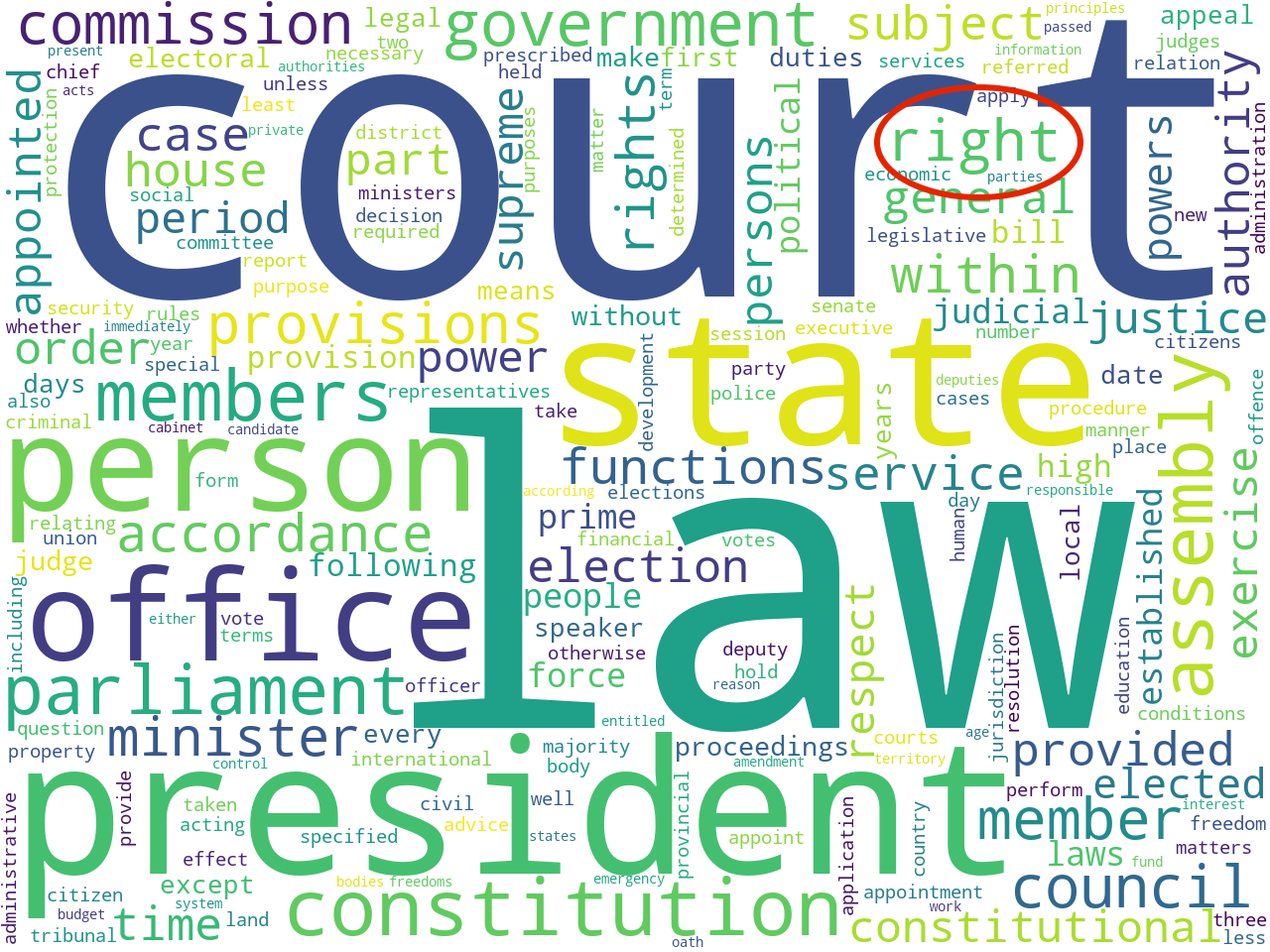
unigrams and bigrams
I wrote the following missive almostd a year ago, and since then I learned the topic of our study was not "human rights" but "human values". That said, one still needs to get an understanding of one's content prior to in-depth analysis, and the following provides just that sort of context. Moreover, the computed summary page still has a great deal to offer. Finally, this data set ought to be available for downloading at http://carrels.distantreader.org/curated-world_constitutions-other/index.zip --Eric Lease Morgan (December 2, 2024)
A friend and colleague (Jarek Nabrzyski) asked whether or not I would be able to compute the degree world constitutions embodied the ideals of human rights, and this missive outlines my successes or lack thereof.
