Information Technology and Libraries: A Reading
Libraries and LITA
A few years ago I hacked together a couple of systems I variously called OJS Toolbox or OJS Toolbox Redux, and the purpose of the systems were to harvest content found at the other end of OAI-PMH data repositories managed by Open Journal Systems implementations. One of the repositories I harvested was the content from a journal called Information Technology and Libraries. This reading is rooted in that collection. In other words, I took advantage of OAI-PMH, harvested as much metadata as I could from Information Technologies and Libraries, and then harvested as much full text as I could so I could do this reading. By the way, the journal's data repository root URL is https://ital.corejournals.org/index.php/ital/oai.
Size and Scope
This particular collection includes just more than 700 articles for a total of 3 million words. (Note: The journal has been in publication since 1968, but the data repository seems spotty before 2005.) The rudimentary bibliography in plain text and JSON forms is a way to learn about the scope of the journal, but traditional reading of the bibliography will take you a while.
The counting and tabulating of unigram, bigram, and keyword frequencies (sans stop words). begins to allude to the journal's scope. Not incidentally, the curation of a stop word list is always challenging, since one size doe not fit all. In this particular case the journal's title includes at least two significant words ("information" and "libraries"), and after using a concordance to determine the degree these words were a part of titles (or not), I decided to not make them stop words.
 unigrams |
 bigrams |
 keywords |
For more results regarding the counting, tabulating, and visualization of extracted feature frequencies, see the computed home page.
Network Analysis
The relationships between keywords, authors, and articles can be modeled as a network graph. After creating such a model I emphasized the sizes of the keywords by taking their degree into account. The keywords' proximity to other keywords is brought to light through the layout. I highlighted their significance more by measuring their "betweeness" and eliminating keywords with small rather than larger betweeness values. Finally, I