For a number of reasons, I spent some time analyzing a subset of the University of Notre Dame's theses & dissertations, and this missive outlines what I learned.
Since 2003 or so, the University's Graduate School has been encouraging and/or mandating Masters and Doctoral students to upload their completed theses & dissertations to the library's institutional repository. Along with digital (PDF) versions of the theses and/or dissertations, each upload is assoicated with bibliographic as well as topical metdata. This metadata includes things like: authors, titles, dates, abstracts, colleges, degrees, disciplines, subjects/keywords, and contributors. If one is on the University's network, then it is possible to use an application programmer interface (API) to query the institutdional repository and acquire the metadata. This is exactly what I did. After normalizing ("cleaning") the metadata, the result is manifested as comma-separated values (CSV) file.
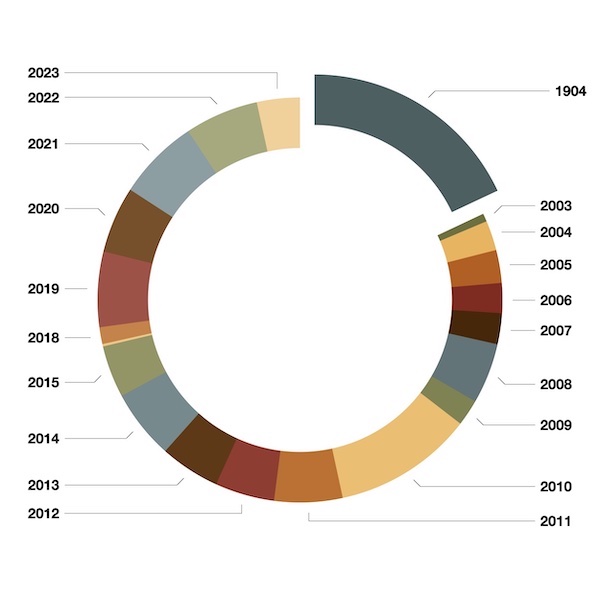
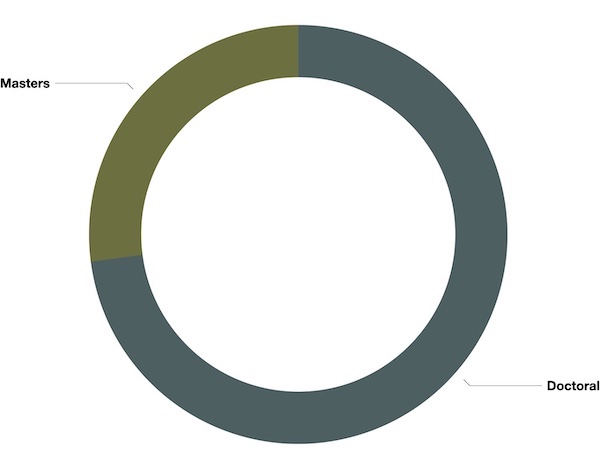
It is now possible to do some analysis against the metadata. For example, since 2003, about 5,200 theses & dissertations have been granted. This means, since 2003, the University has averaged granting about 260 graduate degrees per year. These degrees have been self-classified with dates, types, colleges, and disciplines. The way these things have been applied can be visualized as simple pie charts, as below:
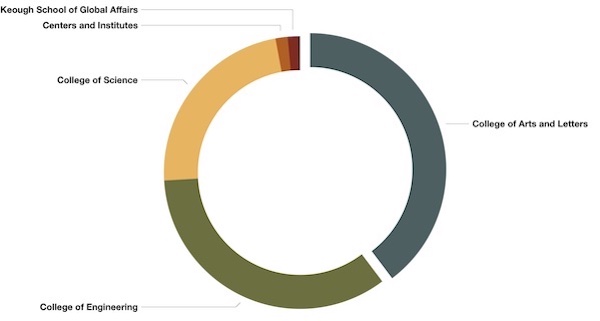
I find the last two visualizations compelling; clearly, more than half, if not two-thirds of the graduate degrees have been in non-humanities fields of study. When I think aboutd the University of Notre Dame, or when people outside of the University think of the University, then I suspect they associate the University with humanities-related fields of study.
The metadata, outlined above, combined with the abstracts of each thesis or dissertation makes for a good dataset where text mining and natural language processing can be applied. Such is exactly what was done. I converted the abstracts to files, fed the files and the metadata to a locally developed tool called the Distant Reader, and learned more about the theses & dissertations.
For example, what do graduate students write about? This question can be addressed by counting, tabulating, and visualizing the frequency of unigrams, bigrams, and statistically significant keywords, as per the following word clouds. An interesting observation, at least I think so, are the names of persons extracted from corpus. The names are most definitely heavy on religion and philosophy. Do scientists not mention people's names?