More specifically, I charged myself with the task of measuring "human rights-ness" in world constitutions. To accomplish this task I thought I could count & tabulate the relative frequency of words/phrases connoting human rights in world constitutions, and then address the question, "What country's constitution embodies the greatest degree of human rights?" In the end, I believe the measurements are counter-intuitive.
To do this good work, I first needed to create an as comprehensive collection of world constitutions as possible, and I believe I found such a collection at Constitute. Upon perusing their collection of constitutions, I discovered each constitution was available in three formats: 1) PDF, 2) HTML, and 3) XML. I proceeded to download/cache each, which you can peruse them for yourself: pdf, html, and xml.
To do text mining or natural language processing against a file one must have plain text, and while it is possible to extract the plain text from PDF and HTML files, I found the plain text extracted from these formats to be less than satisfactory. For example, the PDF files contain an abundance of commentary which I did not need nor want, and the plain text extracted from the HTML files seemed inconsistent. In the end I programmatically extracted the desired plain text from the XML files, and the result can be found in the txt directory -- the local corpus of files which will be computed upon.
My next step was to become more familiar with the corpus's size and scope, and to do this work I employed a locally developed tool called the Distant Reader. The Reader takes an almost arbitrary number of files of any type as input, extracts the documents's plain text, applies feature extraction against each document, and distills the results into a platform- and network-independent data set. These data sets are affectionately called "study carrels". Given a