computed "modularity" of the whole to color code the keywords into "neighborhoods". In the end, the graph echoes the information depicted in the keywords word cloud, but with greater nuance. In short, the journal seems to be about "systems", "services", "access", "users", "content", "information", and "libraries". And when articles are about "systems", they may also be about "metadata" and "catalog". Note the group of nodes off to the left. These are the items about LITA, the organization who hosted the journal for a long time. Now ask yourself, "How might the services discussed in the journal be characterized? Were they services centered around preservation?" Similarly, "When cataloging was discussed, then what else was discussed?"
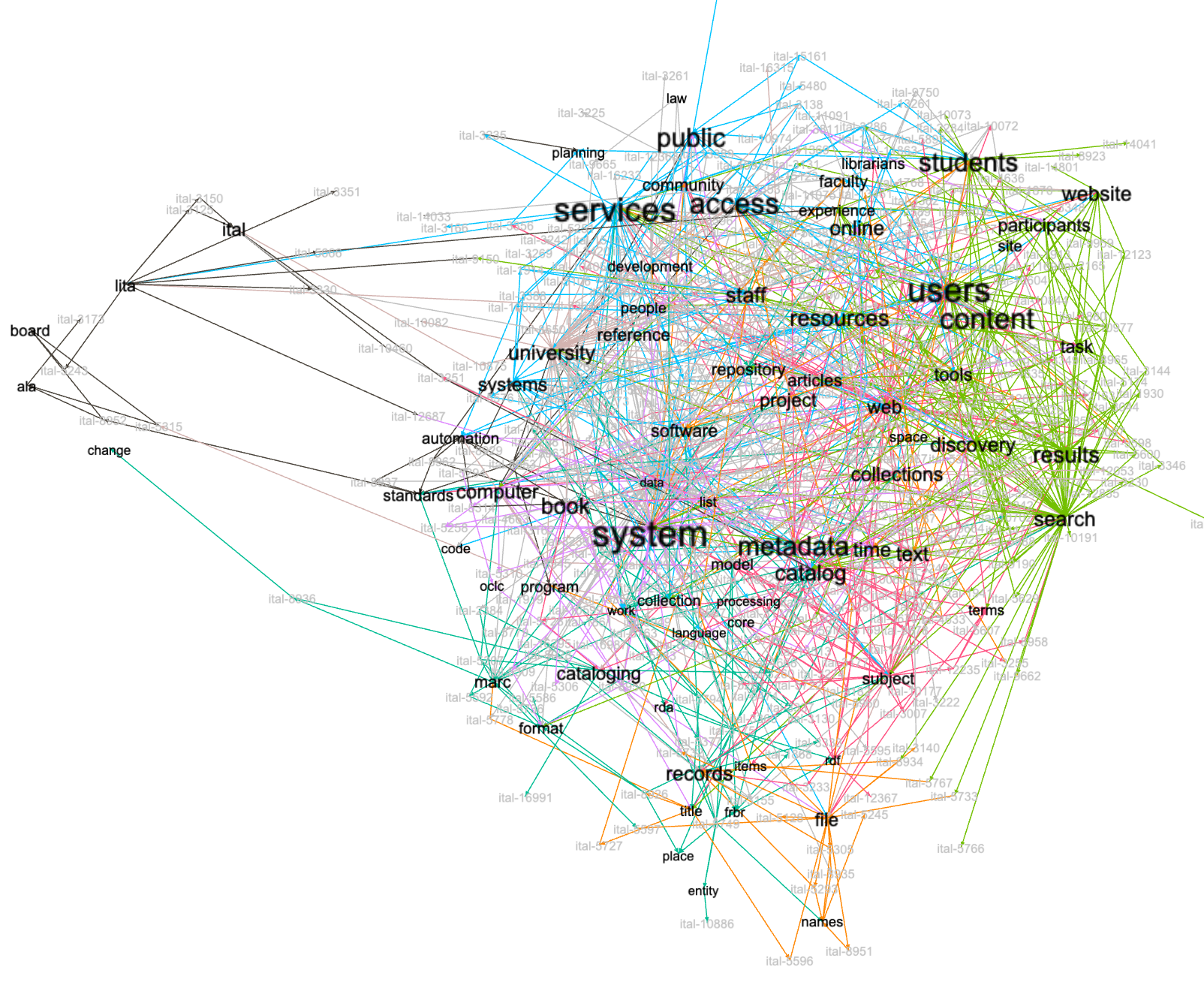
network of keywords and documents
Given this overview of what the journal might be about, I queried the underlying relational database to identify representative articles; I searched for articles with the keywords of system and services and users. Below are the eight highest relevancy-ranked articles.
- Technical Communications
- Tagging: An Organization Scheme for the Internet
- Editorial and Technological Workflow Tools to Promote Website Quality
- Migration of a Research Library's ICT-Based Services to a Cloud Platform
- Personalization of Search Results Representation of a Digital Library
- Decision-Making in the Selection, Procurement, and Implementation of Alma/Primo: The Customer Perspective
- Metadata to Support Next-Generation Library Resource Discovery: Lessons from the eXtensible Catalog, Phase 1
- Investigations into Library Web-Scale Discovery Services
Topic Modeling
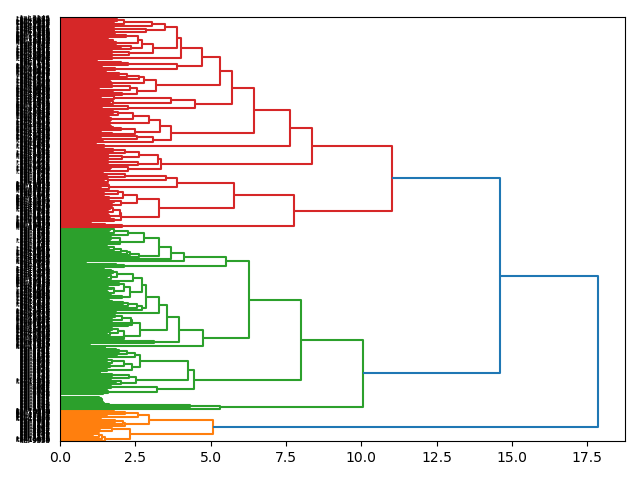
Topic modeling is an additional method used to compute the aboutness of collections of narrative text. Based on my professional judgment, I decided to topic model for twelve topics. (See the dendrogram.) Based on the topic modeling, the journal may be about "work", "libraries", "search", "records", etc. Each of these labels ought to be interpreted as an associated set of hyphenated words. For example, "work" ought be be read as "work-lita-information-libraries-time-people-make-even". The topics ("labels") are too much different from the networked keywords. Whew!
