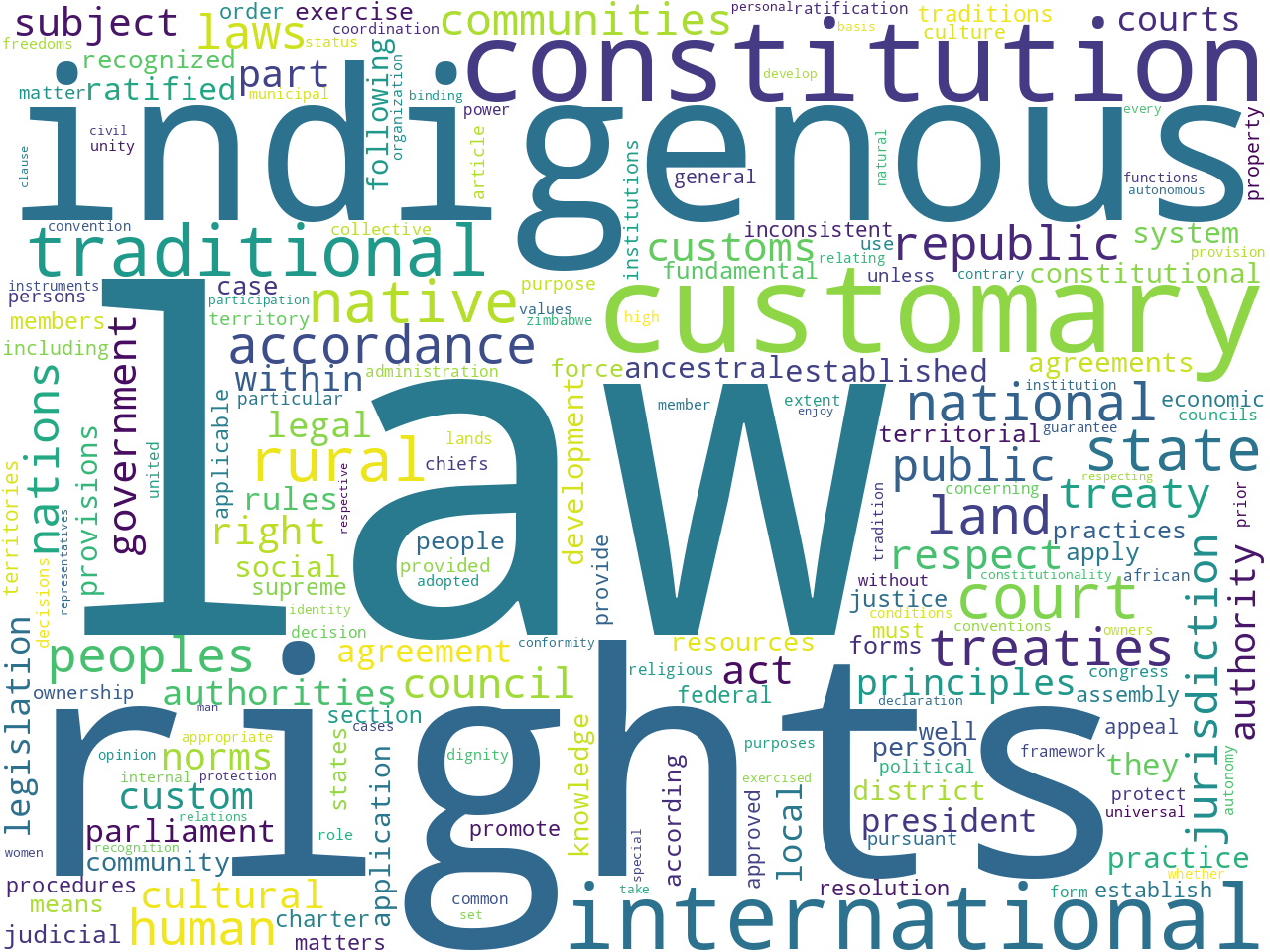
extracted features: unigrams
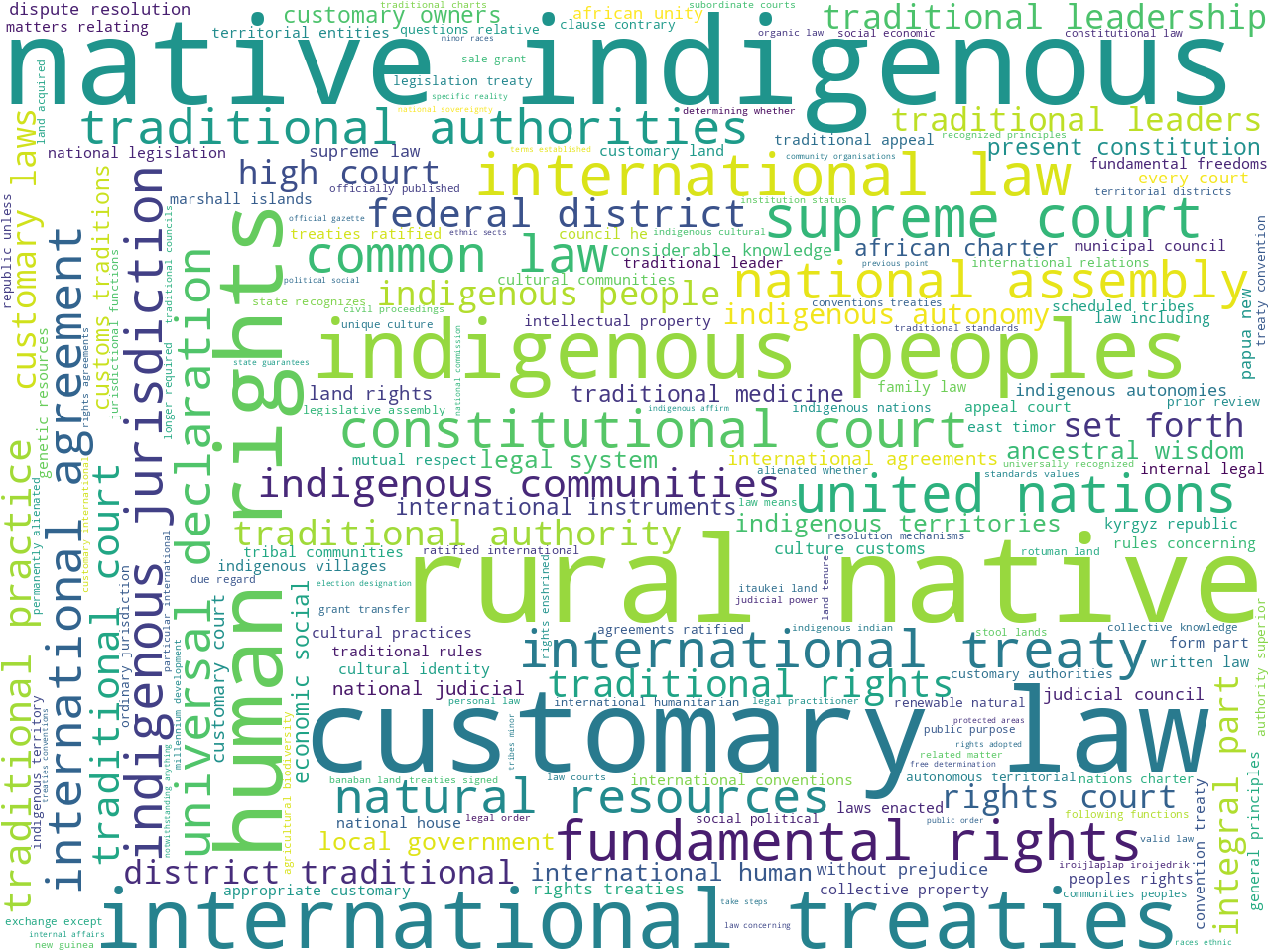
extracted features: bigrams
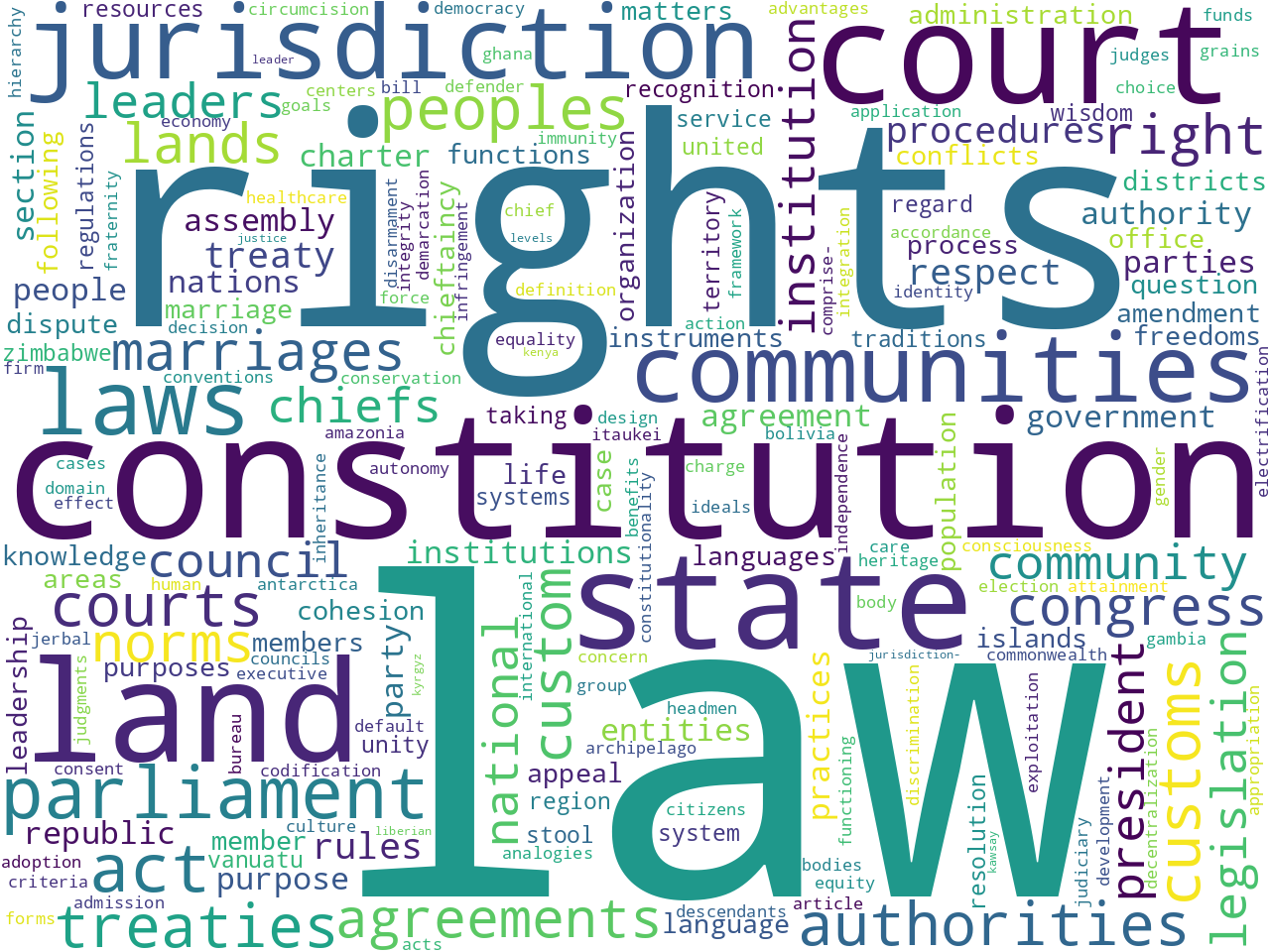
extracted features: keywords
Christina Bambrick and Emilia Justyna Powell came to me and asked, "Can you help us compare and contrast international and customary provisions in world constitutions?" I said, "Sure", and this page: 1) documents how we did the work, and 2) highlights some of our observations.
