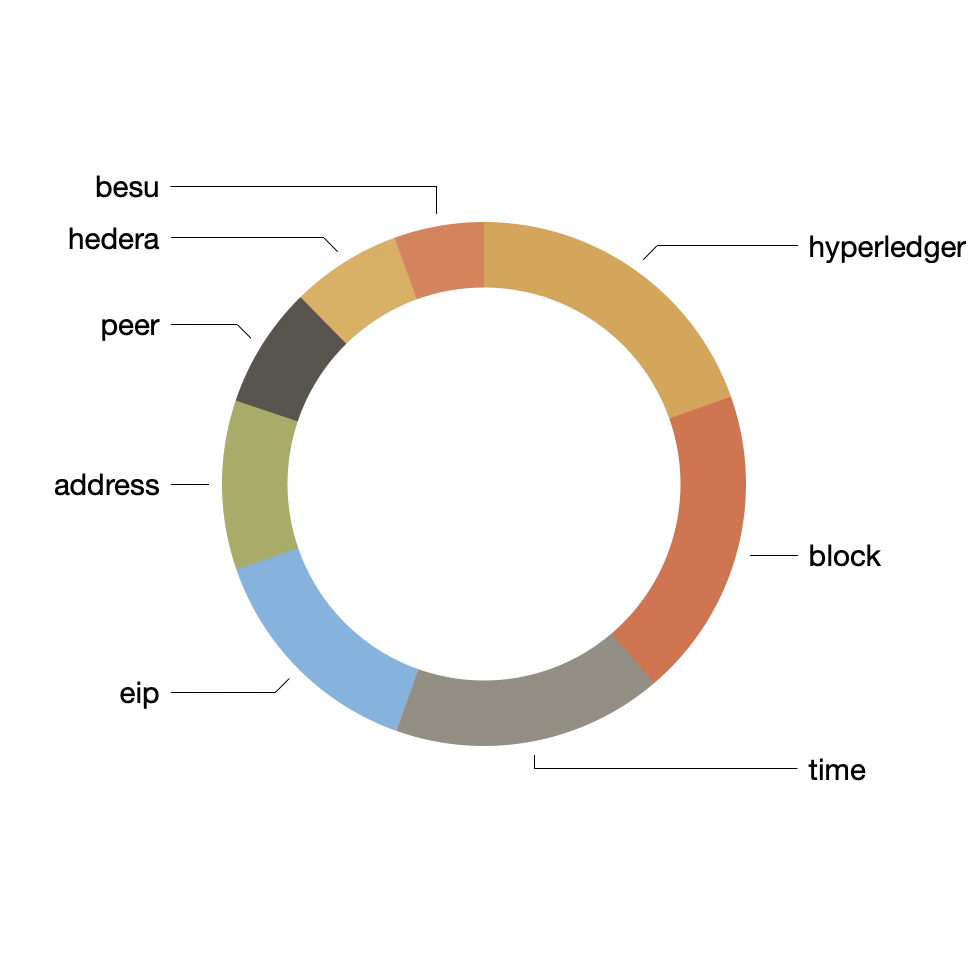 |
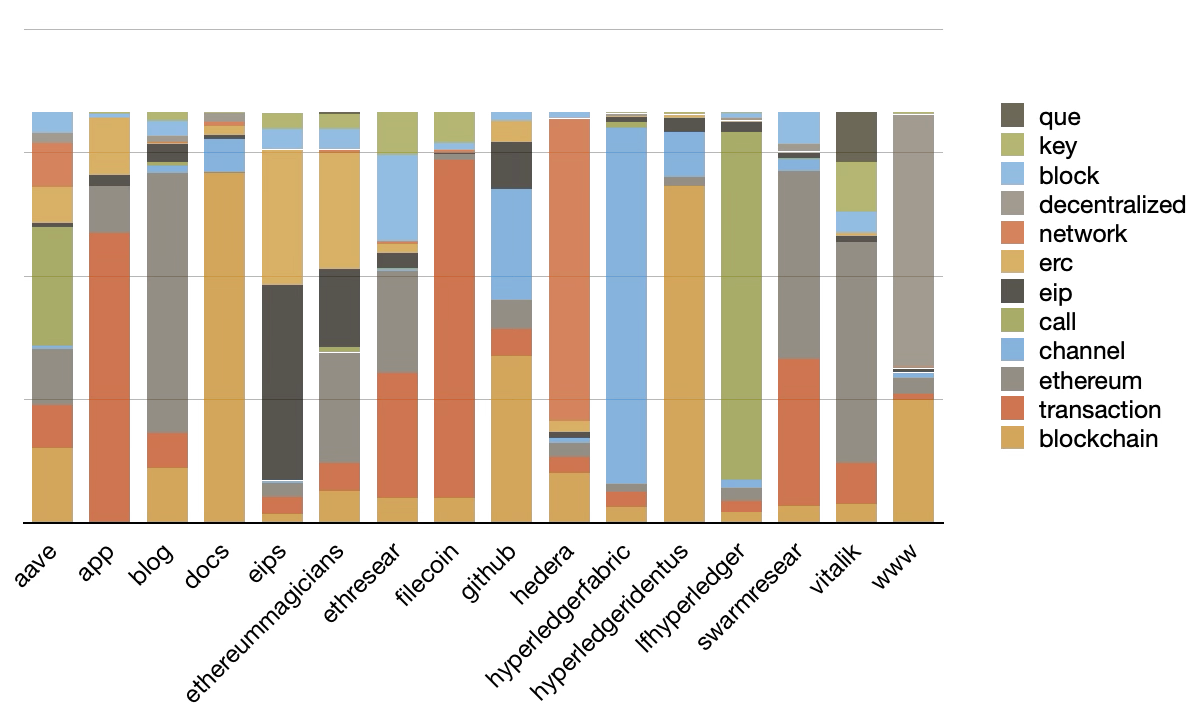 |
Perusing the computed bibliography is another way to learn of the data set's aboutness, and network graphs of the bibliographics highlight some of the characteristics.
 keywords and authors |
 clusters |
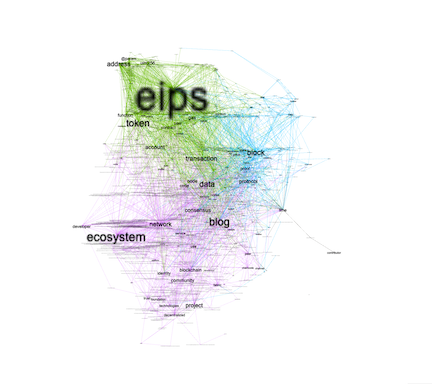 betweenesses |
A data set of about 3,400 items was created from writtings of the Etherium/Blockchain community. The sum size of the data set is about 5 million words, and it is about things such as "etherium", "protocols", "bitcoin", "proof", "data", and "people". For more detail, see the computed summary page.
This data set was created using a tool called the Distant Reader Toolbox, and the whole of the data set ought to be available for downloading at http://carrels.distantreader.org/curated-blockchain_discussions-2025/index.zip. For more information about Distant Reader study carrels, see the readme.txt file.
Eric Lease Morgan <emorgan@nd.edu>
Navari Family Center for Digital Scholarship
University of Notre Dame
May 7, 2025