{kind=link}
| labels | weights | features |
|---|---|---|
| work | 0.39447 | work lita information libraries time people make even |
| libraries | 0.31797 | libraries content staff system services project management web |
| search | 0.19728 | search users results discovery information usability libraries students |
| records | 0.18727 | records data record file system marc title catalog |
| information | 0.16379 | information libraries system university national systems computer standards |
| public | 0.14324 | libraries public services mobile access information internet reference |
| students | 0.14262 | information students libraries research learning study social academic |
| data | 0.08553 | data metadata information libraries web model classification knowledge |
| collections | 0.07545 | collections google research information collection access scholar articles |
| software | 0.06869 | software dspace data server storage web file system |
| accessibility | 0.05417 | accessibility information copyright web text content image preservation |
| users | 0.04813 | data information search users gis system tags query |
Each of the topic model labels are associated with weights denoting the size of the topic compared to the whole. Thus, the weights can be visualized as a pie chart. By extension, four of the twelve topics (one third of the topics) are just more than half of the whole. Put another way, the journal might be mostly about "work", "libraries", "search", and "records", while everything else is somewhat incidental.
The topic model can be supplemented with metadata such as year values. The model can then be pivoted on the year values to illustrate how the topics ebbed and flowed over time. The result is the line graph, below. Notice the dramatic change occurring around 2005, and I attribute this to the sketchiness of the collection prior to that year. The data set is incomplete. That said, one maybe still be able to draw conclusions. For example, prior to 2005 much of the literature may have centered around the MARC record and how to use it most effectively. On the other hand, with the advent of the Internet, Web technologies may have taken a the forefront. If the whole of the journal were to be made available, then such a hypothesis could be more rigorously tested.
 topics |
 topics over time |
The topic model can be reverse-engineered to list the documents most associated with a given topic. Below is a list of the eight most heavily weighted documents surrounding the "work" (work-lita-information-libraries-time-people-make-even) topic. Upon closer inspection, many of the listed documents are about LITA. This does not necessarily conflict with the keyword analysis. Instead, it complements it because the "work" topic has a weight of .39 and the second most significant topic ("libraries") has a weight of .31, and all of the subsequent topics are relatively smaller by comparison. Thus, one might say the journal is about the workings of LITA as well as libraries.
The eight most heavily weighted "work"-related articles:
- ./cache/ital-3003.pdf
- ./cache/ital-1864.pdf
- ./cache/ital-1765.pdf
- ./cache/ital-3216.pdf
- ./cache/ital-1766.pdf
- ./cache/ital-3172.pdf
- ./cache/ital-10019.pdf
- ./cache/ital-9808.pdf
The eight most heavily weighted "libraries"-related articles:
- ./cache/ital-15599.pdf
- ./cache/ital-9255.pdf
- ./cache/ital-12453.pdf
- ./cache/ital-11859.pdf
- ./cache/ital-13209.pdf
- ./cache/ital-3005.pdf
- ./cache/ital-9152.pdf
- ./cache/ital-3388.pdf
Additional Network Analysis
To paraphrase a linguist named John Firth, "You shall know a word by the company it keeps", and now-a-days, through the use of semantic indexing, it is possible to plot the location of words in an n-dimensional space and then compute the cosine distance between words. In this way one can learn what words are used "in the same breath" as other words, or put another way, to learn what are the words keeping company with other words.
Such is exactly what I did with a subset of the study carrel's keywords. I first used a program -- keywords2lexicon.py -- to create a lexicon of desired keywords. I then used another program -- lexicon2vectors.py -- to identify and output semantically similar words. The output was an edges table -- edges.tsv -- a list of words, associated words, and weights denoting similarity. Finally, I imported the edges table into Gephi for the purposes of visualization.
This is the first time I used this particular technique to decern the aboutness of a study carrel, and if the process is sound, then I can assert a few things. First, the concept of "users" is very highly correlated to other aspects of the journal. Users are associated with just about everything else: research, search, resources, and content. There is one thing I find a bit disturbing, namely, "data" and "information" are so far away from each other. Personally, I believe data and information to have very high associations. This begs the question, "What are the definitions of 'data' and 'information'?" In this case, maybe the answer has something to do with my stop word list. By the way, the nodes related to the concept of LITA are not displayed, because they were in a neighborhood disconnected with the balance of the nodes.