The work began by harvesting a complete set of world constitutions from a site called Constitute. More specifically, a list of URL's pointing to each world constitution was scraped from Constitute's directory. Of the result, only URL's ending in .pdf were retained. Every other URL was removed. The .pdf extension of each URL was then replaced with .xml resulting in a list of 204 URL's pointing to XML versions of world constitutions. We then used a program called wget to locally cache each constitution.
The next step was to transform the XML versions of the constitutions into plain text versions. This was done with a Perl script of our own design -- ./bin/xml2txt.pl. After running the script we now had a directory of .txt files. Each file was the plain text version of a world constitution, and the plain text is head-and-shoulders easier to compute against than PDF or HTML versions of the same.
The third step was to parse each constitution into "provisions", where a provision was loosely defined as a sentence. This was done with a Python script -- ./bin/files2sheets.py. The result of running the script was a comma-separated values file with five columns (label, length, classification, type, and paragraph) and more than 56,000 rows.
The fourth and last step in the corpus creation/curation process was to classify a subset of the provisions. This was done by domain experts (Bambrick and Powell) who selected just less than 700 of the provisions and divided them into "categories" and "types". There were two different types of categories: 1) custom, and 2) international. There were four different types: 1) competitive, 2) cooperative, 3), complementary, and 4) combative. All of of our subsequent analysis was done against the resulting comma-separated values file, a file we call articles.csv.
