Code4Lib Journal
Lots o' project reporting and community building
This is a reading of Code4Lib Journal. To do this reading, I used wget to cache the whole of the Journal. I then used a script of my own design -- feeds2csv.py -- to loop through all the feed files found in the cache. For each feed file I extracted rudimentary bibliographic data (title, dates, and canonical URLs) for the purposes of creating a metadata file amenable to my Distant Reader system. In the end a Distant Reader study carrel ("data set") was created. All of the analysis was subsequently done against this study carrel. By the way, in the process, the metadata file got saved as the index.csv file.
Size and Scope
This data set includes just less than 600 items (articles) for a total of 2.4 million words. Counts and frequencies of unigrams, bigrams, and computed keywords (sans stop words) are visualized below. Ask yourself, "To what degree is this corpus large, and what is this corpus about?
 unigrams |
 bigrams |
 keywords |
The keywords and their association with items can be modeled as a network graph. More expressive and more nuanced than rudimentary word clouds, the visualization not only echoes the frequency of keywords but also their proximity to other keywords. In other words, when a document was about "web" is was likely to also be about "project". I applied modularity to the network to create "neighborhoods" of keywords nodes. Keywords sharing the same colored edges are neighbors.
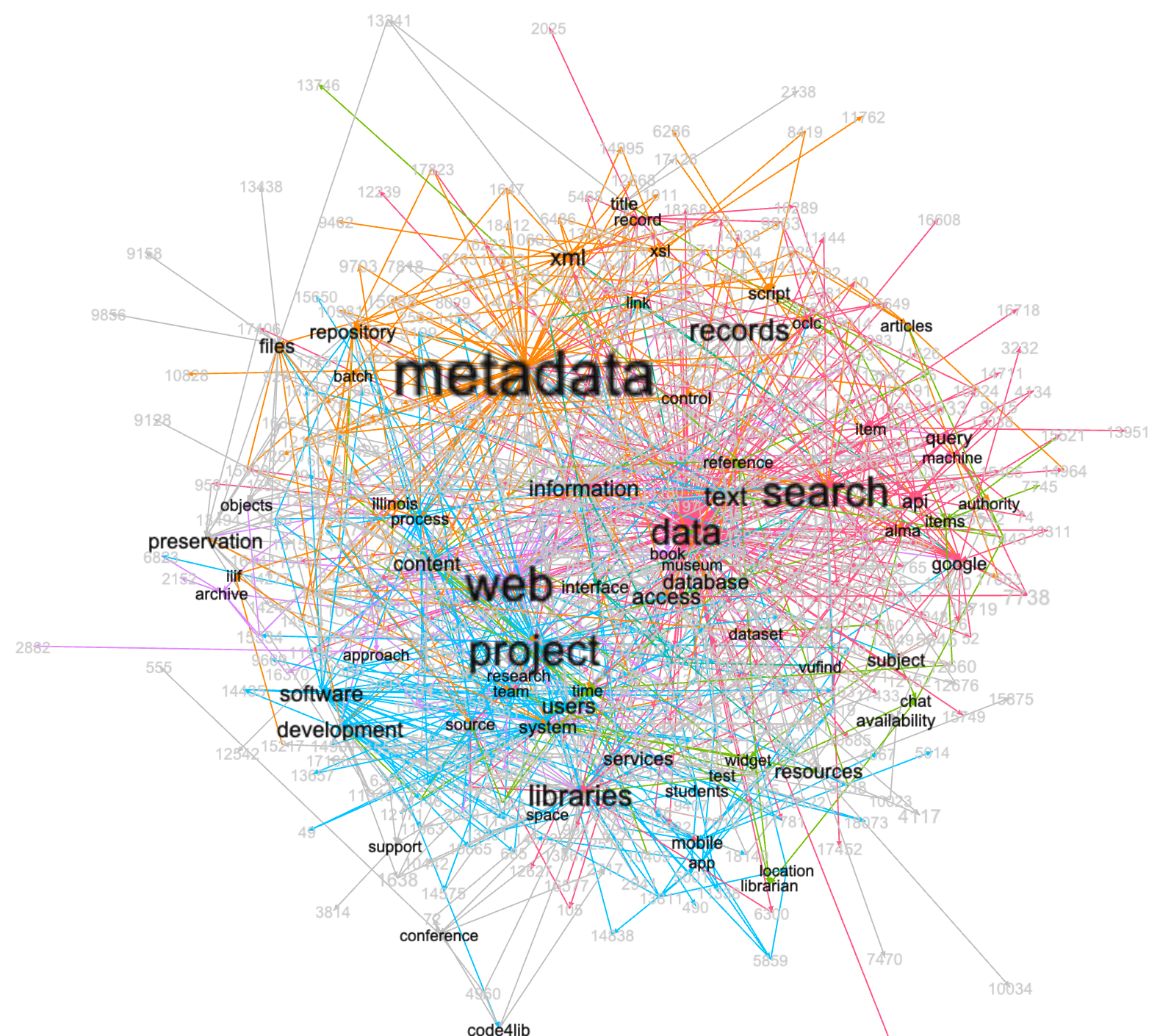
network of keywords and articles
I then searched the underlying relational database for articles whose keywords were "metadata" and "project". The following are the most relevant eight articles returned:
- Mdmap: A Tool for Metadata Collection and Matching
- Improving the presentation of library data using FRBR and Linked data
- Advancing ARKs in the Historical Ontology Space
- Communicat: The Next Generation Catalog That Almost Was…
- Implementing a Collaborative Workflow for Metadata Analysis, Quality Improvement, and Mapping
- An XML-Based Migration from Digital Commons to Open Journal Systems
- Distributed Version Control and Library Metadata
- Python, Google Sheets, and the Thesaurus for Graphic Materials for Efficient Metadata Project Workflows
