D-Lib Magazine
Digital libraries and meeting reports
This is a reading of the whole of a journal called D-Lib Magazine. The journal is no longer in publication, but it was a respected journal in its time, and it's content was centered around digital libraries. It ran from 1995 to 2017.
To create this data set, I first used wget to mirror/cache the journal locally. The majorith of the articles in the cache were associated with a metadata.xml file, for example, 04birdsey.meta.xml. I looped through all of these files with a script of my own design -- meta2csv.py -- and output a CSV file suitable to my Reader application. The Reader then created a data set from which this analysis was done. By the way, the CSV file I created ultimately got saved as the data set's index.csv file.
Based on my calculations, the journal published at least 860 articles for a total of 3.4 million words. By comparision, the Bible is aobut .8 million words long, and Moby Dick is about .2 million words long. So, now, ask yourself, "How big is this collection compared to the Bible or Moby Dick?" Along the way my Reader created a rudimentary bibligraphy in the forms of plain text and JSON, and now you can begin to adress the question, "What is D-Lib Magazine about? What are some of the things it emphasises, and which articles are good examples of such?" Moreover, "How have some of these things changed over time?" Traditdional bibliographic reading can address these questions, but the process is slow going.
The aboutness of the journal can be modeled in a rudimentary way by counting and tabulating the frequencies of unigrams, bigrams, and keywords (sans stop words). This modeling technique is often seen as sophmoric, and rightly so. That said, it is a quick and easy way to connote the scope of the collection. It is a form of truth that ought to be taken with a grain of salt. Now, again, ask yourself, "What is D-Lib Magazine about?"
 unigrams |
 bigrams |
 keywords |
The journal's articles and associated keywords can be modeled as a network graph where articles and keywords are nodes, and edges are the associations of keywords to articles. Once one creates a network graph, one can compute and visualize the graph in a myriad of ways. The graph (below) visualizes the in-degree of the keywords and their assoication with other keywords. Moreover, the color of the edges denote clusters of keyword/document combinations. Think "themes". From the graph we might quickly assume the articles were about university libraries, research, and access to data/information. But again, this might be a quick assumption.
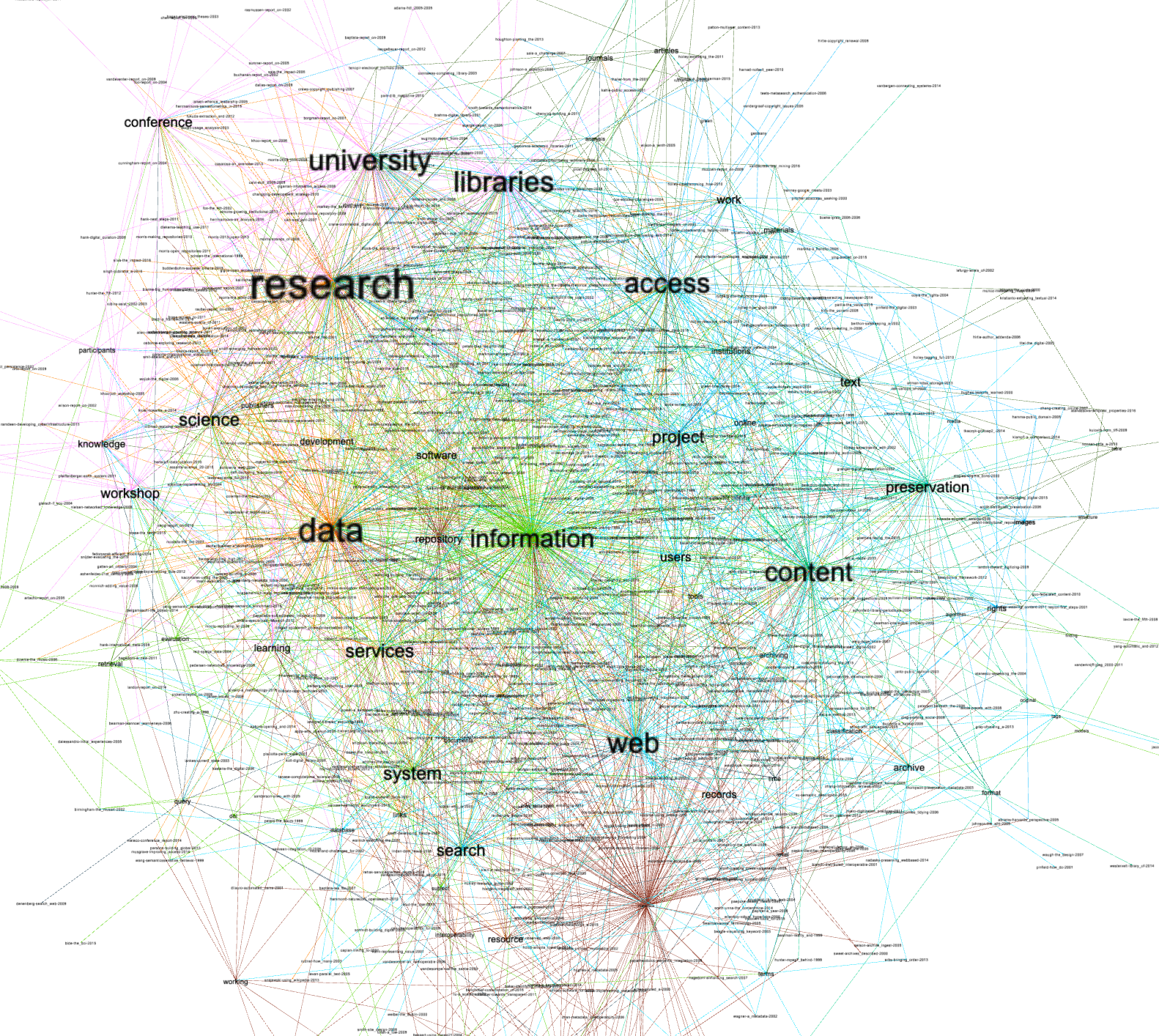