In order to supplement our understanding of the data set, we first analyzed it terms of its extracted features, meaning, we visualized all sort of different characteristics of the data set. To do this work, we looped through the data set creating a file for each provision. (See ./bin/paragraphs2metadata.py.) We then used a tool called the Distant Reader to read the files, extract the features, count their frequencies, and visualize the results.
The whole of the extracted features analysis can be seen by perusing the Reader's computed summary page, but some of the more salient details are presented here. First, while there are as many as 56,000 sentences ("provisions") in the whole of world constitutions, we are only analyzing 680 of them because these were the only ones classified as being either custom or international. Second, excluding stop words, word clouds of unigrams and bigrams begin to illustrate the "aboutness" of these 680 provisions. Using an algorithm called Yake, the Reader computes a set of keywords more accurately describing the data set's aboutness. The results probably echo things already known about the provisions, but they also bring to light things unknown or more difficult to articulate:
extracted features: unigrams |
extracted features: bigrams |
extracted features: keywords |
Similar extracted features were visualized from the provisions classified as customary and international:
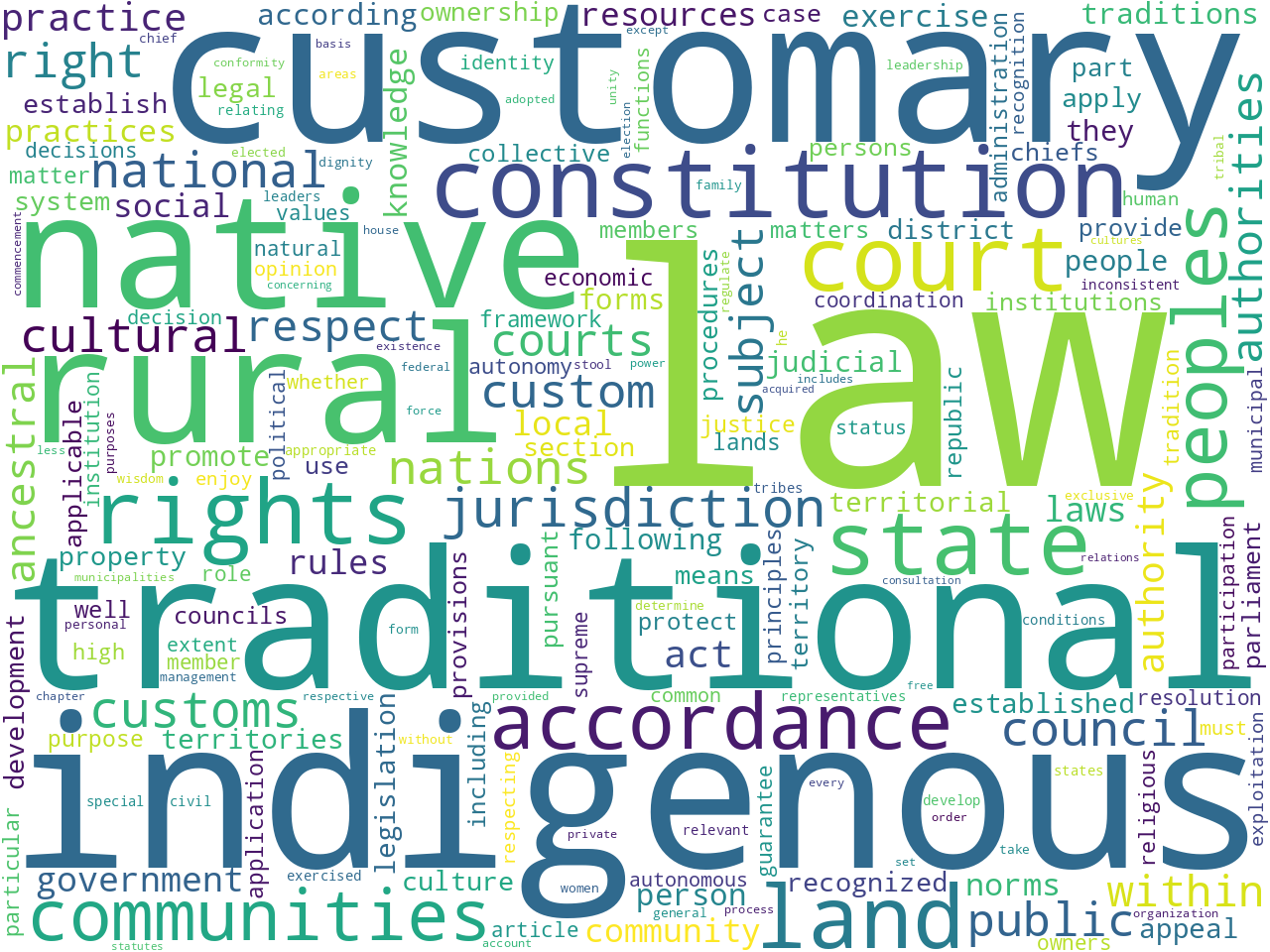 unigrams (customary) |
 bigrams (customary) |
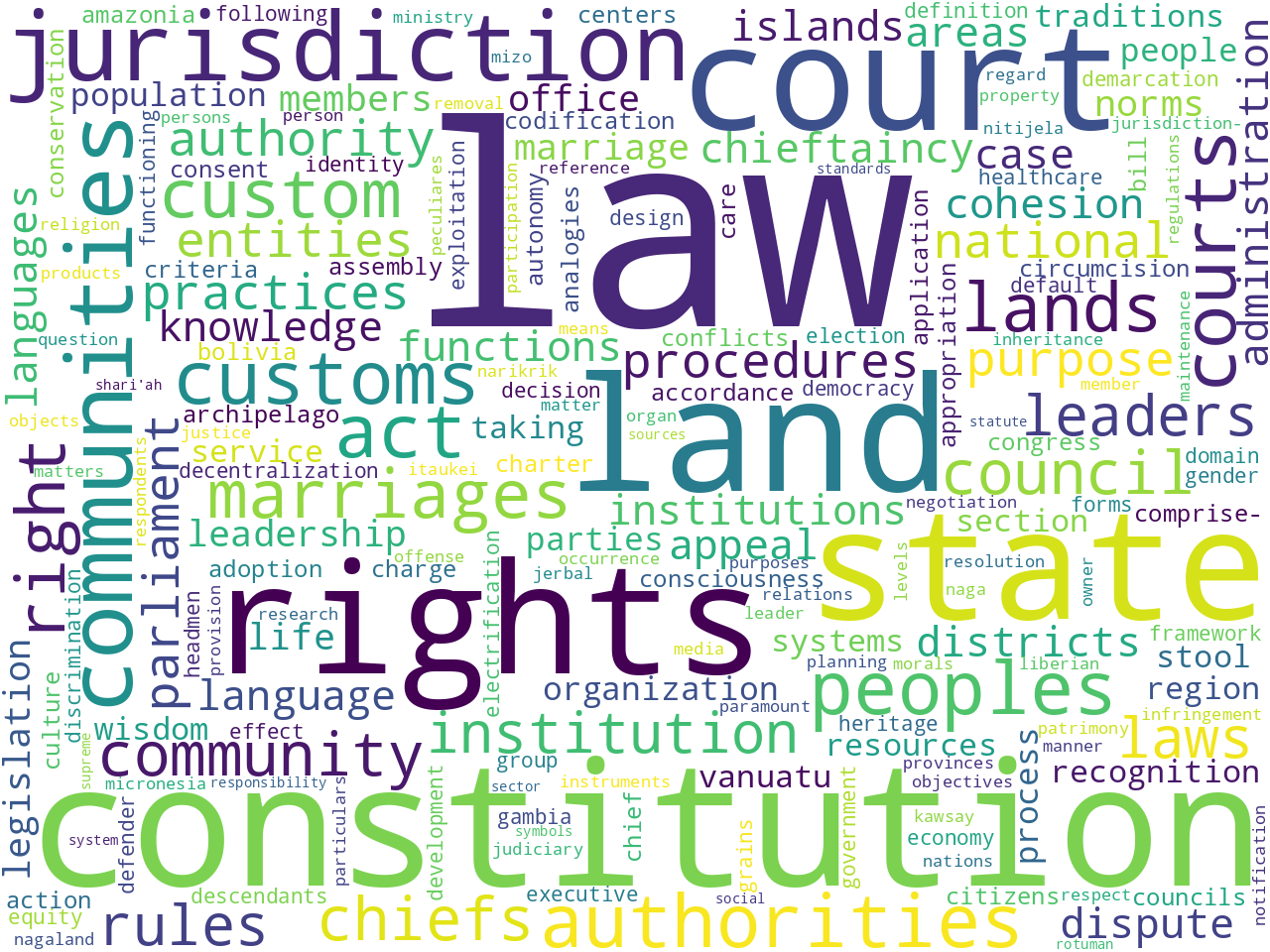 keywords (customary) |
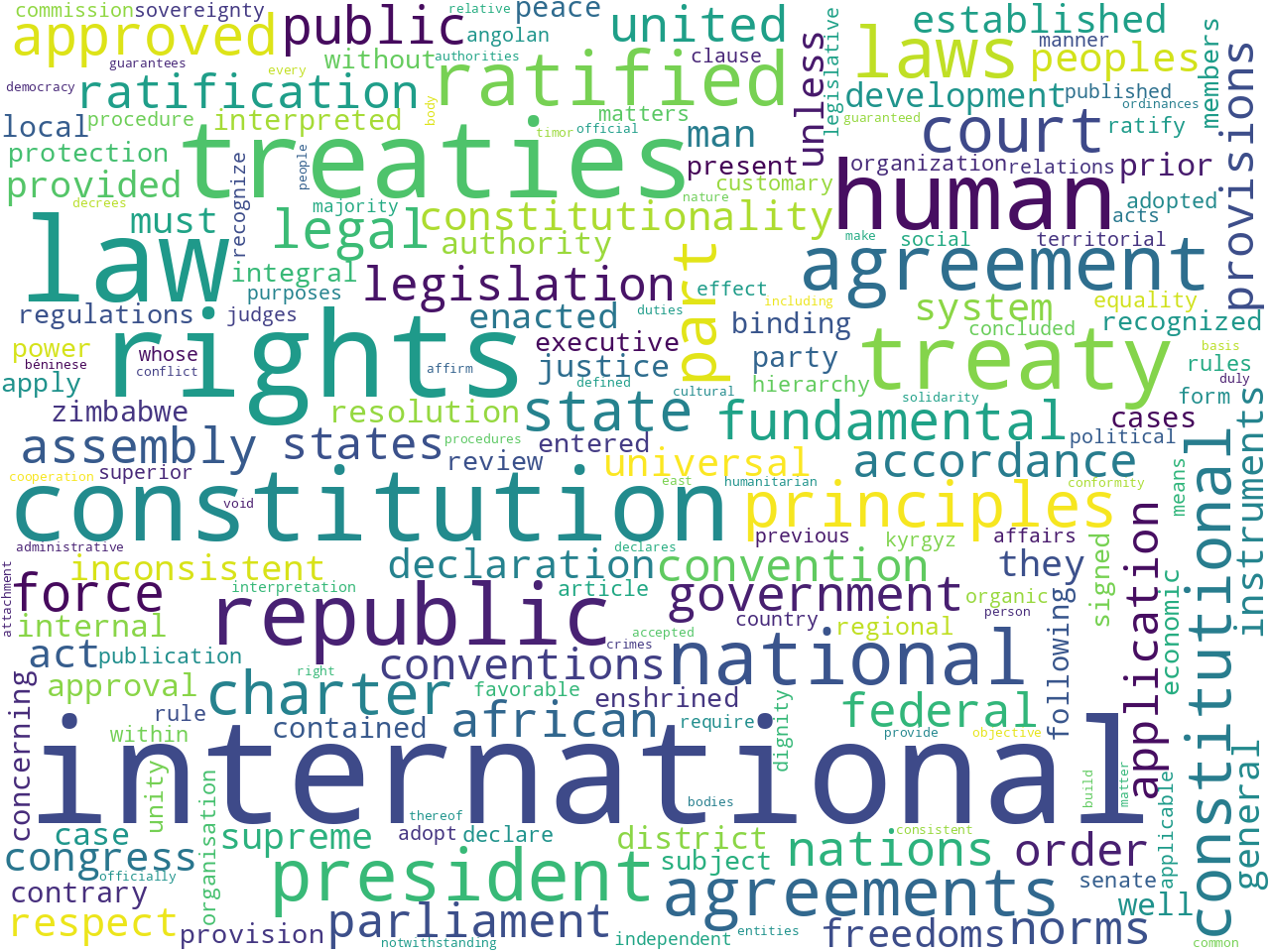 unigrams (international) |
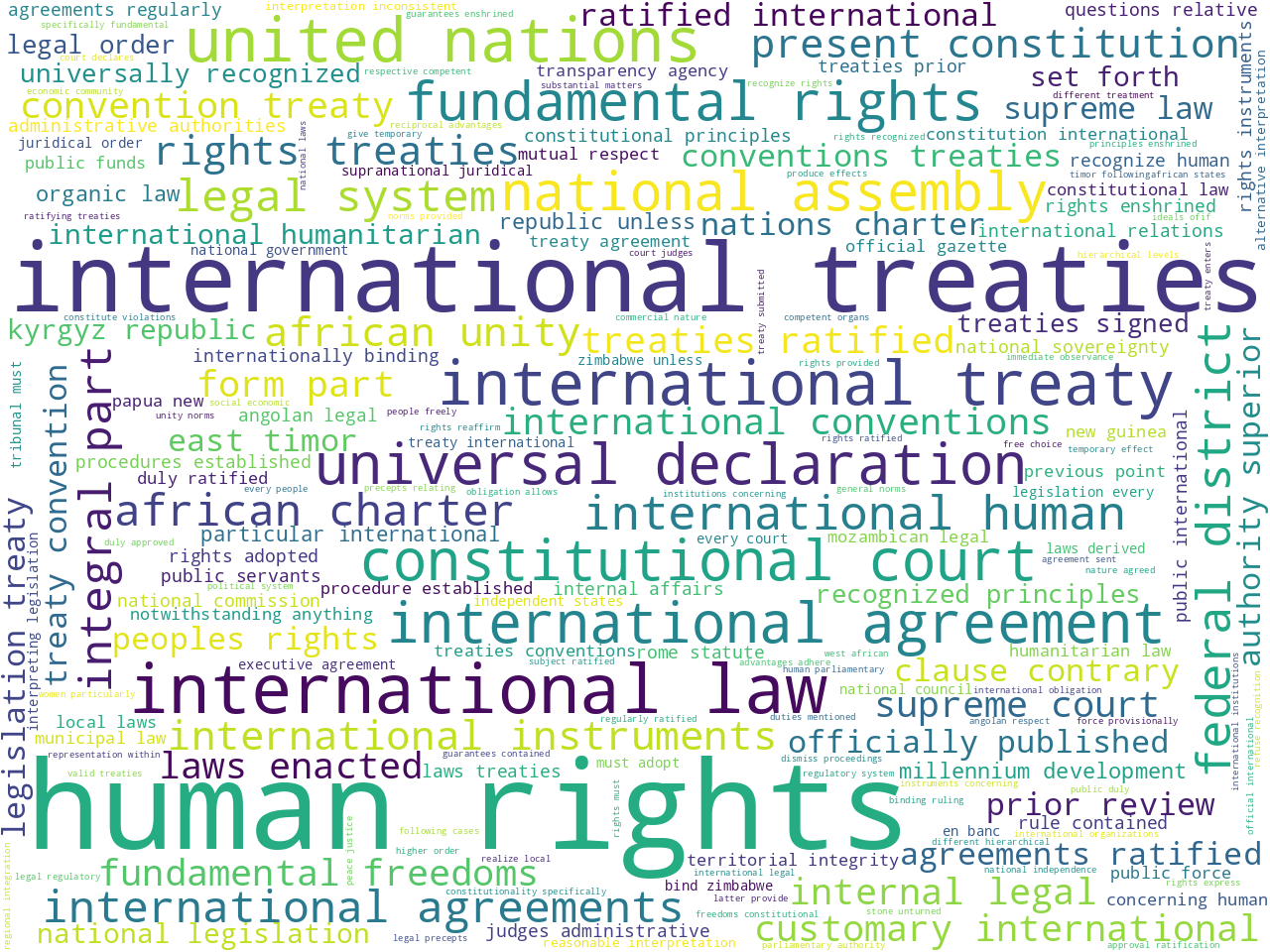 bigrams (international) |
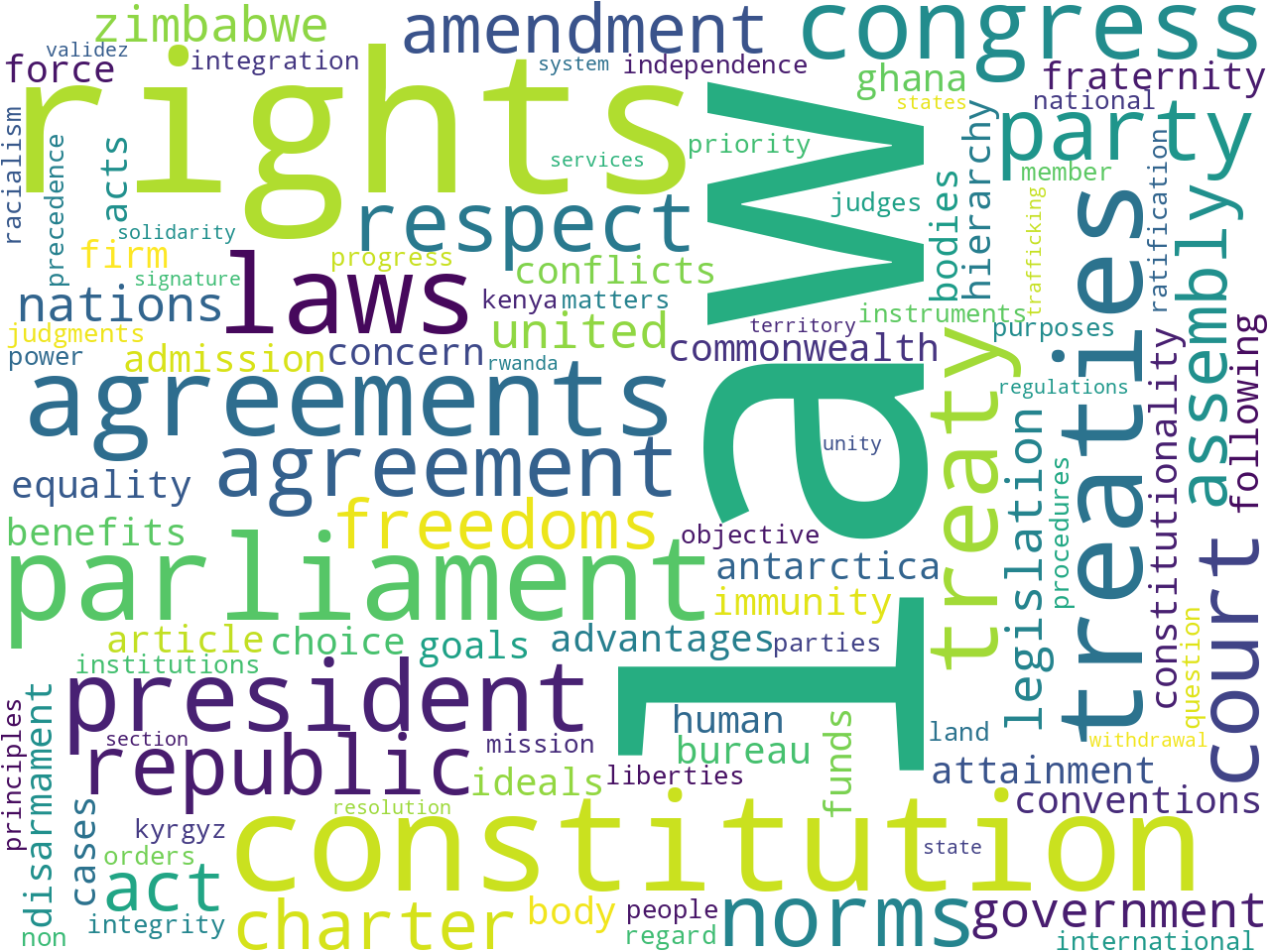 keywords (international) |
Based on these observations, the provisions as a whole seem to allude to rights and laws. When the only the customary or international provisions are observed, the difference are distinct. The former allude to customs, rural, indigenous, and land, while the later allude to treaties and human rights.
