I am curious to learn, "What sorts of things are in the Hesburgh Libraries Archives?"
To answer this question, I first used a program called wget to downloaded all of the Encoded Archival Description (EAD) files from the Archives's website. This generated a cache of 1,200 XML files. I then extracted the titles, biographical histories, and scope notes of 258 of these items. They represent Catholic manuscript collections and collections termed 'Notre Dame-related' (professor and alum personal papers, materials related to Notre Dame history, et cetera). These items did not include closed University records.
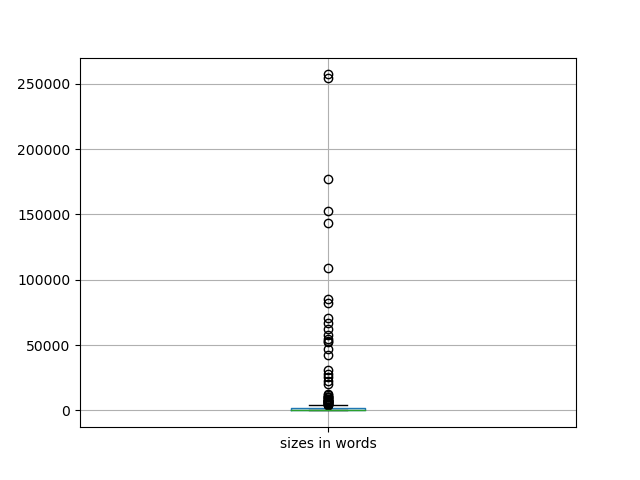
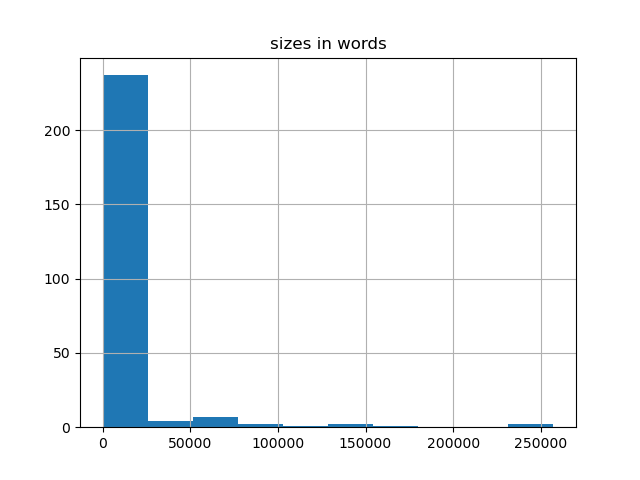
The resulting collection of descriptions is about 2.2 million words long. (For comparison's sake, the Bible is about .8 million words long.) And while the average size of the descriptions is 8,500 words long (the size of a long journal article), two descriptions are off the charts in terms