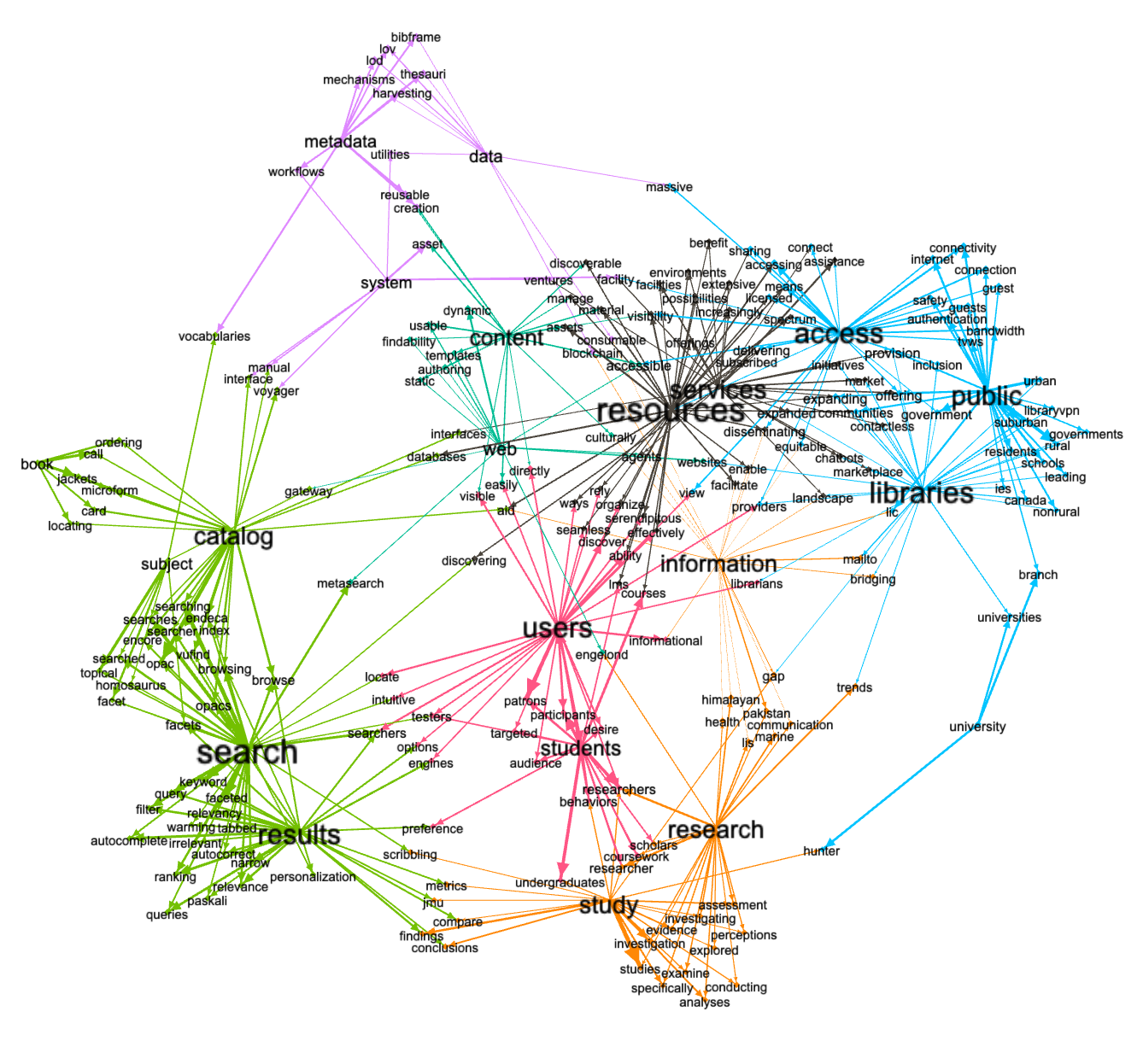
network of semantically similar words to keywords
What Are Information and LITA?