To further understand the aboutness of the selected provisions, we used a clustering technique called topic modeling. (The Reader supports topic modeling through a tool called MALLET, and MALLET implements topic modeling with an algorithm called Latent Dirichlet allocation.) More specifically, we clustered the provisions into six topics, and we visualized the result as a pie chart. Thus, we assert more than half of the data set is about "international", "indigenous", and "law". Reassuringly, these labels echo themes identified from the extracted features:
| labels | weights | percentages | features |
|---|---|---|---|
| law | 0.07418 | 21% | law court customary traditional constitution courts act parliament custom land |
| indigenous | 0.06889 | 20% | indigenous rural native peoples law jurisdiction nations constitution communities rights |
| traditional | 0.06794 | 19% | law traditional customary land state constitution council government accordance local |
| international | 0.05722 | 16% | international treaties treaty constitution republic laws agreement law president national |
| customs | 0.0416 | 12% | customs ancestral state knowledge traditions practices lands public culture cultural |
| rights | 0.03973 | 11% | rights human international constitution charter fundamental principles law nations united |
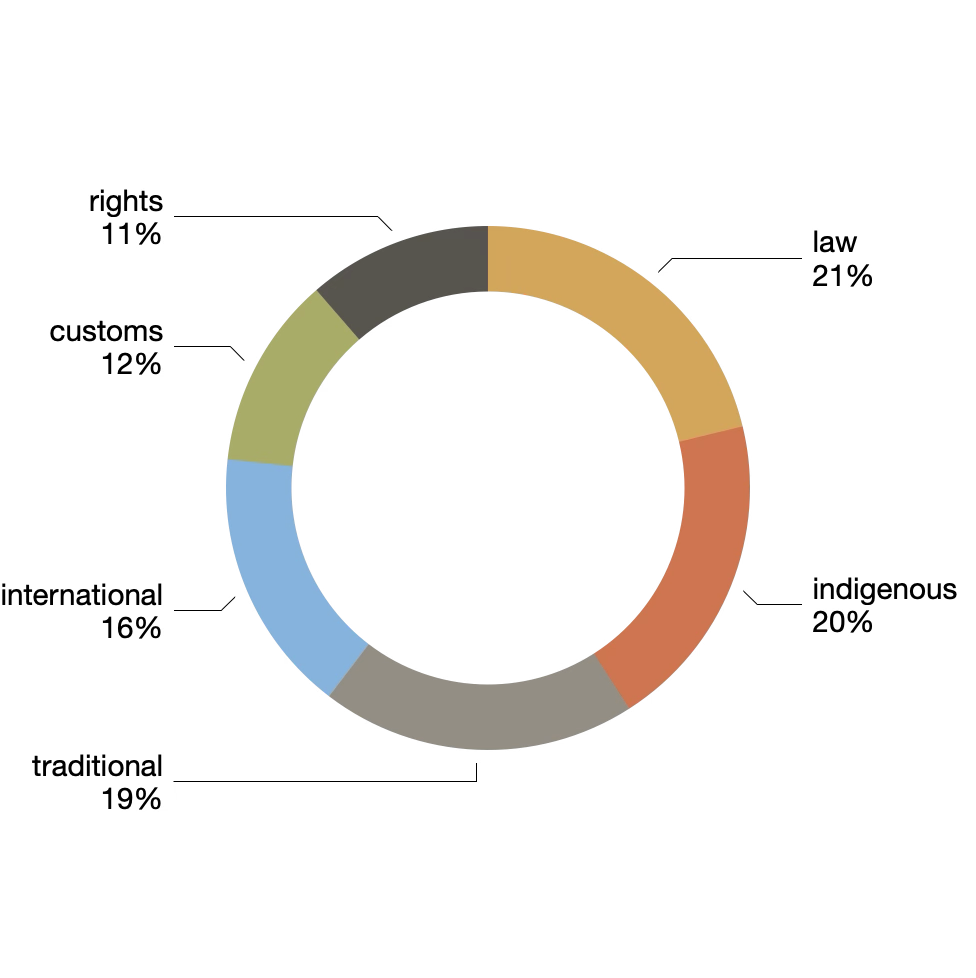
As a sort of reality check, we looped through each of our provisions, identified the most significant topic associated with it, and augmented our list of provisions with the computed topic labels. (See ./etc/articles-augmented.csv.) From the result we can see how some of the provisions have been classified:
In order to observe the degree each topic is associated with the given provisions, we augmented the underlying topic model with our classification values (categories and types), pivoted the model, and visualized the result. There are distinct differences within the visualizations. For example, when it comes to the provisions classified as custom or international, the international provisions weight heavily on the "international" topic, while the custom provisions are more evenly balanced. Similarly, when the computed topics are compared to types, the combative and competitive provisions complement each other while the complementary and cooperative provisions are balanced. See below:
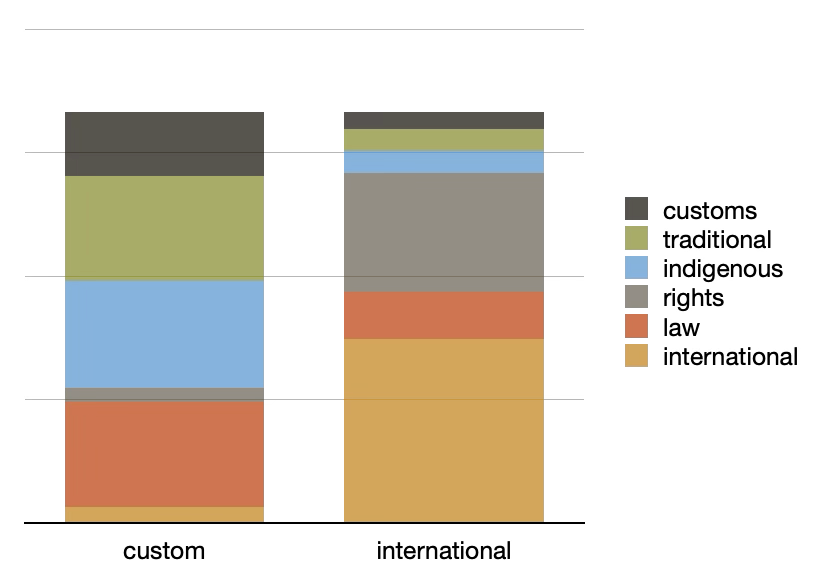 |
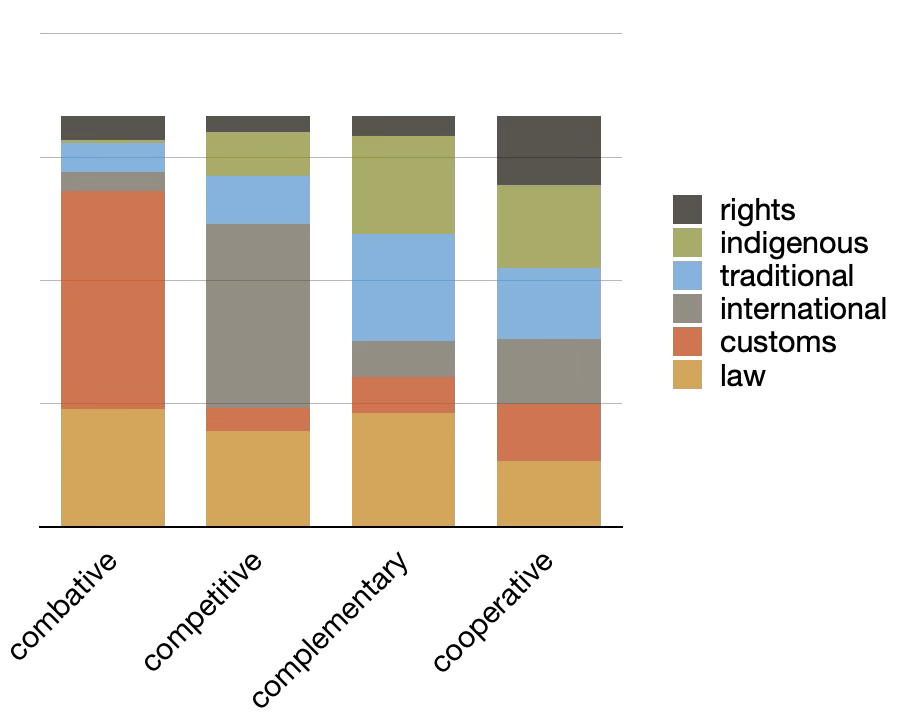 |
In short:
We then wanted to see what sorts of latent themes may be identified within the provisions classified as custom or international. Consequently, we applied a similar topic modeling process to each of them.
