
unigrams
bigrams

computed keywords
Here is the briefest of descriptions outlining the size and scope of this data set called curated-blockchain_discussions-other.
As a part of a study affectionately called Project Human Values, a colleague -- Jarek Nabrzyski -- asked me to collect and curate a set of documents written by people from the Etherium/Blockchain community. He gave me a list of URLs, and then I used an Internet spider program (wget) to locally cache the documents. (See the contents of the ./bin directory for more detail.) I then used a tool of my own design -- The Distant Reader -- to transform the cache into a data set -- a "study carrel".
The study carrel includes almost 270 items for a total of about 738,000 words. (The Bible is about 800,000 words long.) These items are browsable from the ./txt directory. All of the analysis is/was derived from the content of the ./txt directory.
Word clouds depicting the frequency of unigrams, bigrams, and computed keywords begin to describe what is discucssed in the corpus:
unigrams |
bigrams |
computed keywords |
Topic modeling -- an unsupervised machine learning process used to cluster documents -- was applied to the corpus, and we might say the corpus is about the following eight "themes":
| labels | weights | features |
|---|---|---|
| block | 0.28172 | block protocol proof time chain transaction blocks network bitcoin security blockchain stake |
| people | 0.23938 | people world community governance voting market projects system social price funding users |
| ethereum | 0.20849 | ethereum development protocol announcements security program research events foundation |
| data | 0.1774 | data state key ethereum users proof layer transaction blockchain applications proofs chain |
| polynomial | 0.07069 | polynomial points proof values polynomials number algorithm want time file note point |
| code | 0.05785 | code contract transaction gas ethereum state value account data block hash execution |
| die | 0.0054 | die bir der und von eine uma das zk-evm tip ist daha |
| que | 0.00426 | que una para los por che del con per más las jest |