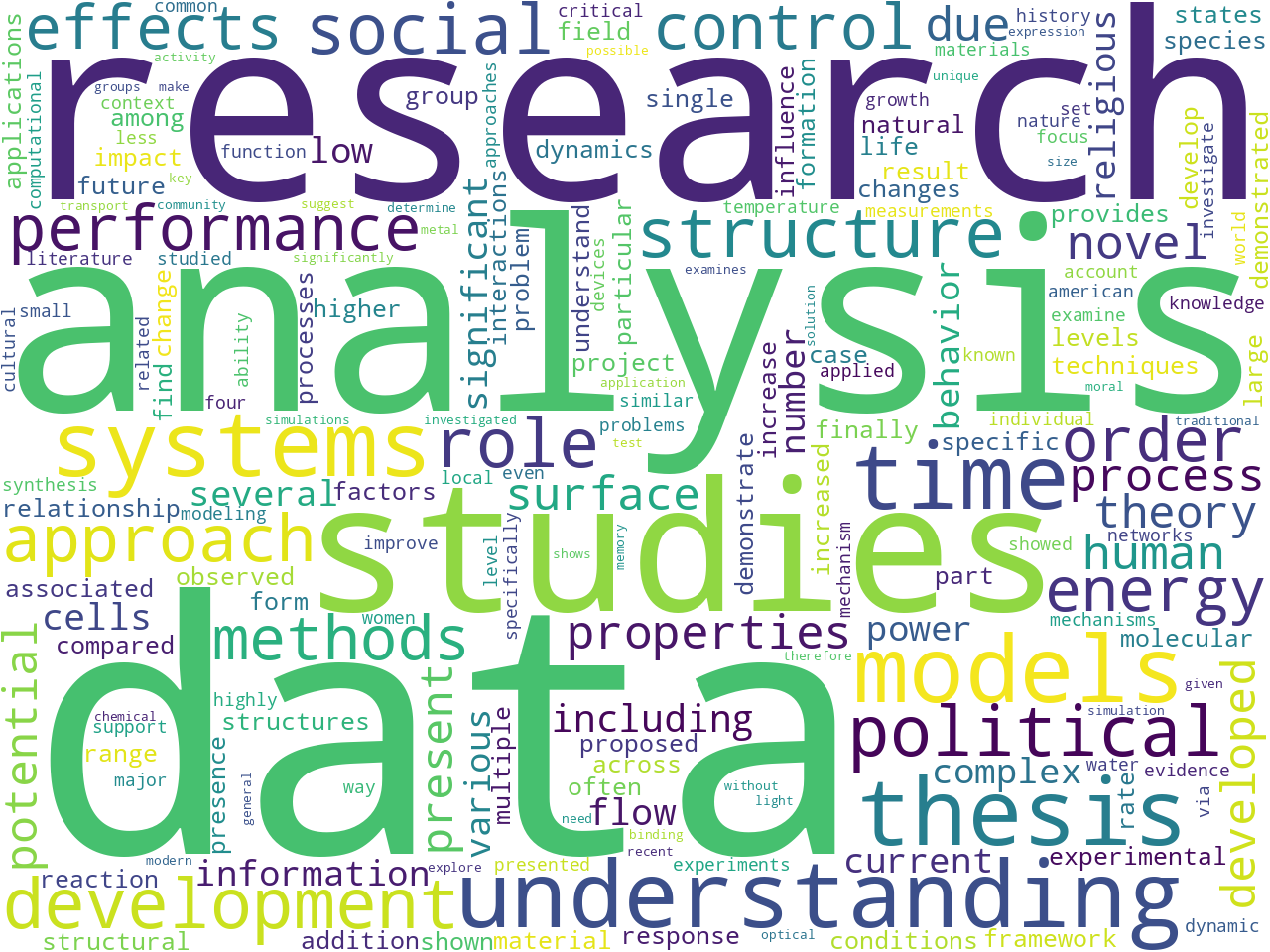

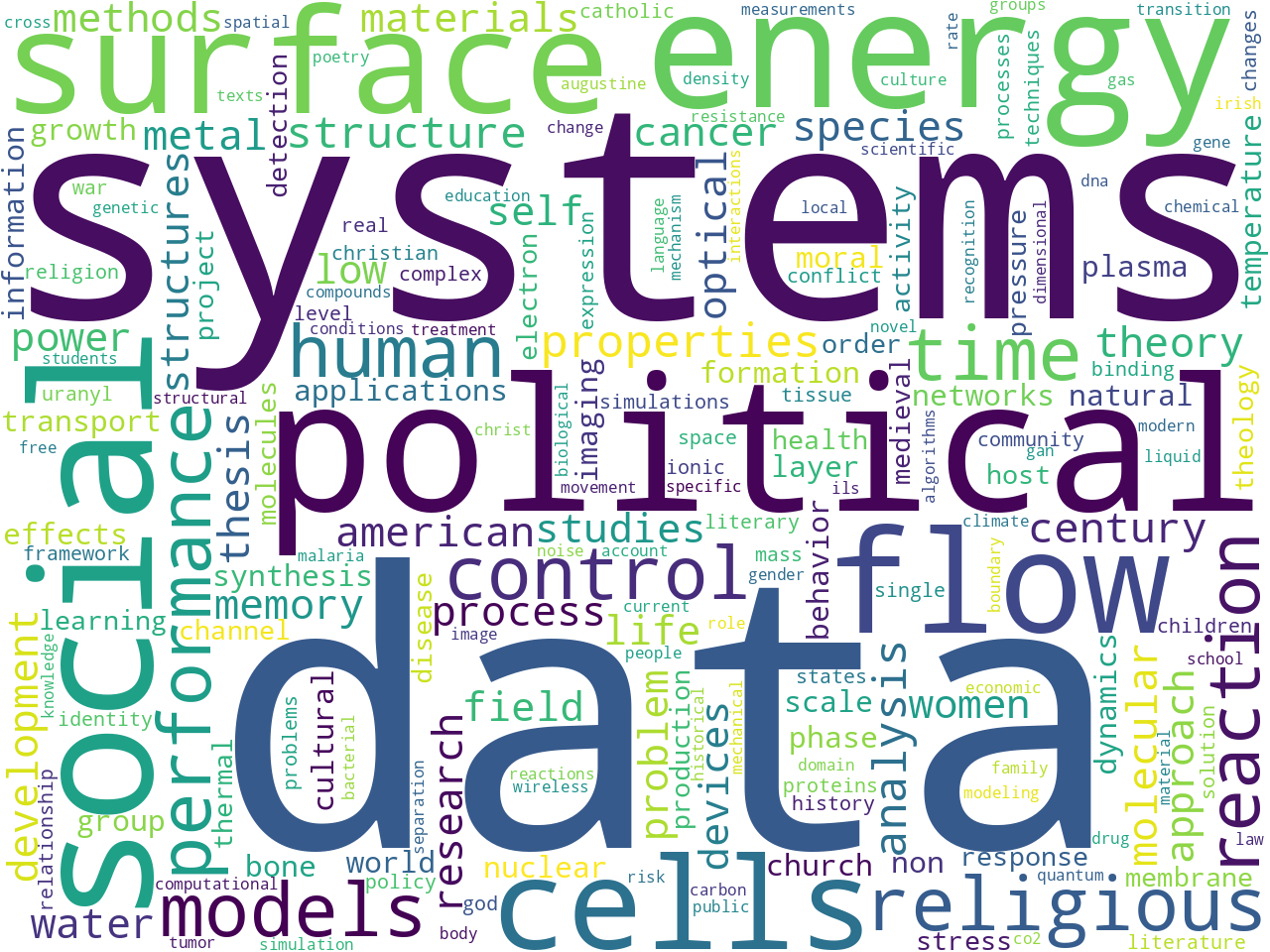
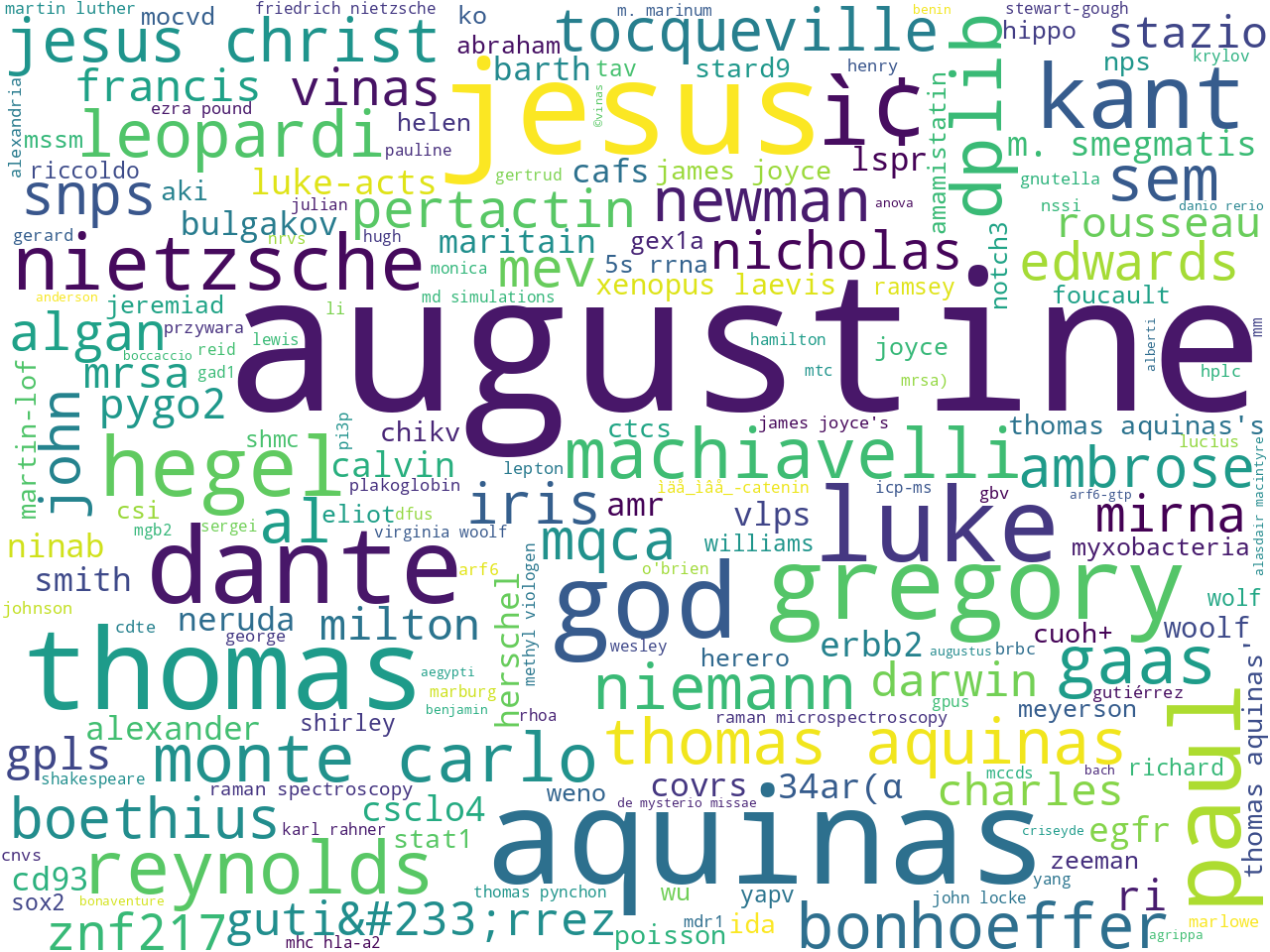
Additional descriptive-like statistics are demonstrated in the automatically generated index page -- index.htm.
Techniques called "feature reduction" and "topic modeling" can be used to compute aboutness as well. When I applied PCA (principle component analysis) against the corpus, the result grossly falls into two categories. We don't know what the categories are, but the ratio is about 2:1, and I believe this echoes ETDs by College pie chart, above:
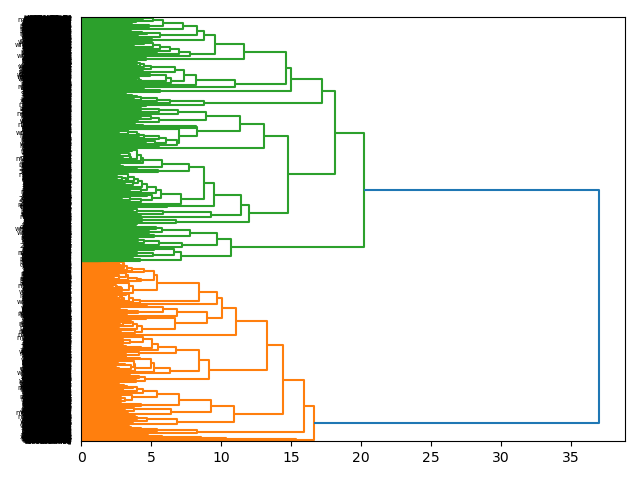
Topic modeling is an unsupervised machine learning process used to enumerate latent themes in a corpus. Given an integer (T), the algorithm clusters the corpus into T topics, and each topic can connote a theme. Remember, there is no corect value for T. After all what is the "correct" number of topics describing the whole of Shakespeare's works?
That said, I topic modeled with a value of T equal to 16, simply because it seemed to tell a good story and the results were easier to visualize. Thus, I predict the theses and dissertations are grossly about the following topics and fall into the following ratios:
topics weights features
data 0.25502 data models methods analysis approach systems ...
political 0.07543 political social religious american cultural s...
human 0.05952 human theory moral account theology christian ...
literary 0.05586 literary texts history century works medieval ...
memory 0.04758 memory research relationship effects social st...
surface 0.04402 surface properties energy materials molecular ...
species 0.03578 species effects water environmental change cli...
flow 0.03256 flow pressure layer boundary surface plasma fi...
cells 0.03136 cells expression cancer role gene signaling di...
systems 0.02846 systems performance control energy networks co...
equations 0.02795 equations theory problem space problems order ...
binding 0.02742 binding proteins activity biological imaging m...
bone 0.02731 bone nuclear reaction energy mechanical proper...
ionic 0.02358 ionic uranyl metal reaction synthesis compound...
devices 0.02184 devices optical performance power current magn...