After topic modeling the custom provisions using six topics, we might say the custom provisions are about "customary law", "indigenous communities", and "customary practices". After we augment the model with types (combative, competitive, etc.) metadata, and after we pivot the table, we can see each set of types of provision are very similar with the exception of combative provisions. The combative provisions within the custom provisions emphasize customary practices.
| labels | weights | percentages | features |
|---|---|---|---|
| customary law-state law relations | 0.11416 | 31% | law customary traditional constitution custom rules local parliament chiefs state |
| indigenous communities | 0.10009 | 27% | indigenous rural native peoples law constitution nations jurisdiction communities rights |
| customary law in courts | 0.049 | 13% | court law traditional customary courts council practice appeal judicial jurisdiction |
| customary practices | 0.03993 | 11% | customs rights traditions public practices women constitution promote states culture |
| ancestral knowledge | 0.03543 | 9% | knowledge cultural ancestral traditional wisdom communities protect practices state develop |
| land | 0.03469 | 9% | land lands state ownership owners property rights customary whether custom |
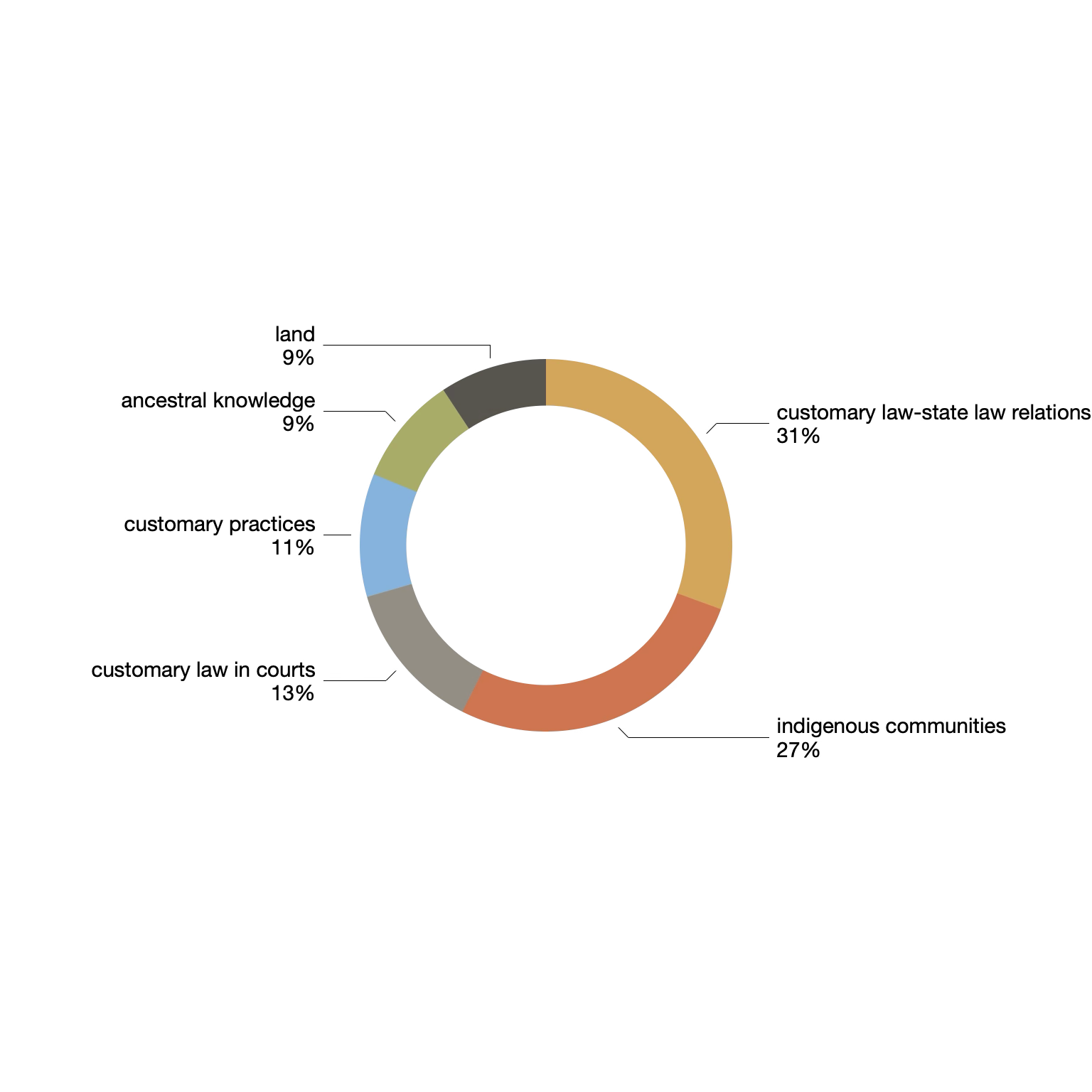 topics |
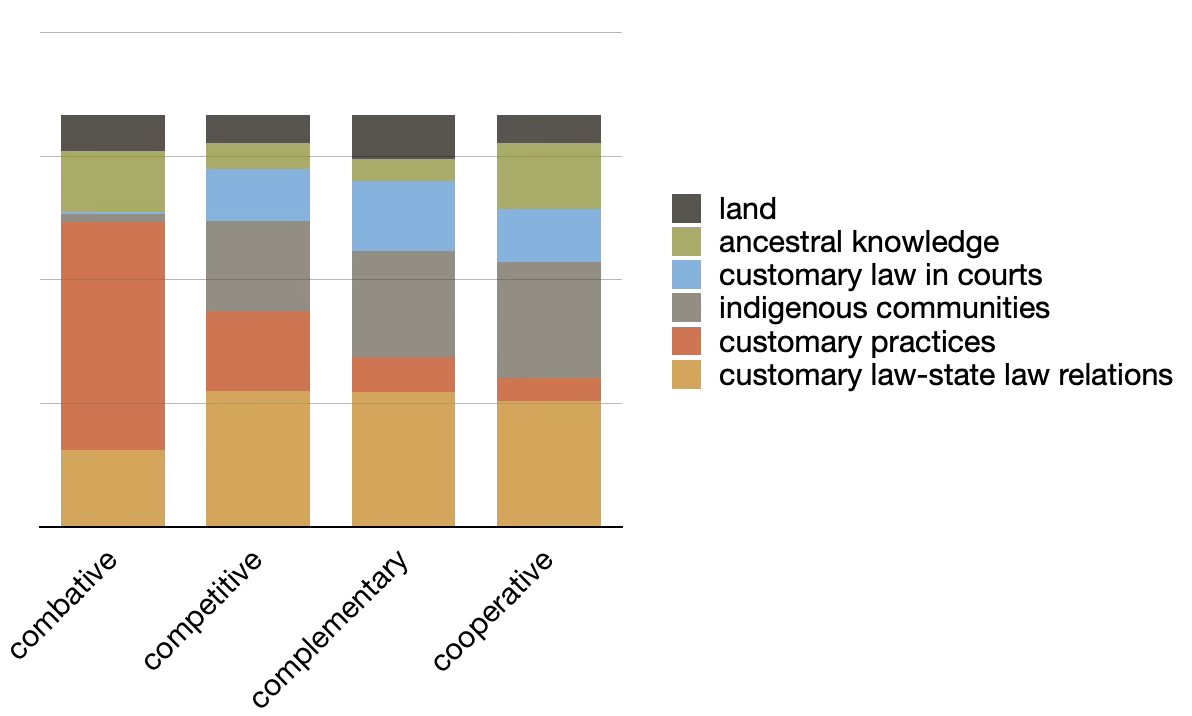 topics over types |
As per above, we augmented these custom provisions with the most significant computed topic for each, and we were able to garner a sort of reality check. For example, some of the label/provision combinations from the augmented file (../curated-constitutions_customary-2025/etc/articles-augmented.csv) include:
The same process was applied to the international provisions, and a different set of topics was produced. More importantly, when we augmented the model with the types metadata, we can see more distinct difference between the types. Competitive provisions emphasize the topic of "international treaty president", complementary provisions lean towards the them of "international norms", and cooperative provisions have a tendency towards the topic of "rights".