of length; each of the Notre Dame Presidents' Letters (1856-1906) and the University Photographer collections are .25 million words long. In other words, the description of these two collections make up about 25% of the entire descriptions in this analysis. Put yet another way, the sizes of the collections are skewed, as the following two charts illustrate:
More to my question -- What sorts of things are in the collection? -- rudimentary unigram, bigram, and keywords analysis points to photographs, sports (namely, football and basketball) as well as the names of men. Given the titles of the predominate collections, this ought not be surprising. Again, charts are illustrative:
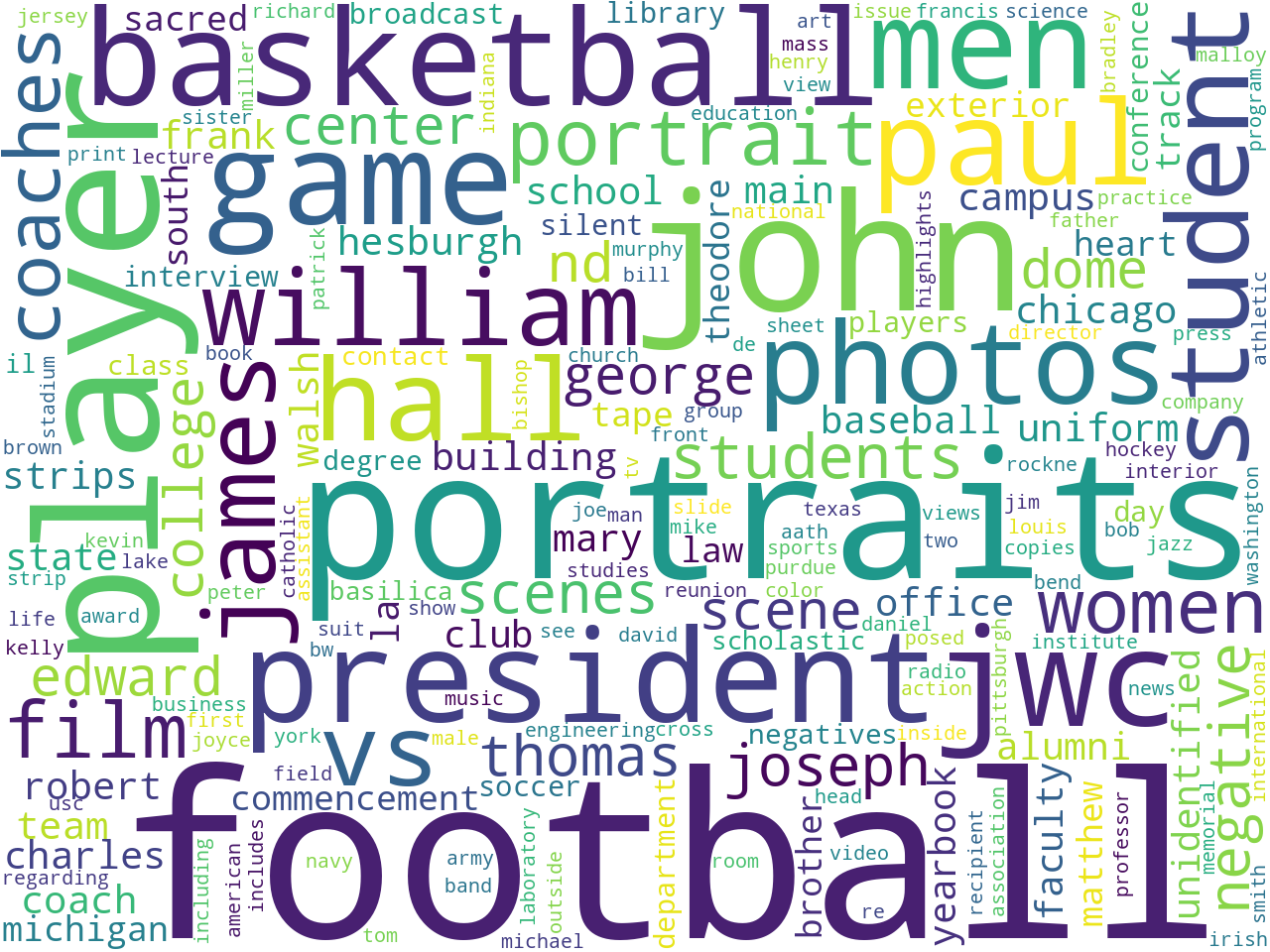 unigrams |
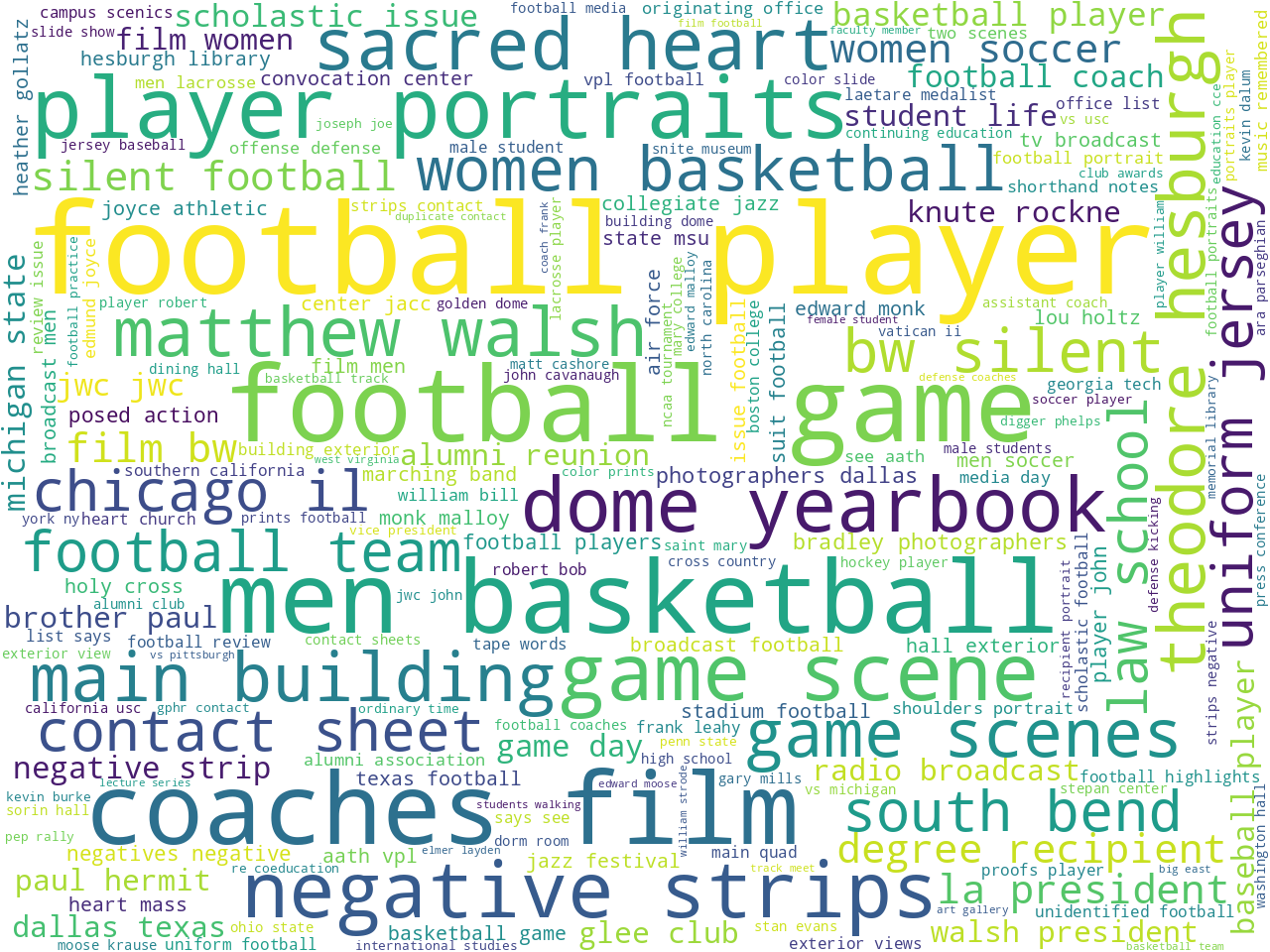 bigrams |
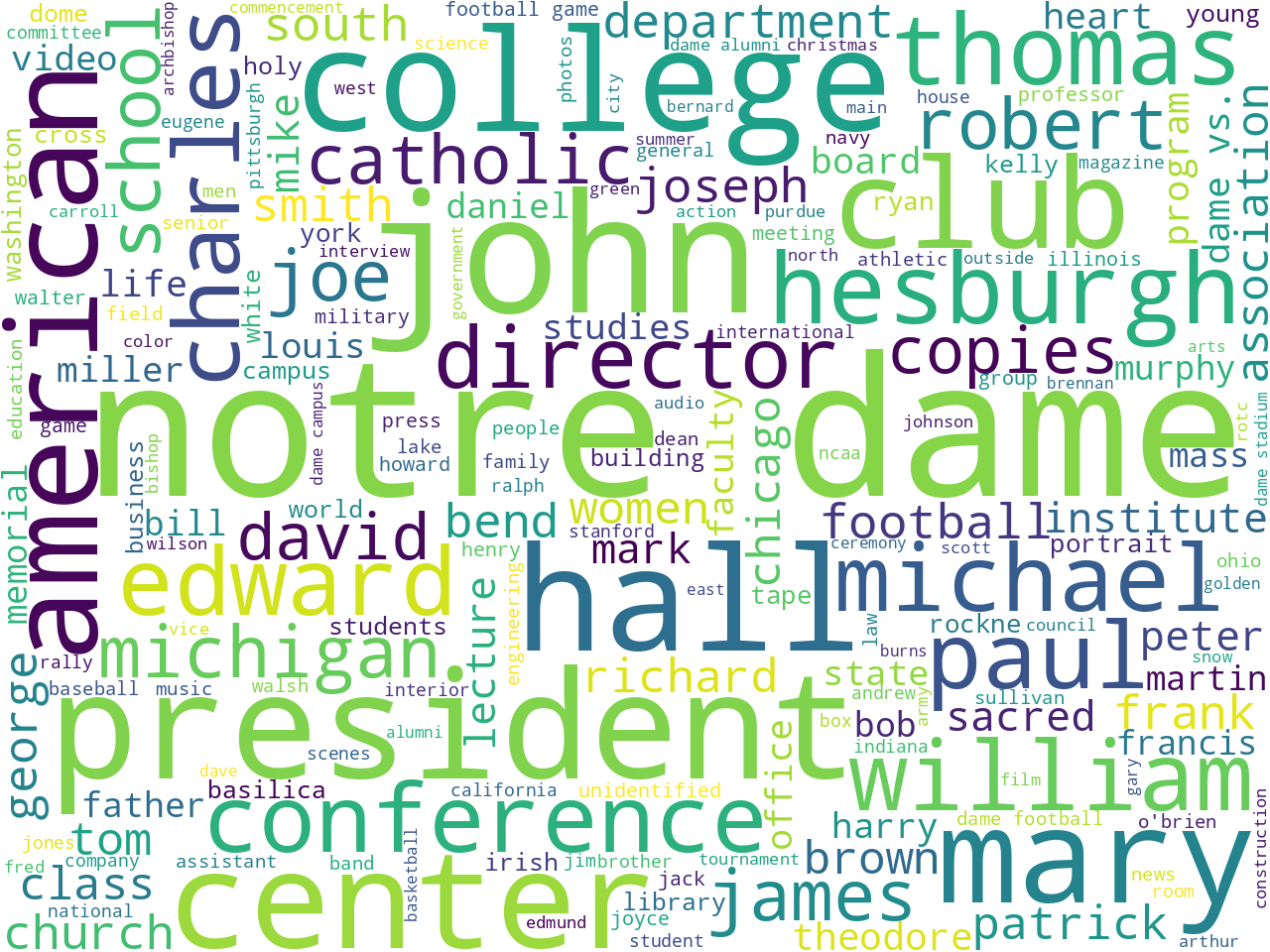
statistically significant keywords
For additional descriptive statistic sorts of illustrations, see the automatically generated page descriping this data set.