I then search the underlying relational database for articles with keywords "research", "data", and "access" the the most eight most-relevant articles included the following.
- Opening and Linking Agricultural Research Data
- The Sixth Annual 2015 VIVO Conference
- e-Science for Musicology Workshop Report
- A Report from the 2011 ICSTI Workshop on Multimedia and Visualization Innovations for Science
- Towards a Marketplace for the Scientific Community: Accessing Knowledge from the Computer Science Domain
- OpenAIREplus: the European Scholarly Communication Data Infrastructure
- Baltimore SPARC IR and SUN PASIG Meetings: Towering Content and Evolving Online Scholarly Publishing Models
- Berlin 7: Open Access Reaching Diverse Communities
Topic modeling is an additdional technique used to model the aboutness of a corpus.
| labels | weights | features |
|---|---|---|
| information | 0.50672 | information work access copyright libraries content might need public rights users issues |
| libraries | 0.24233 | information libraries university research conference workshop project development science national issues international |
| service | 0.1926 | service services metadata system repository data content search information access repositories objects |
| users | 0.15815 | information users resources students services libraries learning university research education online reference |
| preservation | 0.15592 | preservation information content repository data software objects format storage metadata management system |
| search | 0.13481 | search information records semantic subject system figure data terms description libraries record |
| text | 0.12971 | text research table citation number analysis information results set documents using data |
| access | 0.12794 | access repositories articles open repository journals institutional university research article number scholarly |
| data | 0.1069 | data research open information datasets scientific science researchers citation access dataset linked |
| collections | 0.09905 | collections project images metadata museum digitization files content text using museums institutions |
| web | 0.09725 | web site sites content users archive tags pages search archives internet links |
| metadata | 0.08025 | metadata resource elements xml information data core schema dublin identifier used element |
 topics |
 topics over time |
- ./cache/chen-report_on-2005.html
- ./cache/sugimoto-report_from-2004.html
- ./cache/foo-report_on-2004.html
- ./cache/borgman-report_on-2001.html
- ./cache/fox-the_4th-2002.html
- ./cache/iverson-report_on-2002.html
- ./cache/hank-international_data-2009.html
- ./cache/casarosa-an_overview-2013.html
Eric Lease Morgan <eric_morgan@infomotions.com>
Infomotions, LLC
November 15, 2025