Based on my professional judgement, I topic modeled the collection for a dozen topics. (See the dendrogram.) The results echo the word clouds and network analysis. ("Whew!"), but they are not exact, and that is okay because different modeling techniques produce different results, just as different people will summarize different documents differently. Thus, the collection may be about: project, code, search, etc. But be forewarned. The topics labels (i.e. project) ought to be read like the hyphenated word "project-system-development-work-users-process-time-software-libraries-services-data-systems". Topics are not denoted by a single word but a list of words.
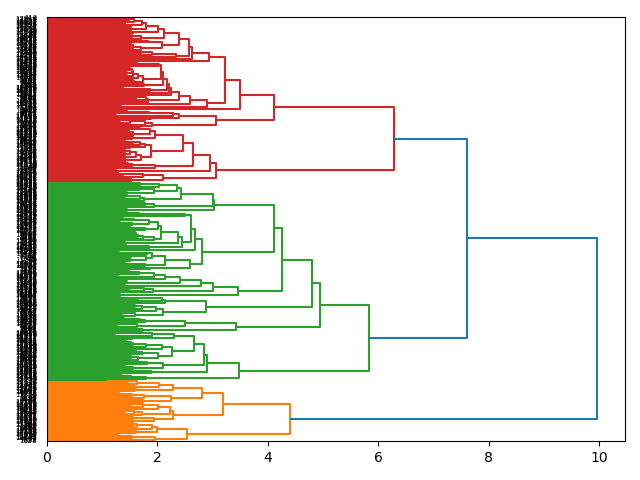{kind=link}
| labels | weights | features |
|---|---|---|
| project | 0.80364 | project system development work users process time software libraries services data systems |
| code | 0.25247 | code libraries work community editorial people articles technology source time software authors |
| search | 0.1771 | search data results query information users api google discovery database result searches |
| records | 0.17556 | records record data marc field script title metadata fields code name process |
| content | 0.14595 | content web libraries google site html link code links pages item website |
| collections | 0.09145 | collections metadata archival web content archives islandora images objects information description archive |
| metadata | 0.08229 | metadata data repository object objects xml name type access fedora files identifier |
| mobile | 0.08018 | mobile app students web location reference devices information application map computer system |
| data | 0.07648 | data name metadata model marc records work information rdf bibliographic web frbr |
| text | 0.06973 | text data word words model analysis results terms models language research dataset |
| api | 0.06763 | api data code web request services form information xml link server name |
| files | 0.06299 | files video preservation format disk images media storage data audio content version |
Since each topic is associated with a weight denoting the size of the topic compared to the whole, the topics can be visualized as a pie chart, and from the result we can see two of the twelve topics make up half of the weights. Thus, I assert, a great deal of the Journal is dedicated to the reporting on projects. Since each article has been associated with a date, the underlying topic model augmented with date values and pivoted accordingly. Once done a line chart illustrating how the more common topics ebbed and flowed over time can be produced. The result elaborates on the previous observations. Projects are a consistent and dominant theme.