| labels | weights | percentages | features |
|---|---|---|---|
| international norms | 0.07358 | 24% | international law treaties legal force norms system agreements constitution laws |
| human rights | 0.06692 | 21% | rights human international constitution charter treaties ratified fundamental nations united |
| treaty status | 0.06425 | 21% | treaty president international republic treaties agreement court constitutional assembly national |
| legal conformity | 0.0566 | 18% | law parliament international constitution treaty agreement act unless convention part |
| human development | 0.03804 | 12% | development respect states justice public peace human equality affairs principles |
| multilevel relationships | 0.01356 | 4% | federal laws district national local enacted international senate state commission |
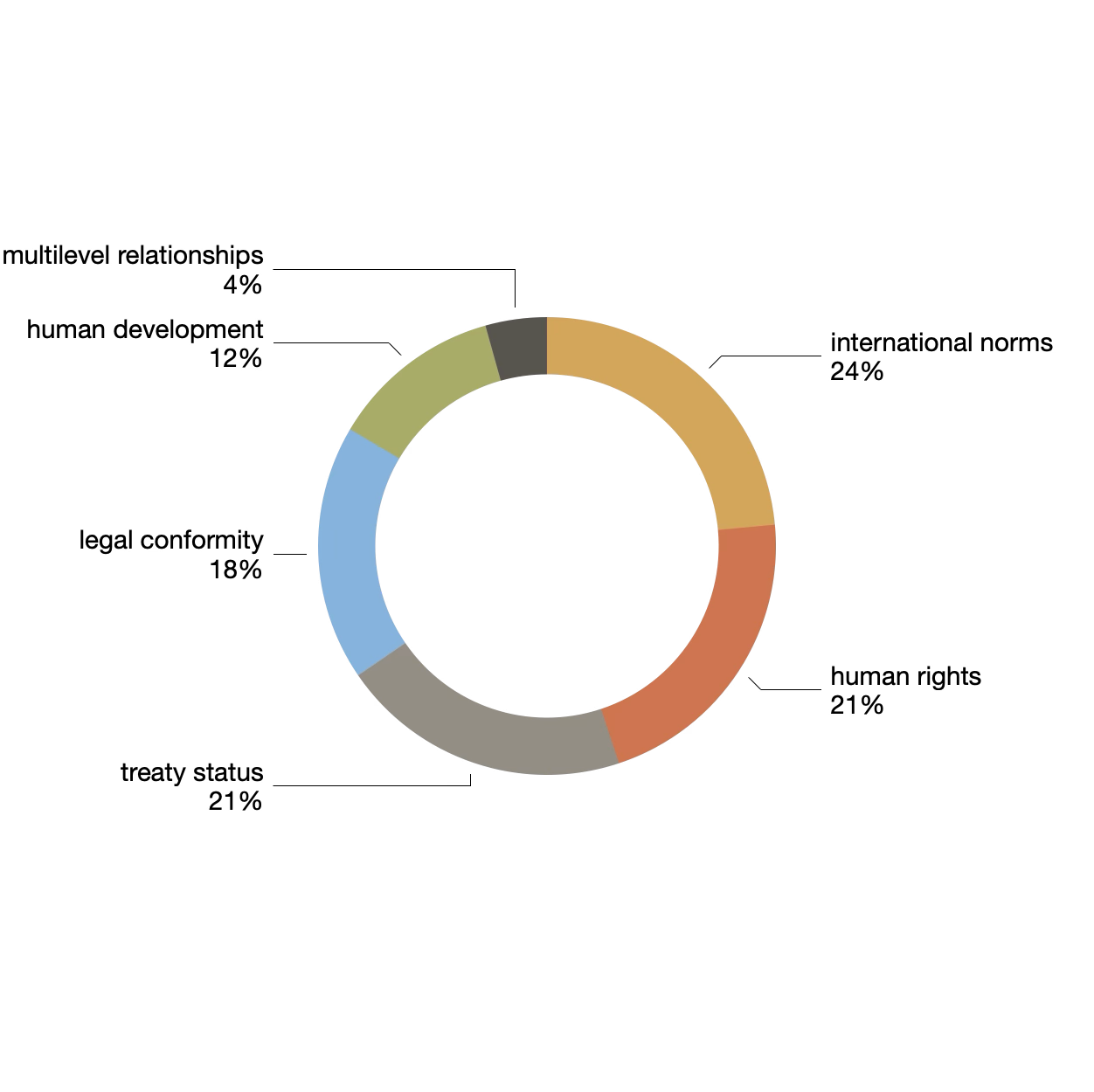 topics |
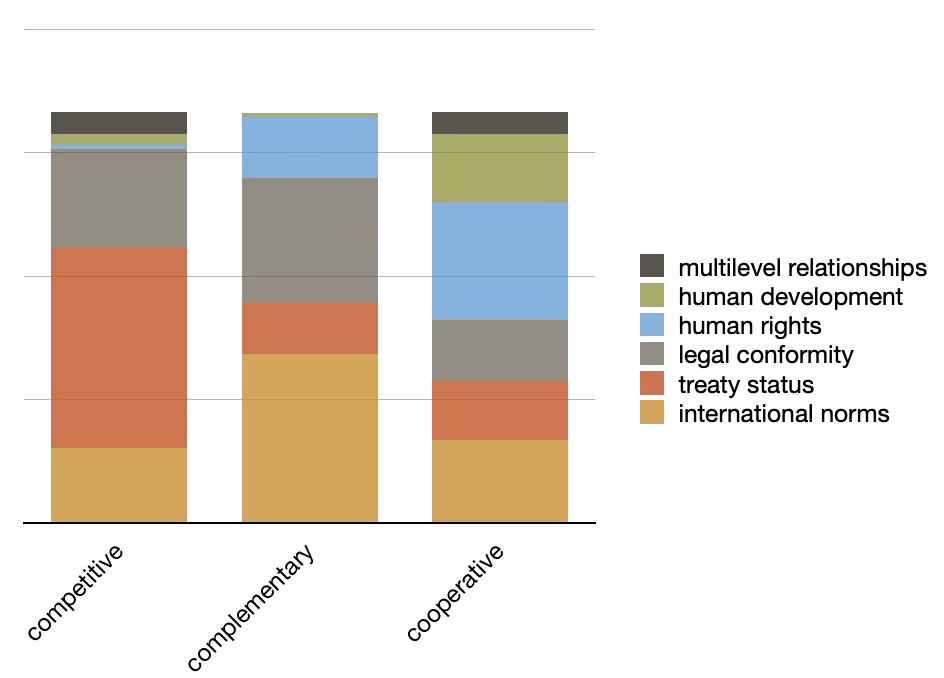 topics over types |
Provisions were previously classified into categories and types, and by extension, provisions are associated with countries. All of these things (provisions, categories, types, and countries) and their associations can be interpreted as the nodes and edges of a network graph. Using a Python script of our own design -- ./bin/paragraphs2graph.py -- such a network graph was created in the form of a graph modeling language file -- ./etc/paragraphs.gml. This file was imported into an application called Gephi and visualized.