This table can be visualized as a pie chart illustrating the degree each topic is a part of the whole. Furthermore, the model can be augmented with author values, pivoted, and visualized as a bar graph thus illustrating the degree each author discussed the computes topics. For example, Wood almost exclusively discussed "code" while Brody talks a lot about "etherium" and "people". See below:
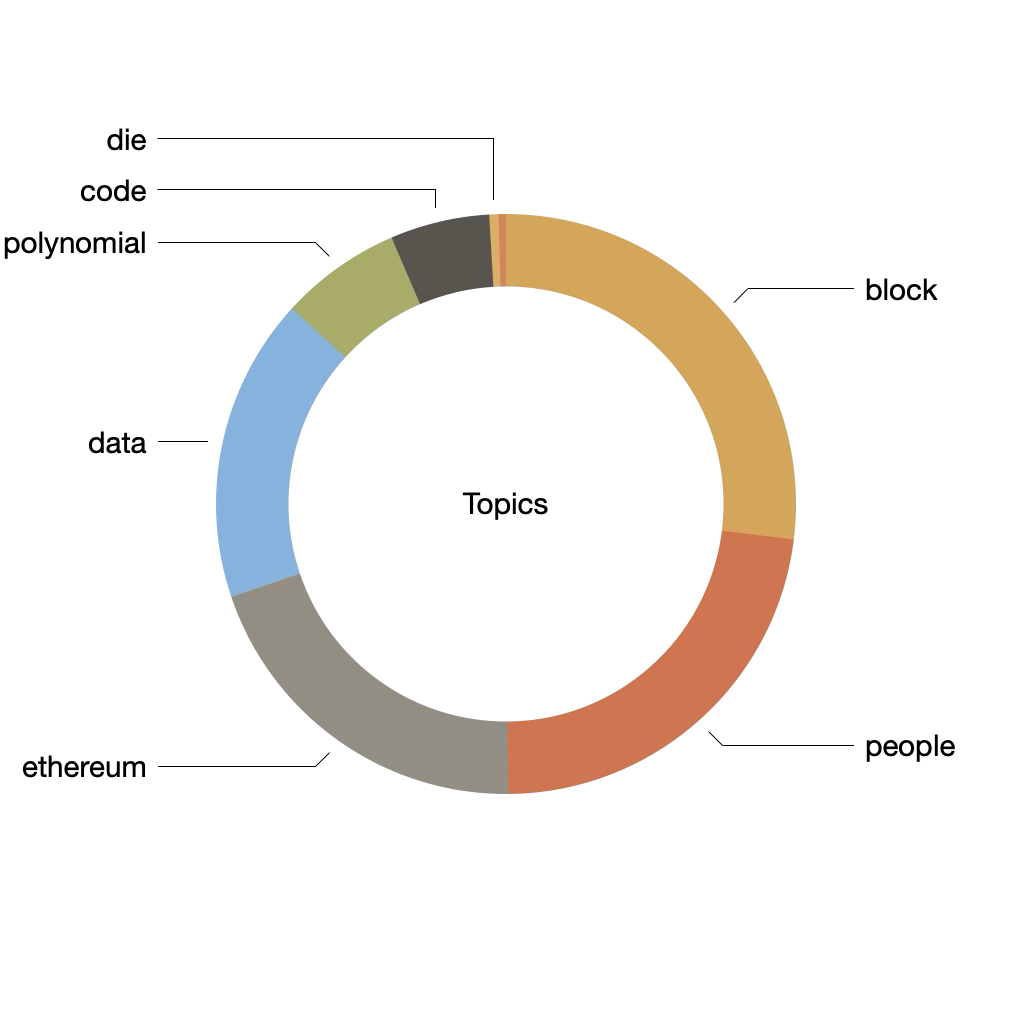 |
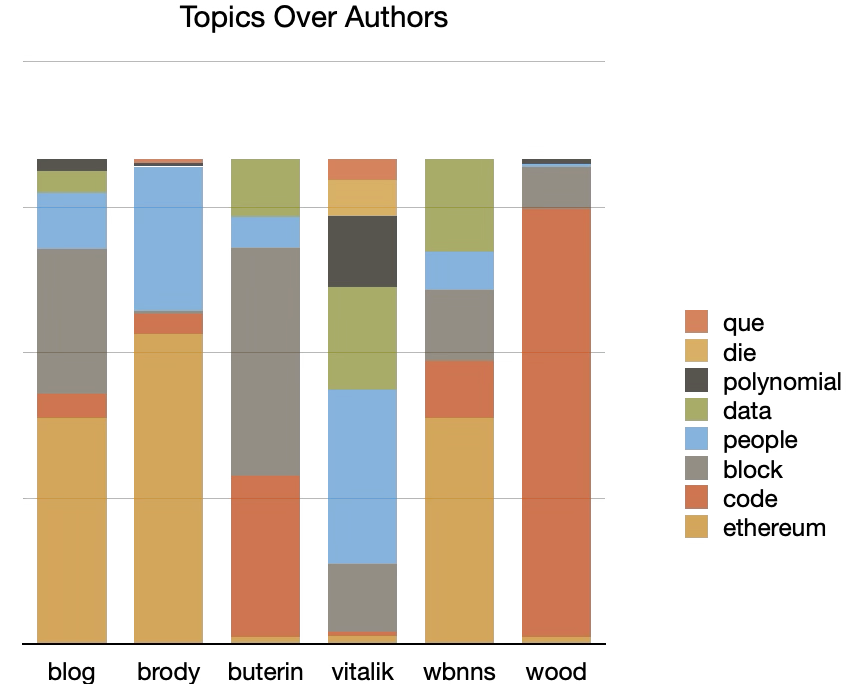 |
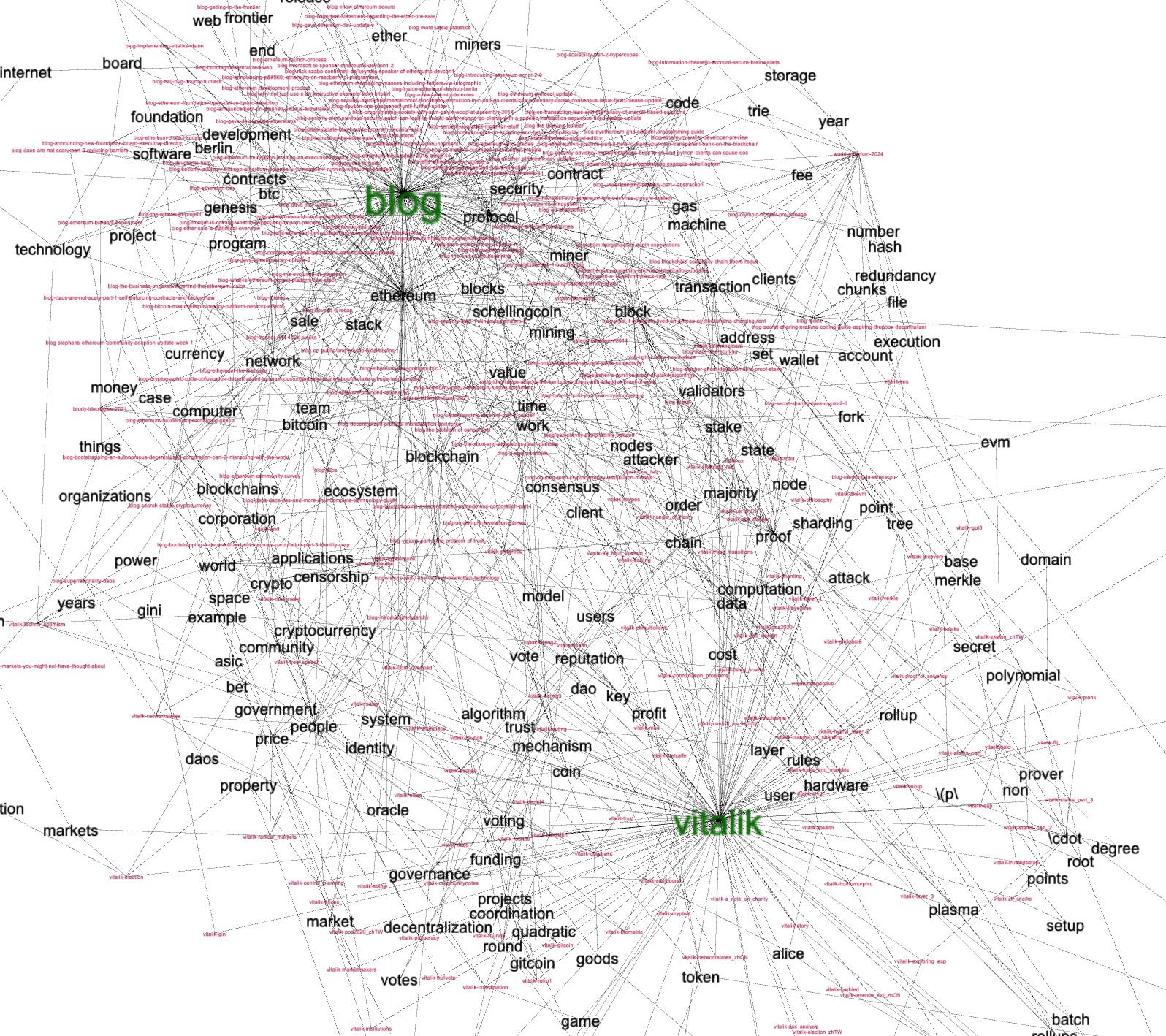
Perusing the computed bibliography is another way to learn of the data set's aboutness, and network graphs of the bibliographics highlight some of the characteristics. For example, we can see: 1) blog and vitalik were the most frequent authors and all of the things they discussed where discussed to a similar degree, 2) they do cluster into a small number of subsets, 3) and after computing betweeness values for each node, we might assert the nodes labeled "etherium", "block", "protocol", and "proof" are the most siginficant.