Topic modeling is a popular machine learning technique used to enumerate latent themes is a corpus. The application of topic modeling to this corpus results in a seemingly more balanced view of the collection. For example, if I model the corpus for a single word used to describe the whole, then the result is still sports-related, "football". But if I model the corpus for four topics, and each topic is elaborated upon with four words, then the results are more nuanced:
labels weights features
john 0.49117 john tape degree interview
portraits 0.17081 portraits hall photos student
football 0.07759 football player basketball coaches
jwc 0.07554 jwc president john paul
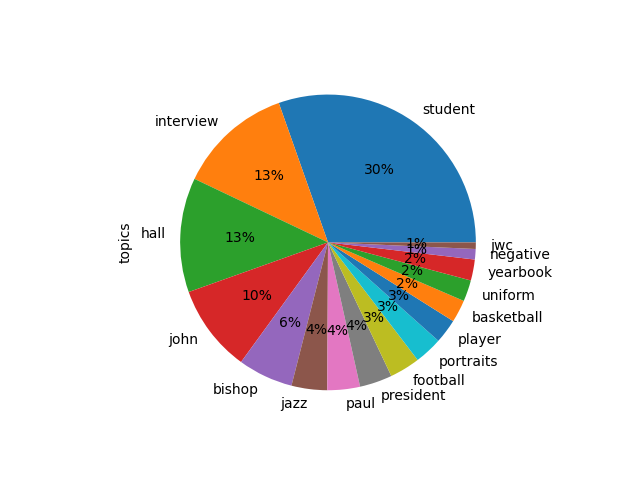
Modeling the corpus on sixteen words results in the following themes and proportions; now, the results are not so much about sports, but sports do exist:
labels weights features
student 0.50625 student catholic john institute department sun...
interview 0.20874 interview class tape lecture series show progr...
hall 0.20840 hall photos students building student main cam...
john 0.15900 john degree commencement portrait hesburgh rec...
bishop 0.10041 bishop church john chicago art catholic patric...
jazz 0.06493 jazz tape music band festival collegiate words...
paul 0.05931 john paul william james brother thomas charles...
president 0.05926 president walsh matthew news john james willia...
football 0.05535 football film coaches basketball silent broadc...
portraits 0.05069 portraits player football uniform game basketb...
player 0.04416 football player team john track game scene uni...
basketball 0.04098 basketball film coaches soccer copies broadcas...
uniform 0.03875 football player uniform photos portrait texas ...
yearbook 0.03823 yearbook dome game football scholastic scene i...
negative 0.01902 negative strips contact negatives sheet strip ...
jwc 0.01184 jwc chicago paul college john york south baseb...