A simple force-directed layout applied to the graph brings to light four or five distinct clusters, and after turning on the labels of each node we see things cluster around the complementary, custom, cooperative, combative, and international nodes. Note also how the opposed classifications (custom versus international and complementary versus cooperative) are relatively distant from each other. This highlights each classification's distinctiveness.
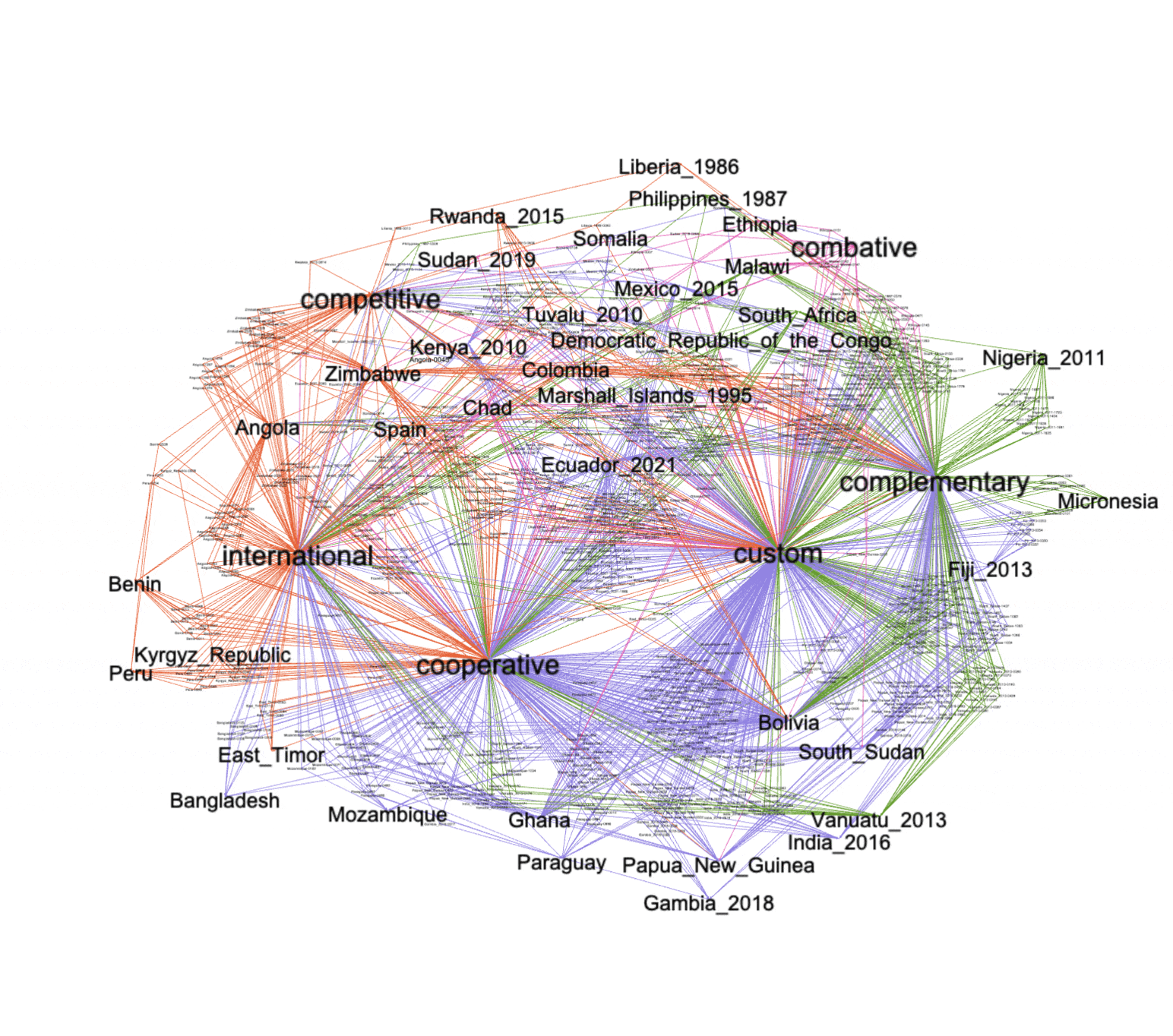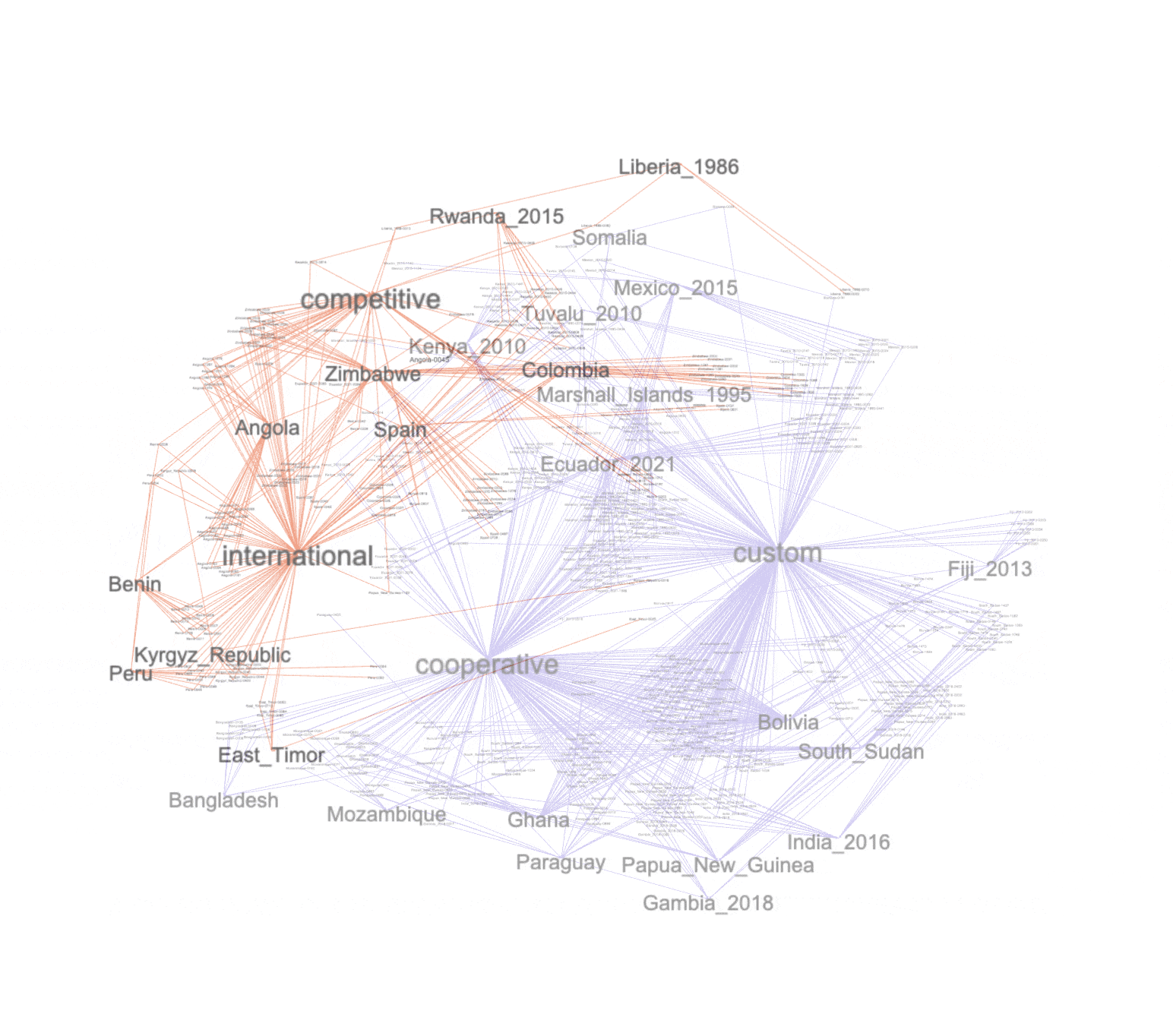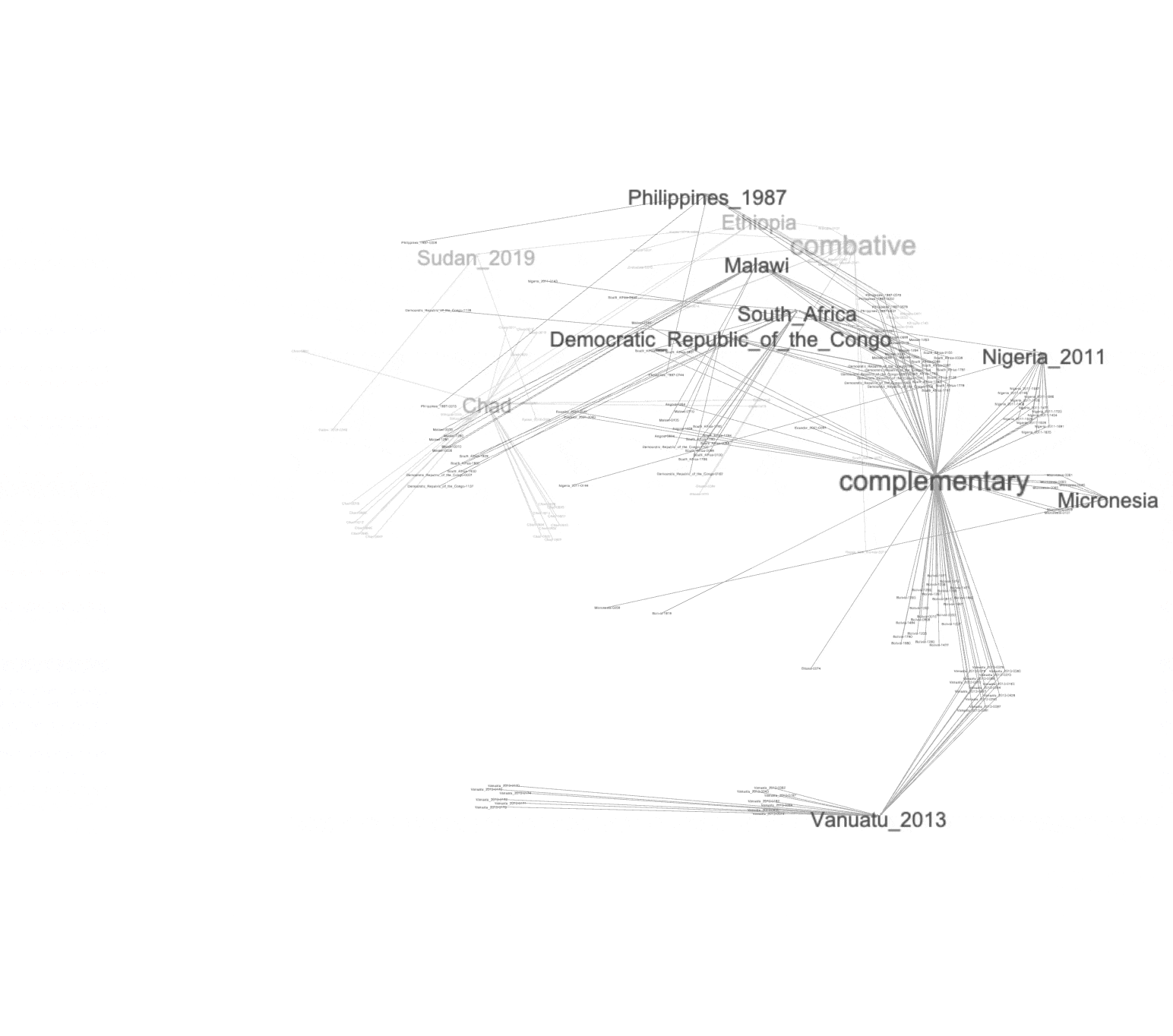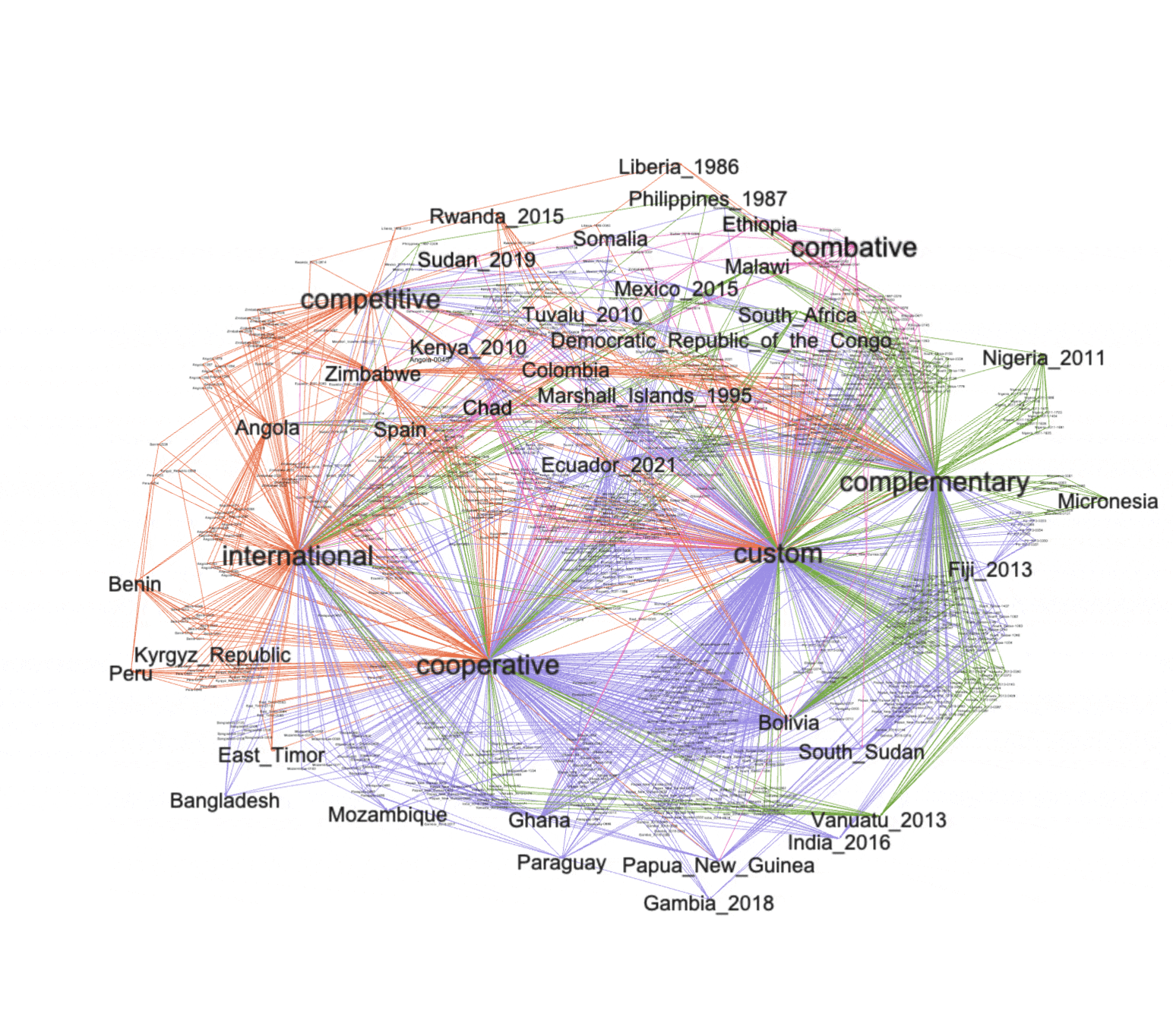 clusters |
 types, categories, and countries |
Network graphs are not laid out randomly. Instead, there is a method to their apparent madness. For example, a given node may be associated with many other nodes, and therefore the given node may appear to be more in the center of the graph; if a given node is connected to every other node, it will appear in the middle of the graph. Similarly, the number of edges ("relationships" or "associations") a given node has dictates the node's apparent size (or "label"). Furthermore, just like topic modeling, clustering can be applied to the network and thus "neighborhoods" can be calculated. These neighborhoods are computed by measuring the distances and interrelated-ness of the nodes.