So? What is information? To address this question I concordanced for the phrase "information is" and in return I got 230 sentence fragments. I then used a large-language model to summarize/distill the fragments down to two paragraphs. The result seems plausible to me, and I think it would be interesting to apply this same technique to other digital library-related journals for the purposes of compare and contrast.
Based on the provided text, this appears to be a compilation of various sentence fragments related to information management, technology, and library science from a 2007 publication. The context revolves around the evolving nature of information in the digital age, emphasizing its creation, storage, accessibility, and management within library systems. Key themes include the shift from information as a static resource (like a book) to a dynamic, digital asset that requires sophisticated technological systems for organization and sharing. The text also touches on challenges such as licensing, preservation, and ensuring information is machine-readable and useful for both patrons and library staff.
The summary highlights several technical processes and considerations, such as the use of metadata, linked data principles (like triples and RDF), and integrated library systems. It also points to broader issues like the digital divide, the importance of user-friendly interfaces, and the ethical responsibilities of libraries in managing information. Overall, the context underscores the complex interplay between technology, information accessibility, and the changing role of libraries in a rapidly digitizing world where information is increasingly licensed, aggregated, and analyzed to improve user experience and operational efficiency.
Just for fun, I concordanced for variations of 'LITA is', and I will leave it up to you to decern any meaning from the results.
lita is a well-known and well respected brand in the library community. talking to my no lita is at our top technology trends; however, it is not the only place where visionary lita is brighter with these new lita leaders. good luck and thank you for your service! lita is directly benefitting from the expertise of the other groups and they are in tur lita is facing its own challenges as an association. it has had a long and productive r lita is fun. fun and enjoyment, coupled with my dedication to the profession that i lov lita is intriguing reading and well worth an investment of your time. stephen r. salmon lita is its annual sponsorship of ala emerging leaders. this year we sponsored two lita lita is its flexibility to quickly accommodate programming to cover the latest issues a lita is known for its leadership opportunities, continuing education, training, publica lita is looking into introducing some changes to the lita forum. in the feedback and th lita is not only relevant but necessary. with all that hard work accomplished, it must lita is now or where we are hoping lita will be in the future, but i would like to devi lita is one place where anyone can take on leadership roles, gaining valuable experienc lita is ready for some change. change to the board, change to the committees and intere lita is relevant to lita members 365 x 24 x 7 and not just at conferences and lita nati lita is sponsoring 2011 emerging leaders bohyun kim and andreas orphanides. bohyun is c lita is the networking — it’s you. we will have many chances to discuss our through lin lita is the place where you can learn more about these developments and participate in lita is truly a humbling experience. every day i am awestruck by the dedication, energy lita is vital, but there is also work to be done to make that recruitment even easier. lita is well positioned to take the first steps into our next 50 years. thanks to the e lita is your association. where should we be going? help us navigate the future. patric lita was born, was still the era of the big mainframe systems and not-so-common programm lita was founded on the concept of sharing information about technology through conversa lita was founded the world was experiencing an era of profound technological change. the lita was involved with the marc standards through the hard work of henriette avram. the lita was voted into existence (as isad, the information science and automation division) lita will be forced to dissolve over the coming year. the merger will enrich lita members’ o lita will be in the future, but i would like to deviate from the usual path. the theme of th lita will be nationally recognized as the leading source for conmichelle frisque (mfrisque@n
Summary
I spent time creating a Distant Reader study carrel ("data set") from the whole of the easily-accessible articles from Information Technology and Libraries. The carrel includes about 700 articles for a total of 3 million words. Based on the results of various modeling techniques I assert the journal is about libraries and the association (LITA) hosting the journal. ("Duh!?") More importantly, I elaborated on these themes and systematically brought to light additional words used in conjunction with the topic of libraries. While I did not explicitly state it previously, I have done this work so the student, researcher, or scholar can make informed decisions when they want to explore more specific aspects of the data set.
Epilogue
This study carrel is available for downloading from the following URL, and it is made available so others can do their own analysis:
http://carrels.distantreader.org/curated-informationTechnologyAndLibraries-doaj/index.zip
To learn more about Distant Reader study carrels, read (and re-read) the read me file that comes with every carrel.
Eric Lease Morgan <eric_morgan@infomotions.com>
Infomotions, LLC
November 19, 2025