 keywords and authors |
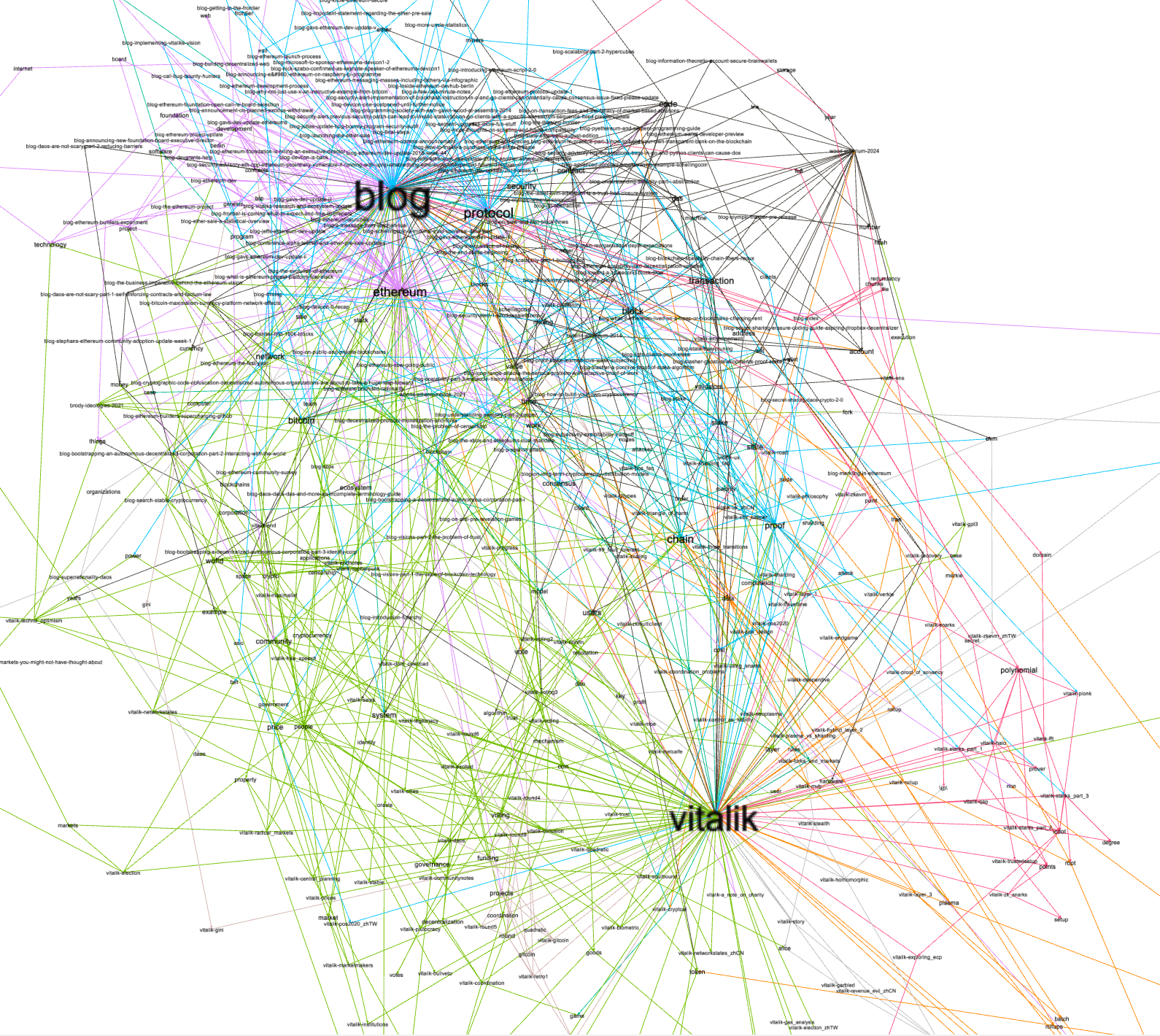 clusters |
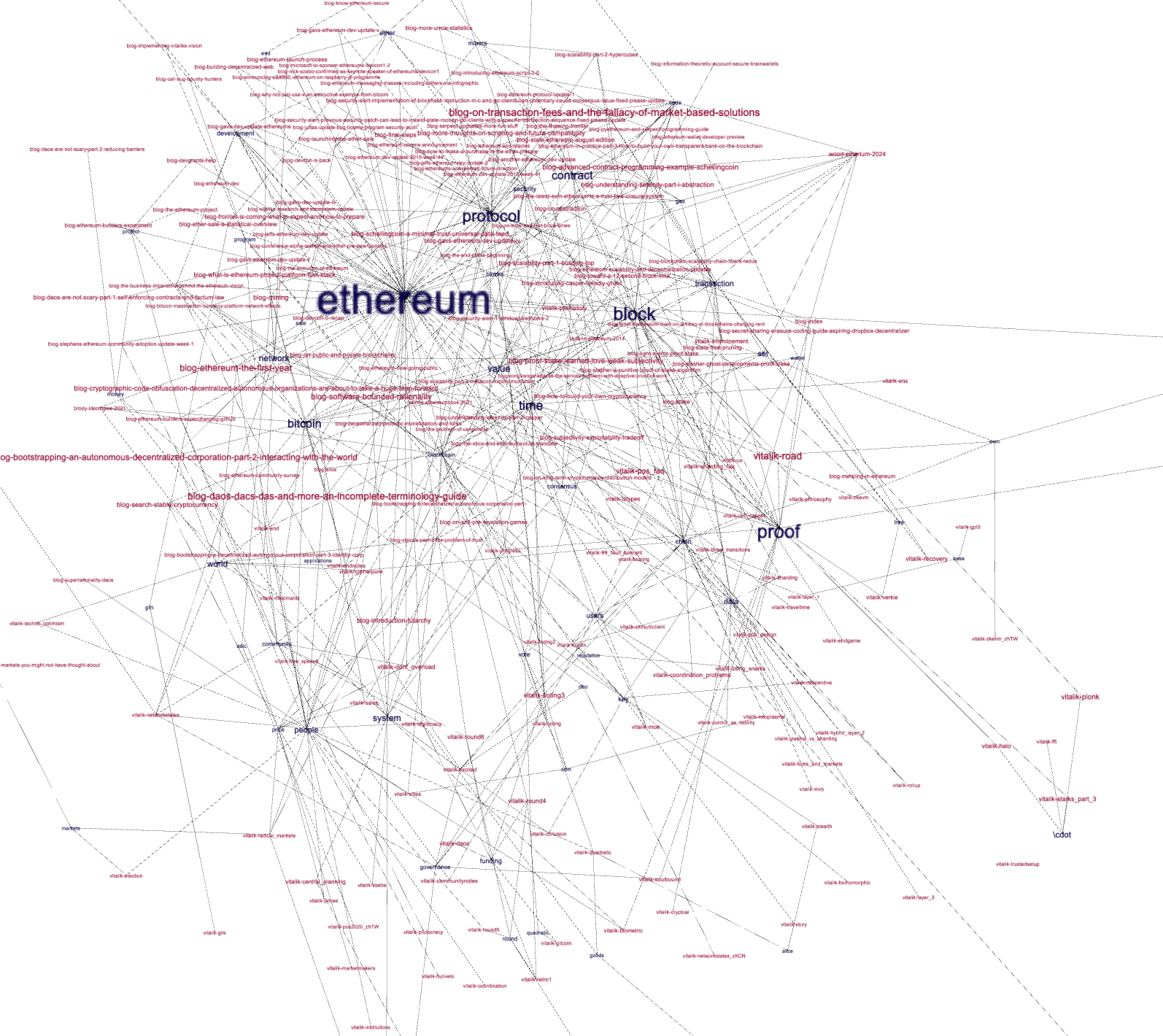 betweenesses |
A data set of about 270 items was created from writtings of the Etherium/Blockchain community. The sum size of the data set is similar to the size of the Bible and it is about things such as "etherium", "protocols", "bitcoin", "proof", "data", and "people". For more detail, see the computed summary page.
The whole of this data set ought to be downloadable at http://carrels.distantreader.org/curated-blockchain_discussions-other/index.zip.
This data set was created using a tool called the Distant Reader Toolbox, and the whole of the data set ought to be available for downloading at http://carrels.distantreader.org/curated-blockchain_discussions-other/index.zip.
Eric Lease Morgan <emorgan@nd.edu>
Navari Family Center for Digital Scholarship
University of Notre Dame
November 24, 2024