With these things in mind, we can observe and conclude a number of things from the graphs:
Just like the topic modeling process, we can do network analysis against the two categories of provisions. To do this work we wrote a program -- ./bin/categories2edges.py -- to compute against our list of provisions and output edges tables (./etc/edges-custom.tsv and ./etc/edges-international.tsv). After laying out the edges as a force-directed graph, and adjusting the nodes' labels to reflect the number of in-degree edges, we can observe characteristics of different countries within the custom and internation provisions. For example:
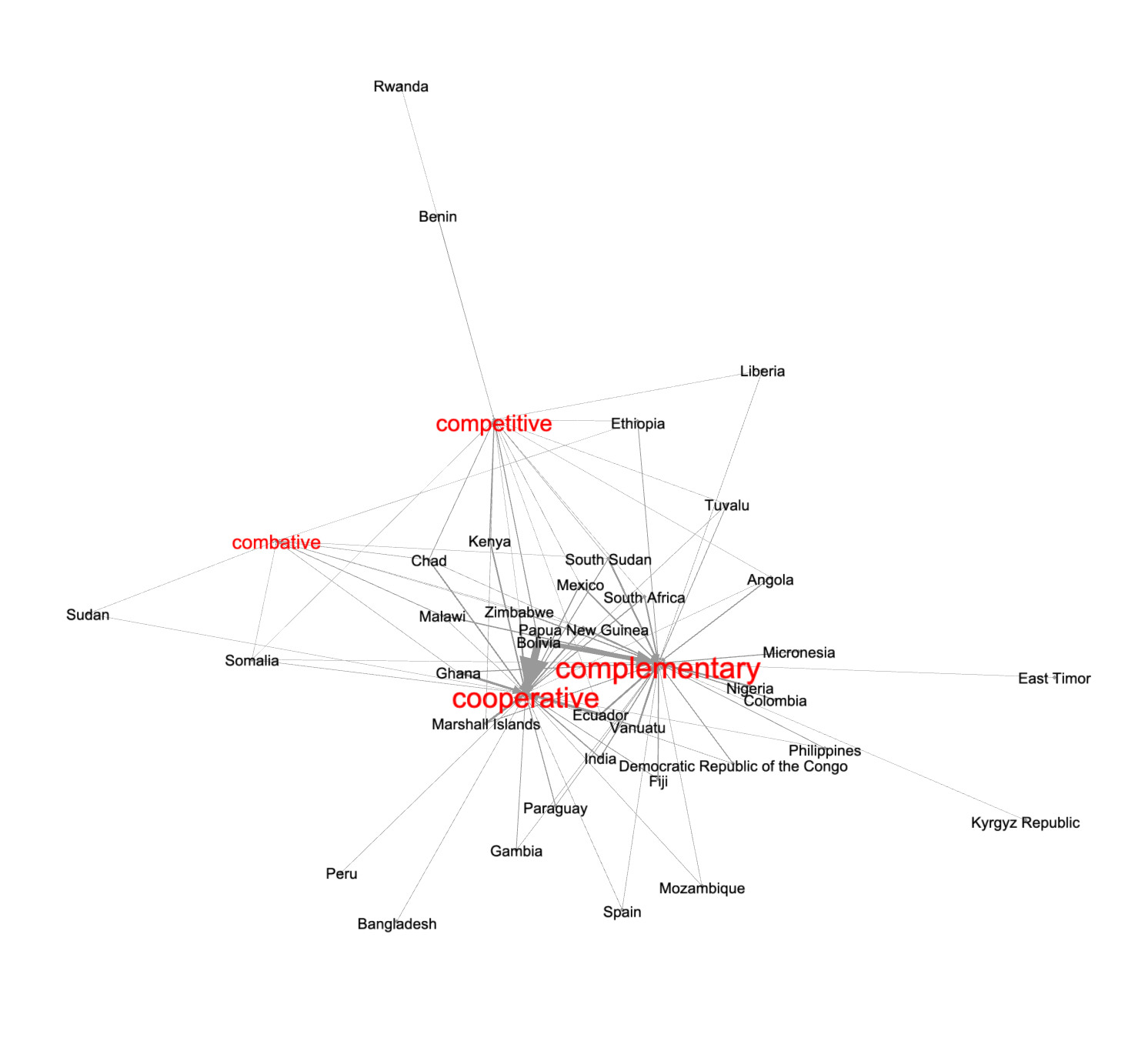 custom provisions |
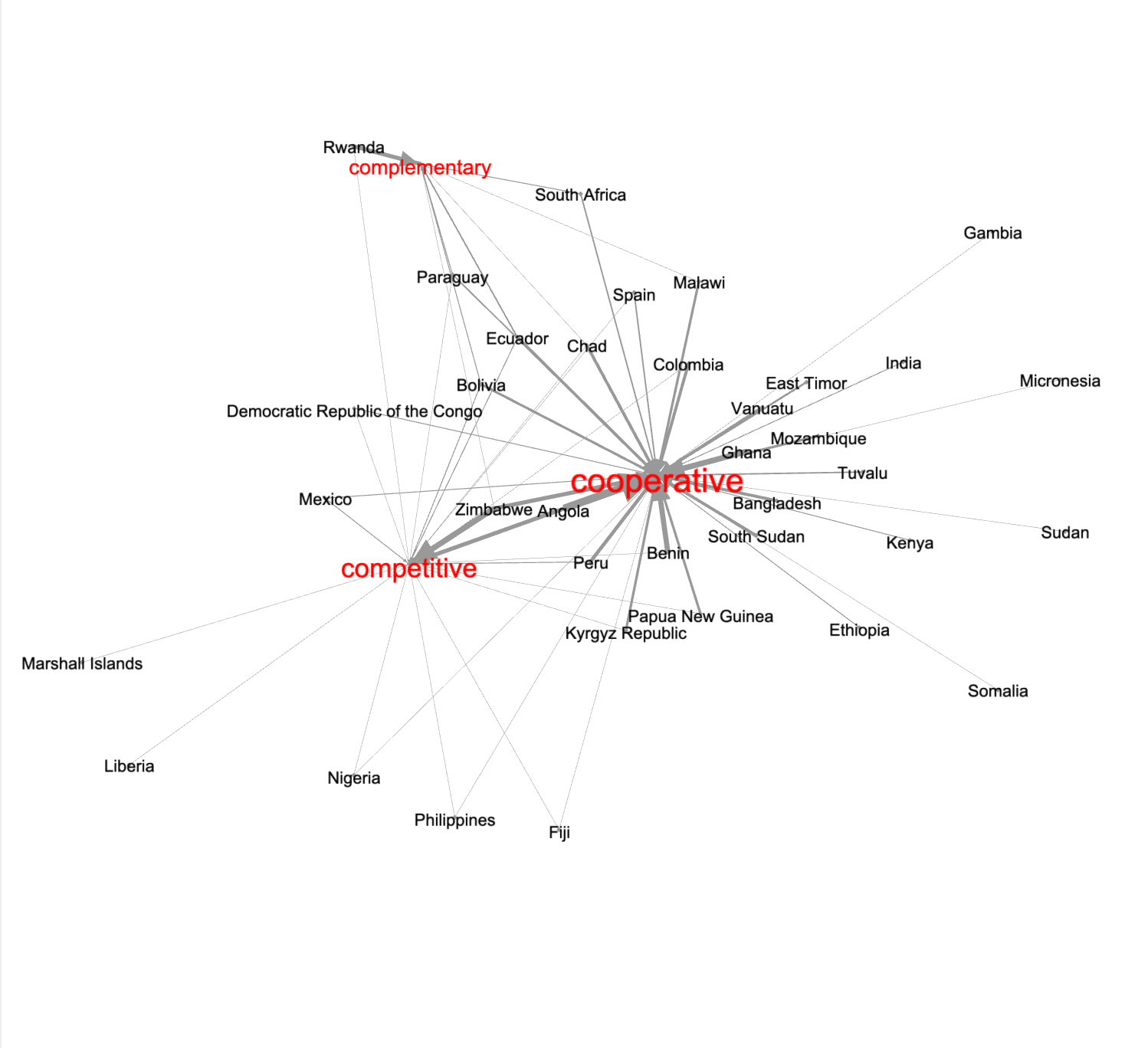 international provisions |
After presenting this analysis to Christina and Emilia, a number of questions presented themselves:
Question: In the process of preprocessing the text, were the words pruned which appeared less than a given number of times, and were the remaining words lemmatized?
Answer: The short answer is, "No." Zero words were eliminated because they occurred less a given number of times. Similarly, zero words were removed because they occurred more than a given number of times. On the other hand, there were a number of words eliminated from analysis because they were deemed useless. These words are called "stop words", and they can be found in the stop words file -- ./etc/stopwords.txt. While the lemmatization of words can lead to more nuanced analysis, it was not applied in this analysis. I do not believe the extra effort to use lemmatized words would lead to significant differences in the analysis.Question: Did you use the Natural Language Toolkit (NLTK) in the preprocessing?
Answer: The short answer is, "Yes, sort of." The venerable NLTK makes many natural language things easier, such as parsing a document into sentences or words. These processes are a part of the Distant Reader and were used in the network analysis. On the other hand, MALLET's topic modeling process uses regular expressions to parse text into words. At first glance the use of the NLTK's methods to parse text into sentences would have made sense to create the list of provisions, it was not used because the canonical XML versions of the world constitutions were already parsed into sentences.
All of the work presented here was done against a data set called a Distant Reader study carrel. The study carrel includes all of the original data, the post-processed data, the software do to the work, visualizations, and this analysis. The whole of the study carrel is temporarily available at the following URL:
http://carrels.distantreader.org/curated-constitutions-2025/index.zip
For more detail regarding Distant Reader study carrels, see the read me file.
Eric Lease Morgan <emorgan@nd.edu>
Navari Family Center for Digital Scholarship
Hesburgh Libraries
University of Notre Dame
April 16, 2025