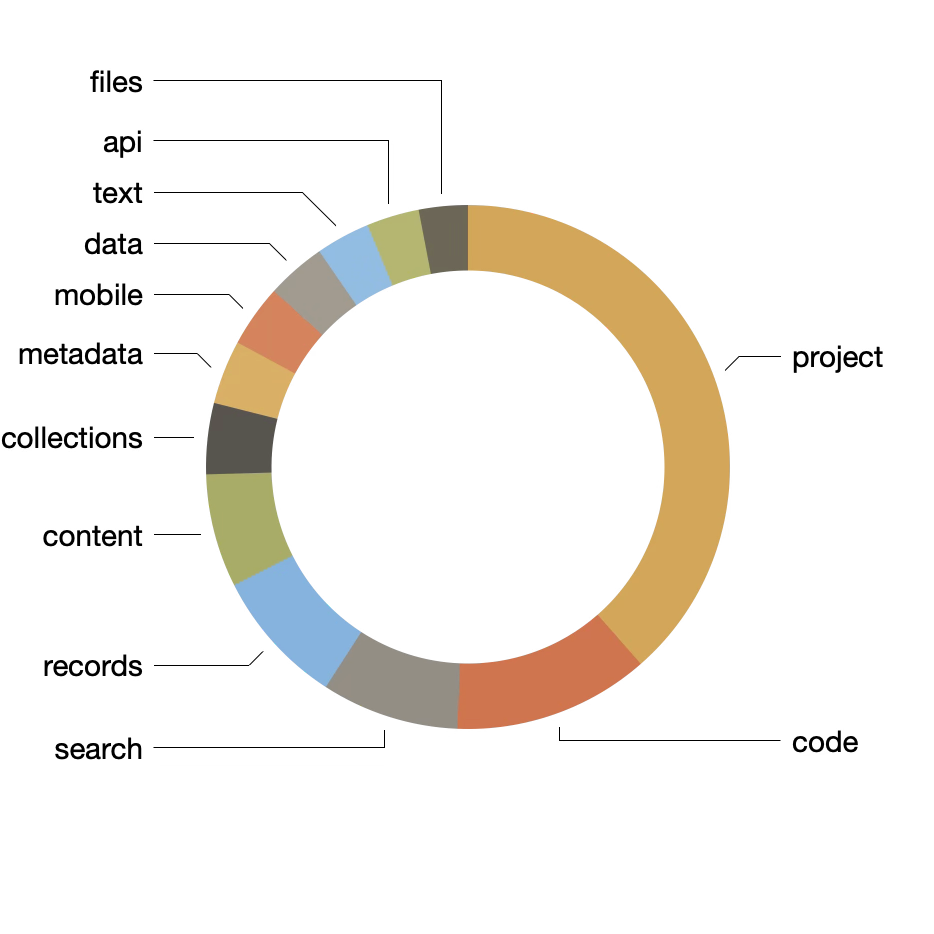 topics |
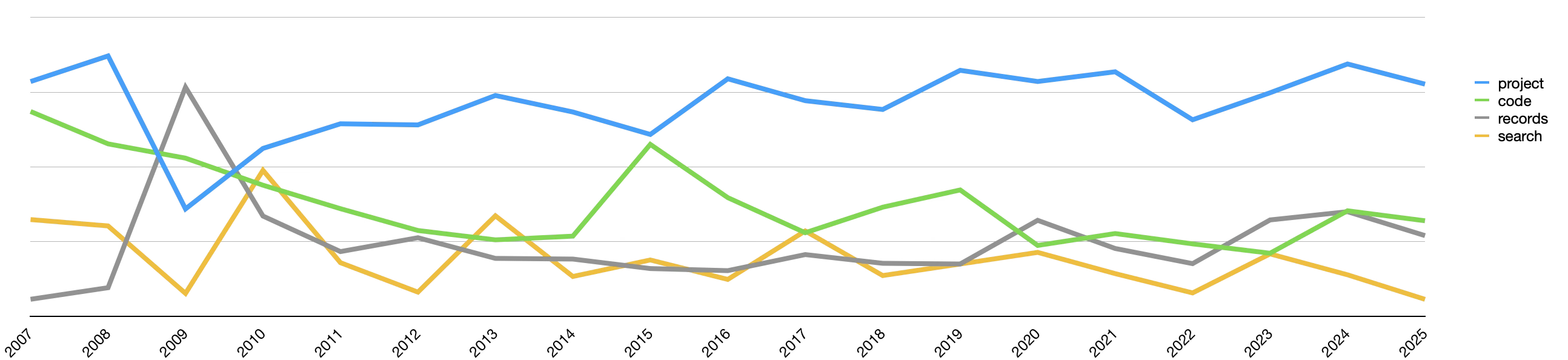 topics over time |
I then reverse-engineed the underlying topic model to list the eight most-significant articles associaed with the "project" topic. The result is both similar and different from the result of the keyword extraction process.
- ./cache/14260.html
- ./cache/15250.html
- ./cache/685.html
- ./cache/17857.html
- ./cache/561.html
- ./cache/8652.html
- ./cache/17766.html
- ./cache/2510.html
Eric Lease Morgan <eric_morgan@infomotions.com>
Infomotions, LLC
November 15, 2025