Hoping for an elaboration, I created a network diagram from the top four topic words and their bigrams. The following illustrates the results, and my take-away is, "The things in the collection are more about the University as an institution and its people and less about the University's academics":
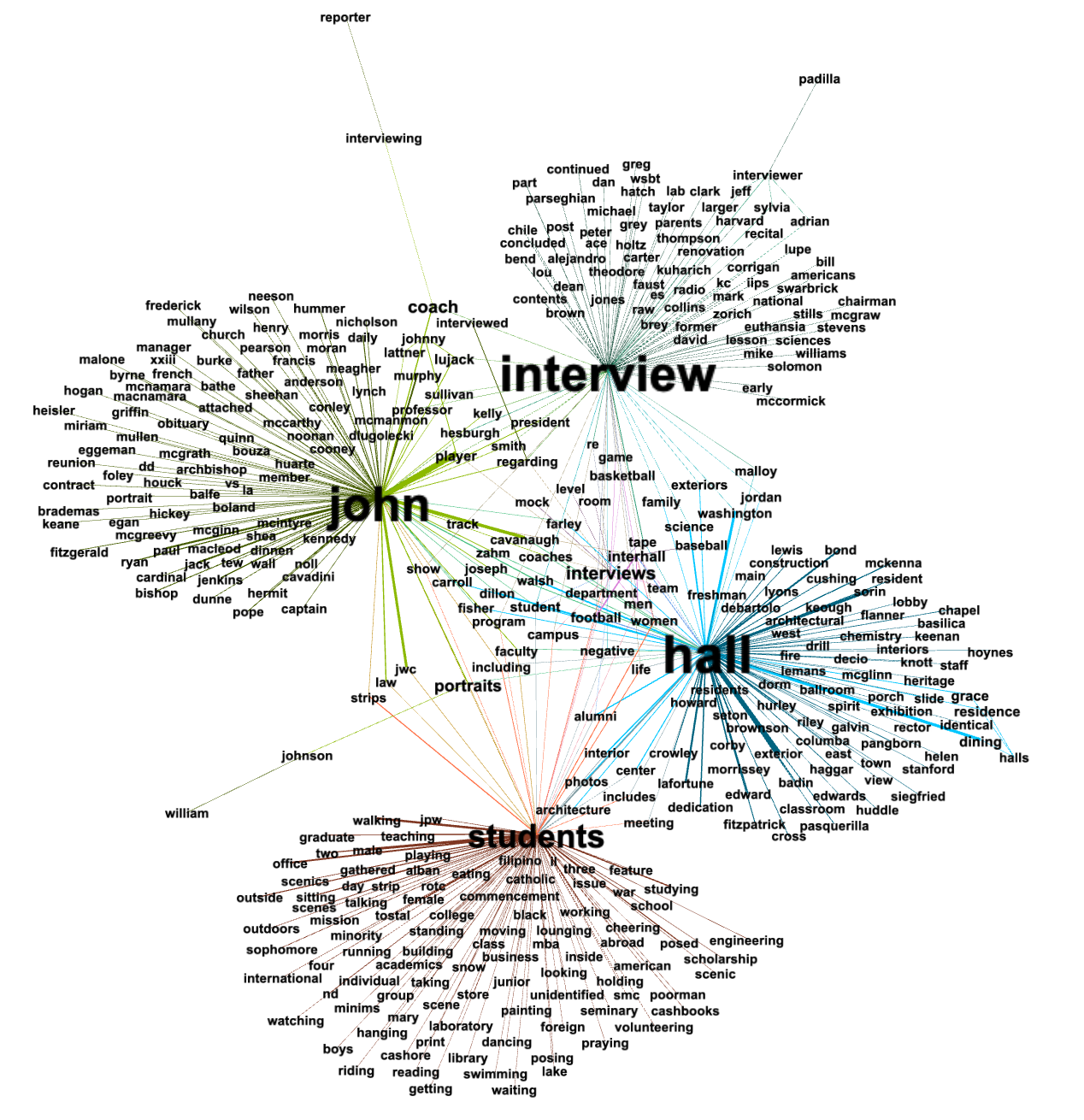
In conclusion, I was not able to answer my origainal question; I do not know what sorts of things are in the collection. On the other hand, I believe I do have a handle on what the things are about. They are about the University of Notre Dame. Duh!?
P.S. It would be interesting to learn who or what "jwc" is. Concordancing for jwc was not very telling, and the following results are typical:
j.e. grove to am; juan a. garcia jr. to jwc ; charles a. gorman to jwc; julia a. gal garcia jr. to jwc; charles a. gorman to jwc ; julia a. galvin to jwc; rev. p.j. clan es a. gorman to jwc; julia a. galvin to jwc ; rev. p.j. clancey (rector of the churc church of the assumption, waco, tx) to jwc ; n.o. gray to jwc; theodore e. gorman t umption, waco, tx) to jwc; n.o. gray to jwc ; theodore e. gorman to am; mrs. m.d. fa e e. gorman to am; mrs. m.d. fansler to jwc ; p.a. gushurst to jwc; john c. gaul to . m.d. fansler to jwc; p.a. gushurst to jwc ; john c. gaul to [perfect of studies]; [perfect of studies]; r.a. galligan to jwc ; benjamin gotfredson am; juan manuel to el to maximo m. gomez; carlos grande to jwc ; mrs. m.d. fansler to jwc; jwc to louis los grande to jwc; mrs. m.d. fansler to jwc ; jwc to louis fox; john gerrard to jwc; rande to jwc; mrs. m.d. fansler to jwc; jwc to louis fox; john gerrard to jwc; w.a. jwc; jwc to louis fox; john gerrard to jwc ; w.a. sutherland to [jwc]; jwc to peter
According to one of my colleagues, jwc might very well be John W. Cavanaugh.
This entire data set -- study carrel -- ought to be available for downloading at http://carrels.distantreader.org/curated-hesburgh_libraries_archives-2023/index.zip.
Eric Lease Morgan <emorgan@nd.edu>
Navari Family Center for Digital Scholarship
University of Notre Dame
Date created: March 7, 2023
Date updated: June 1, 2024