glia 0.00818 glia standard mass retinal surge coastal higgs...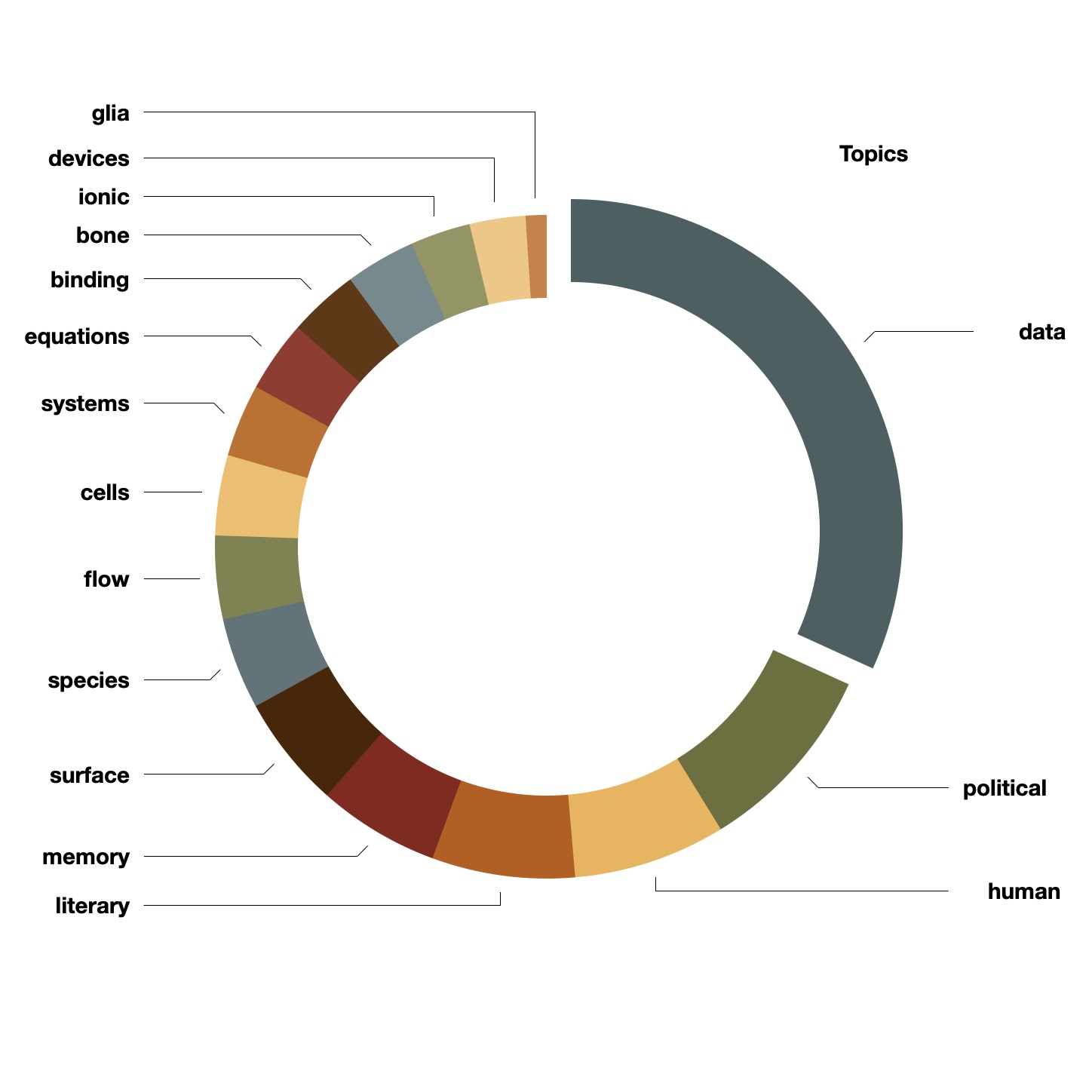
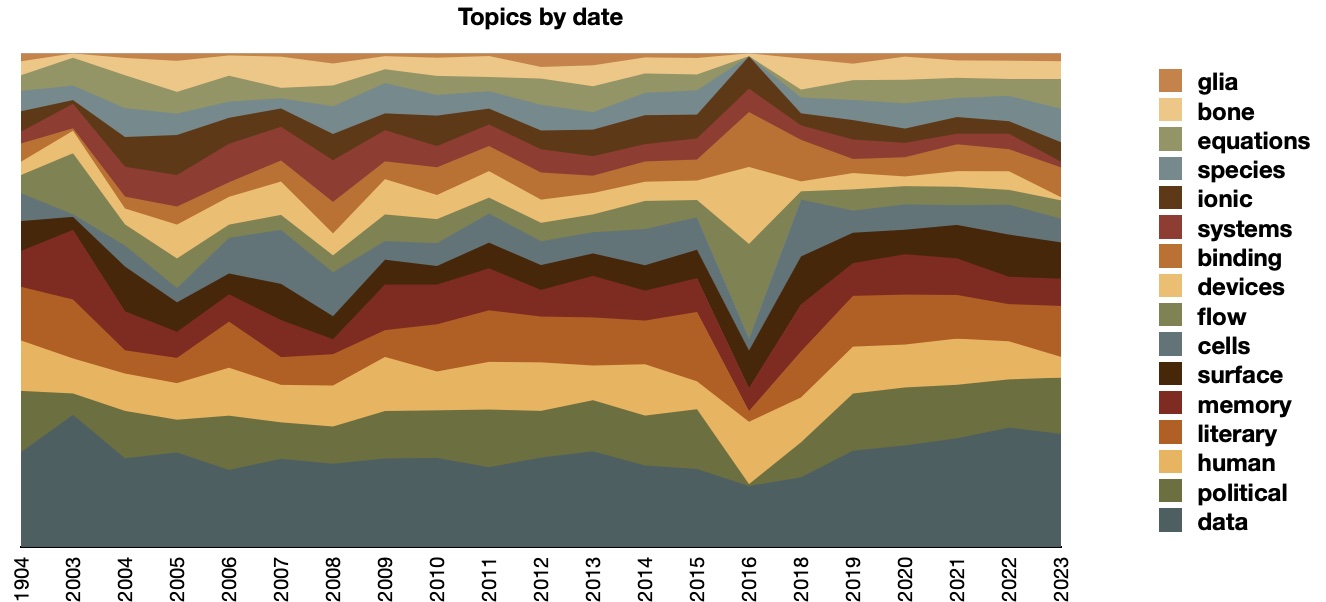
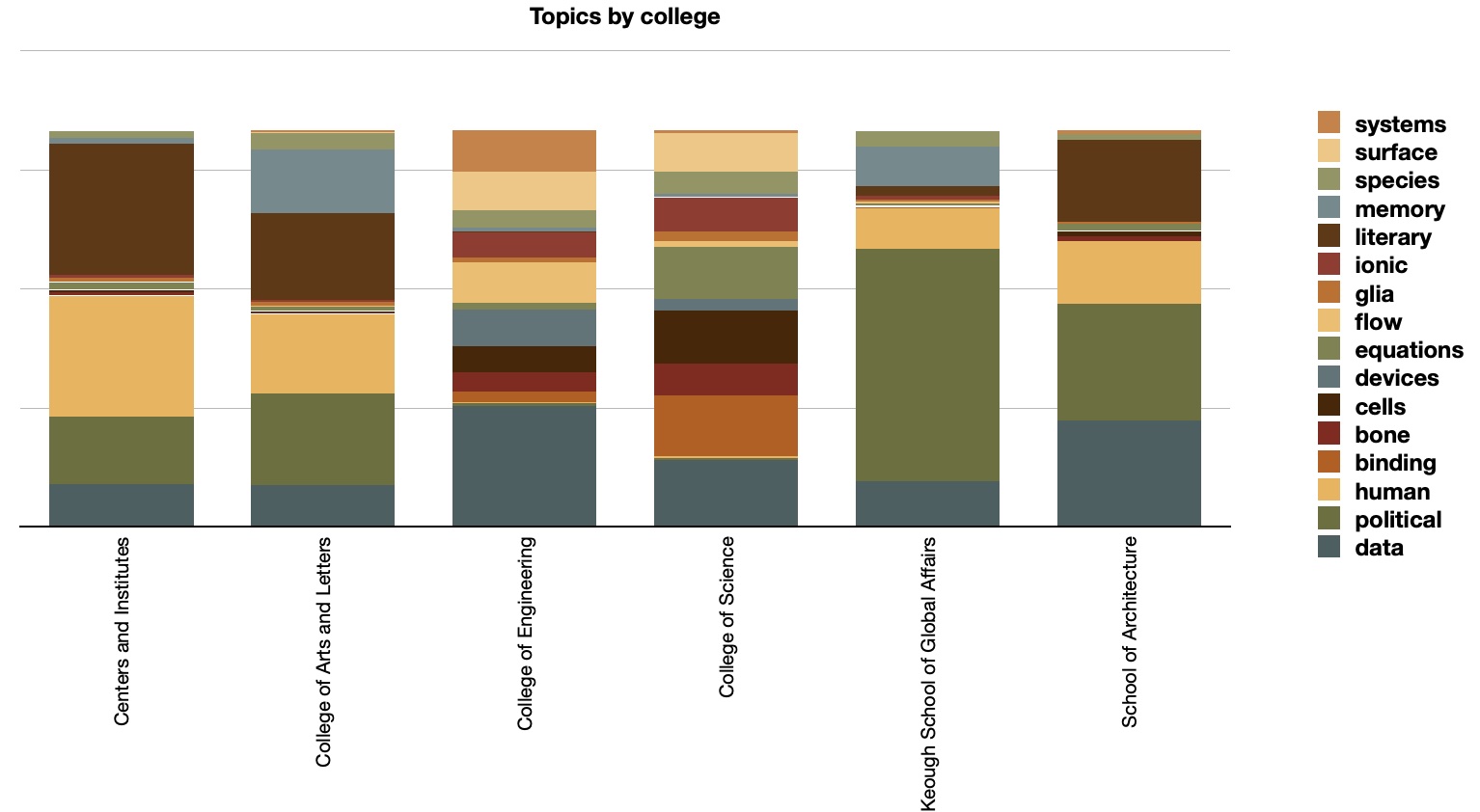
The underlying model can be supplemented with year and college metadata values, pivoted, and visualized. Thus we can address questions such as, "How did the topics ebb & flow over time?", or "What topics dominate what colleges?" In these cases, the topics seem pretty constant over time with some sort of anomaly in 2016. The science-related theses & dissertations where the most diverse, and they emphasized "data", which is really "data models methods analysis approach systems".
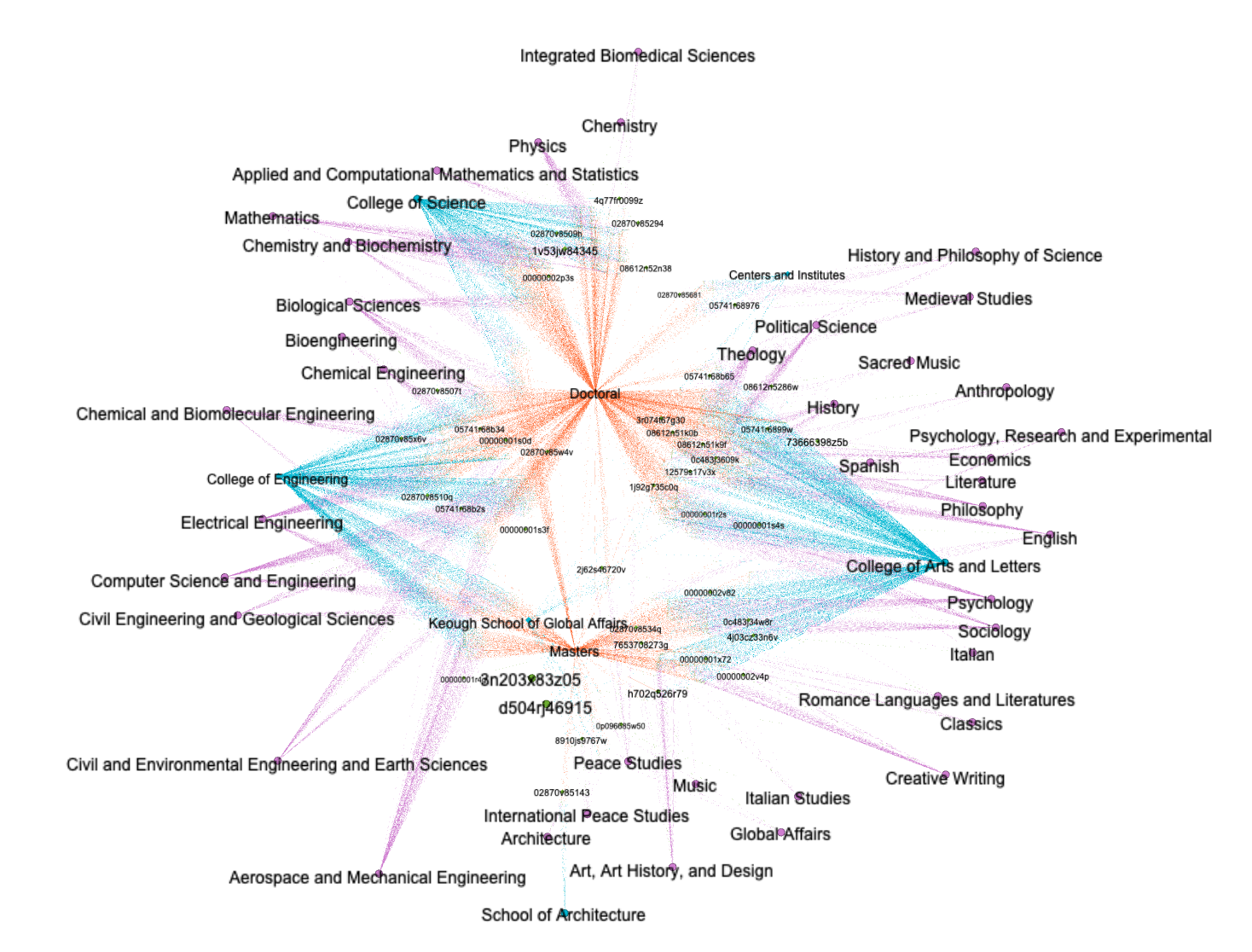
Network graph analysis excels at analyzing the relationships between things. For example, theses & dissertations have authors. Authors are in schools. And schools are a part of colleges. These things can be combined as sets of nodes and edges, measured, and visualized. In this case, we can first see how degrees, schools, and colleges are related. The College of Arts & Letters includes many disciplines, for example. Second, the nodes and edges can be "clustered", in a process similar to topic modeling, and we can see how they fall into four major neighborhoods: doctoral degrees, masters degrees, humanities schools, and sciences schools:
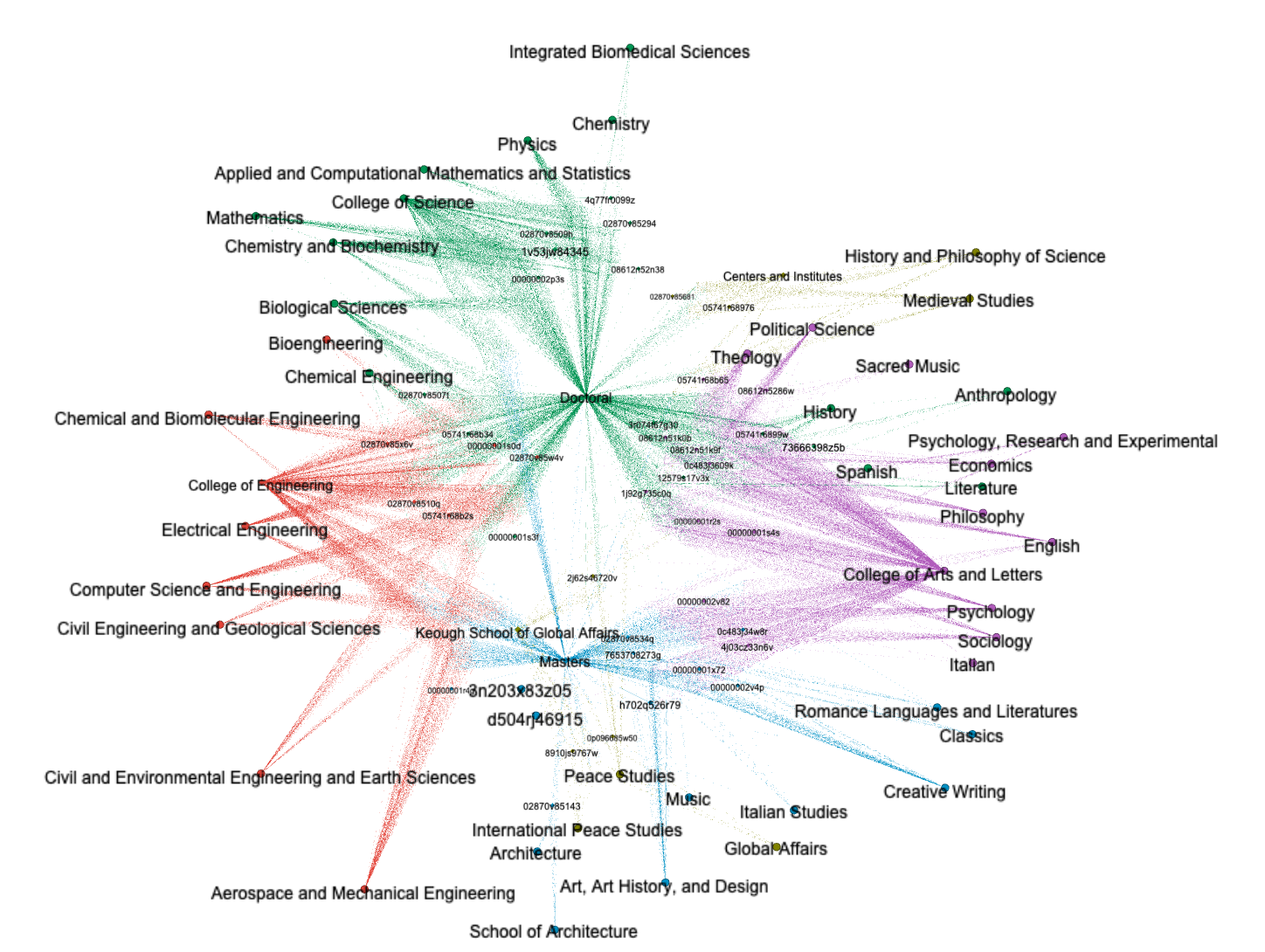
I took it upon myself to analyze the University of Notre Dame theses & dissertations from 30,000 feet. I was surprised at the ratio of science to humanities degrees earned, and I ask myself, "To what degree do the Libraries's collections and services align with the scholarship being done?" I don't really know the answer to this question, and I suppose it depends on the definition of "collections and services". I believe discussing such definitions would be interesting.
Finally, the entire data set -- raw data, tabulations, models, and visualizations -- used to do this analysis can be downloaded from http://carrels.distantreader.org/curated-theses_and_dissertations-2023/index.zip. The resulting files are amenable to a wide number of desktop applications, database programs, and software tools. Download the file and do your own analysis?
Eric Lease Morgan <emorgan@nd.edu>
Navari Family Center for Digital Scholarship
Hesburgh Libraries
University of Notre Dame
Date created: June 28, 2023
Date updated: June 1, 2024