study carrel the student, researcher, or scholar is then able to address all sorts of research questions using a myriad of graphical user interface applications, Web interfaces, or application programmer interfaces of just about any computer language. For example, I have used the Reader to address research questions such as: how do students discern their college major or their career path, to what degree does presidential political pressure effect the actions of the Federal Reserve Bank, or what are some of the similarities and differences in a given set of 600 Victorian novels.
After applying the Reader to the collection of constitutions, I learned a number of things. For example, there are 193 items in the collection, and the total size of the collection -- measured in words -- is about 4.7 million. Thus, on average, each constitution is about 2,400 words long. By way of comparison, many scholarly journal articles are between 5,000 and 6,000 words long, Melville's Moby Dick is .25 million words long, and the Bible is about .8 million words long. Put another way, the corpus is about the size of 59 Bibles.
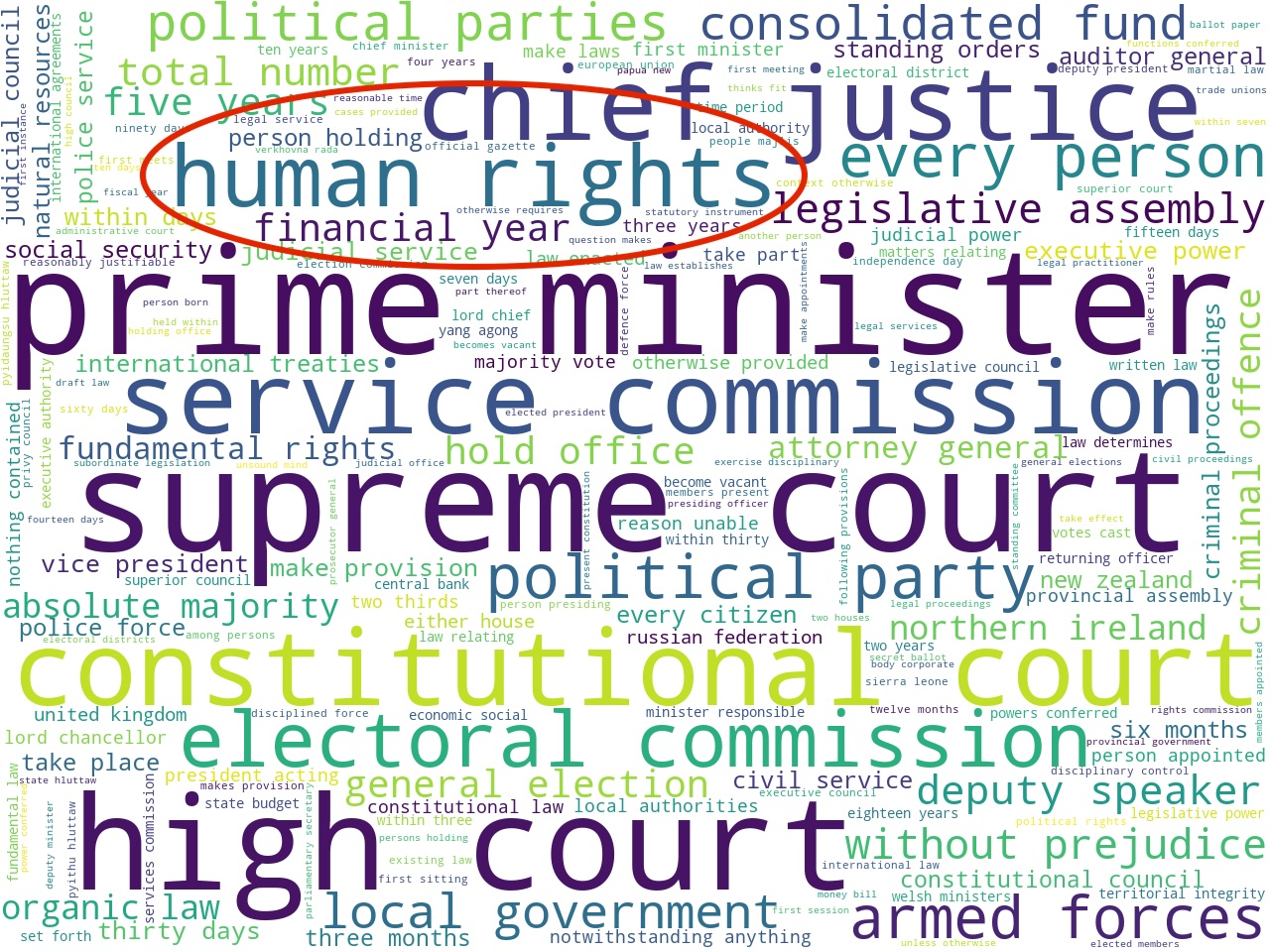
To determine the scope of the corpus, I applied a number of modeling techniques. For example, I counted & tabulated the most frequent unigrams and bigrams (one-word, and two-word phrases). Using other techniques I extracted the most frequent names of organizations as well as a set of statistically significant keywords. Visualizing these results as word clouds, these models: 1) help the uninitiated garner a broader understanding of the corpus, and 2) help the person familiar with constitutional law articulate details.
unigrams and bigrams

nouns and proper nouns
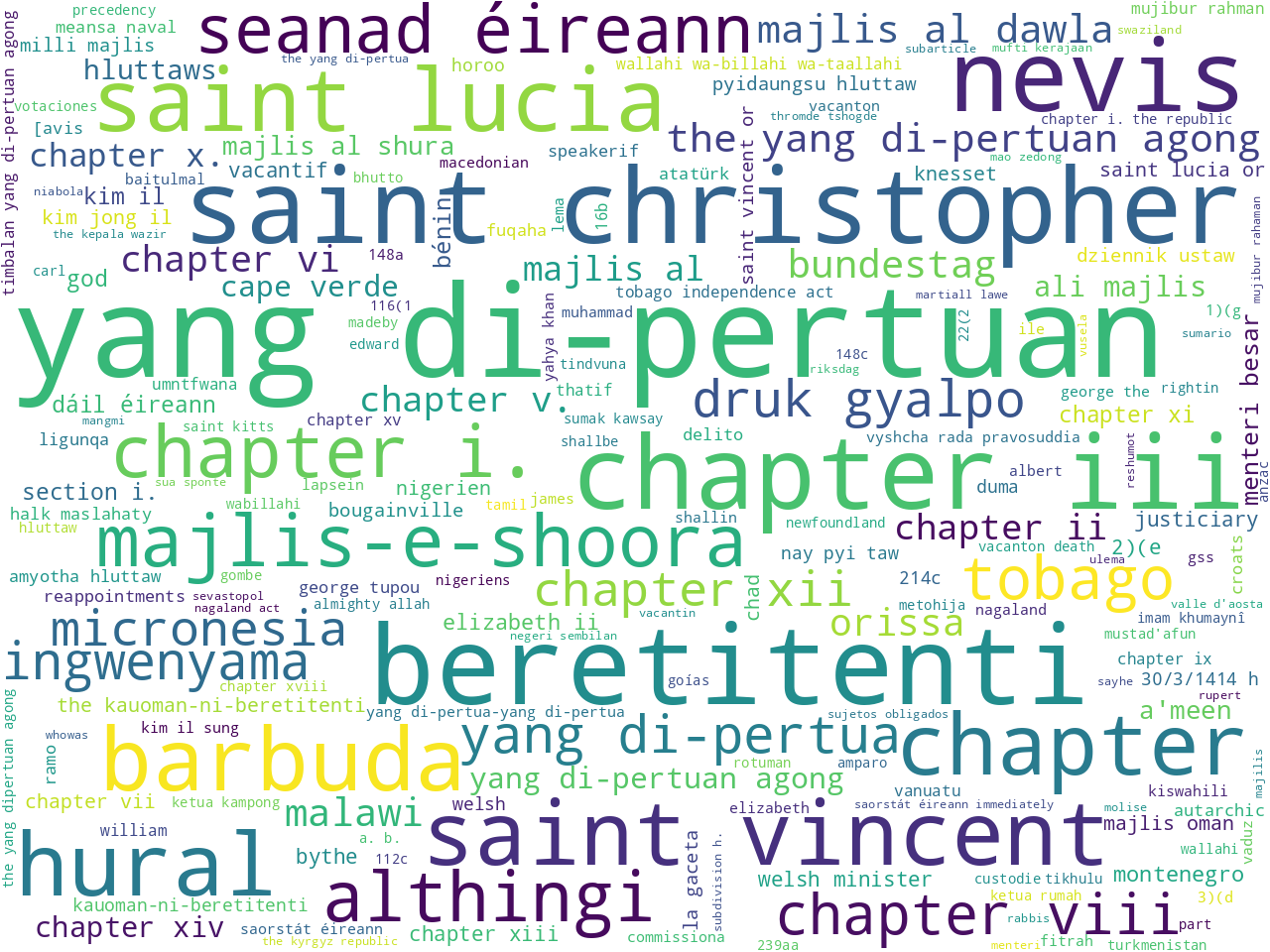
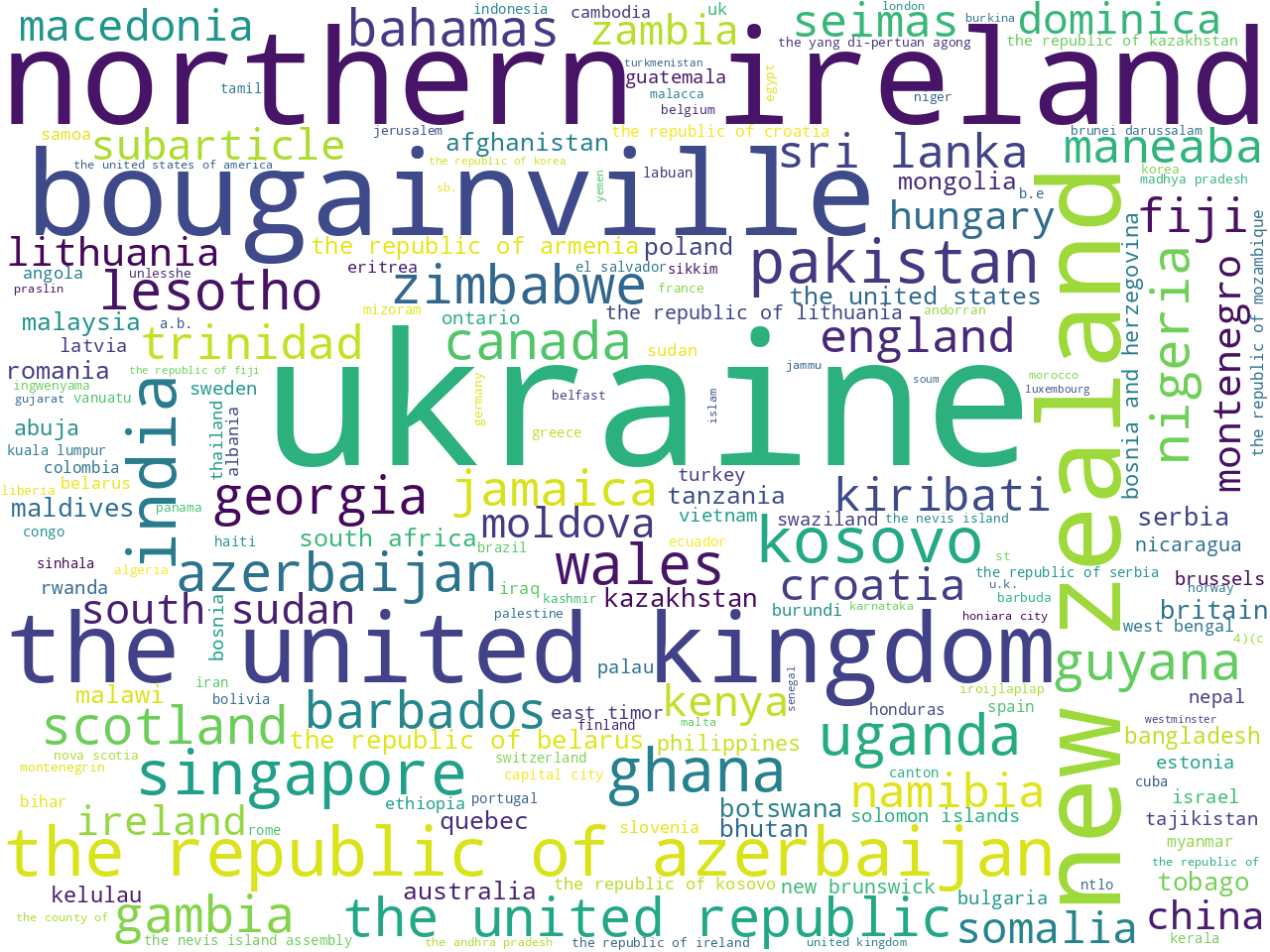
persons and geo-political entities
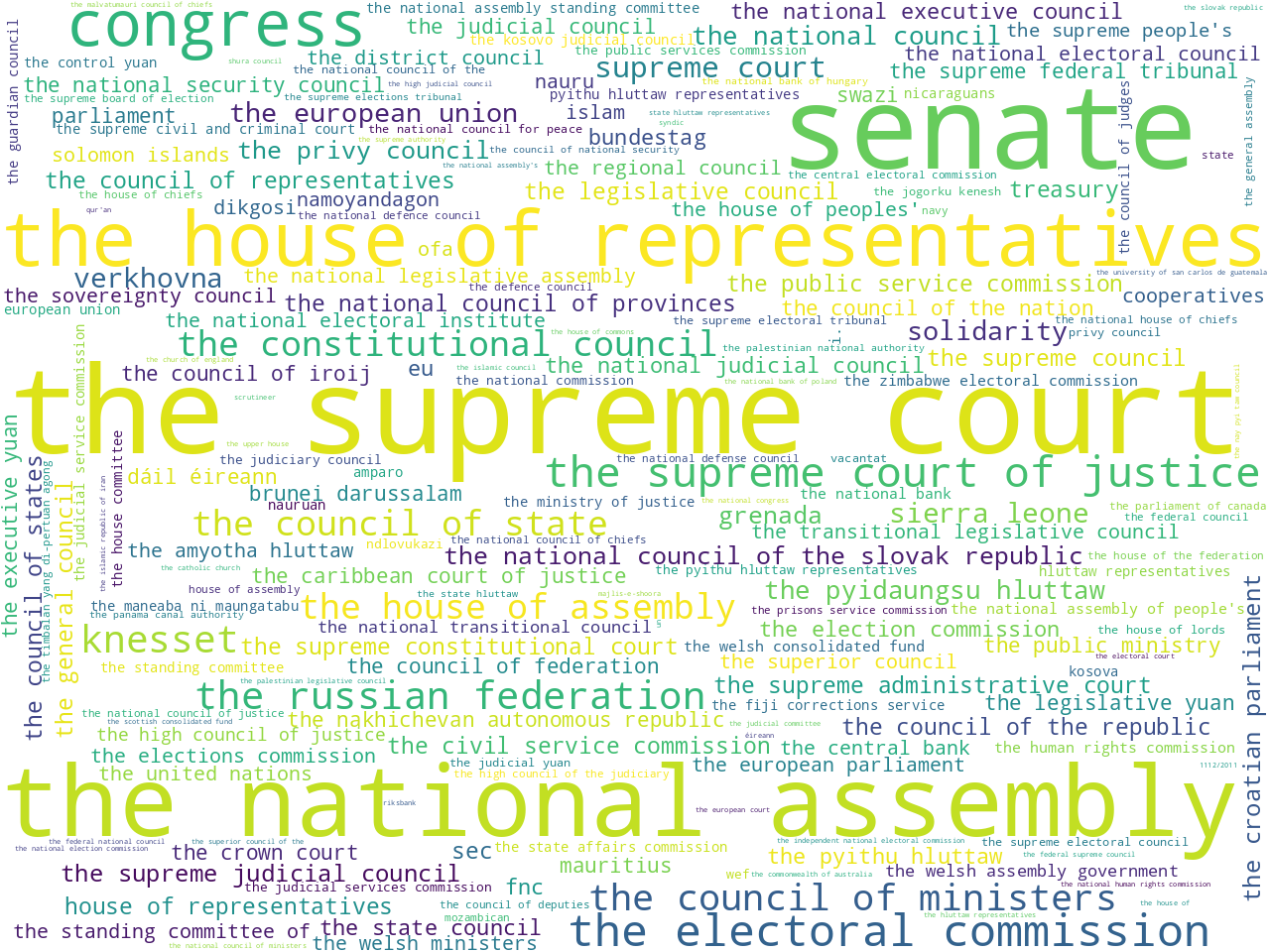
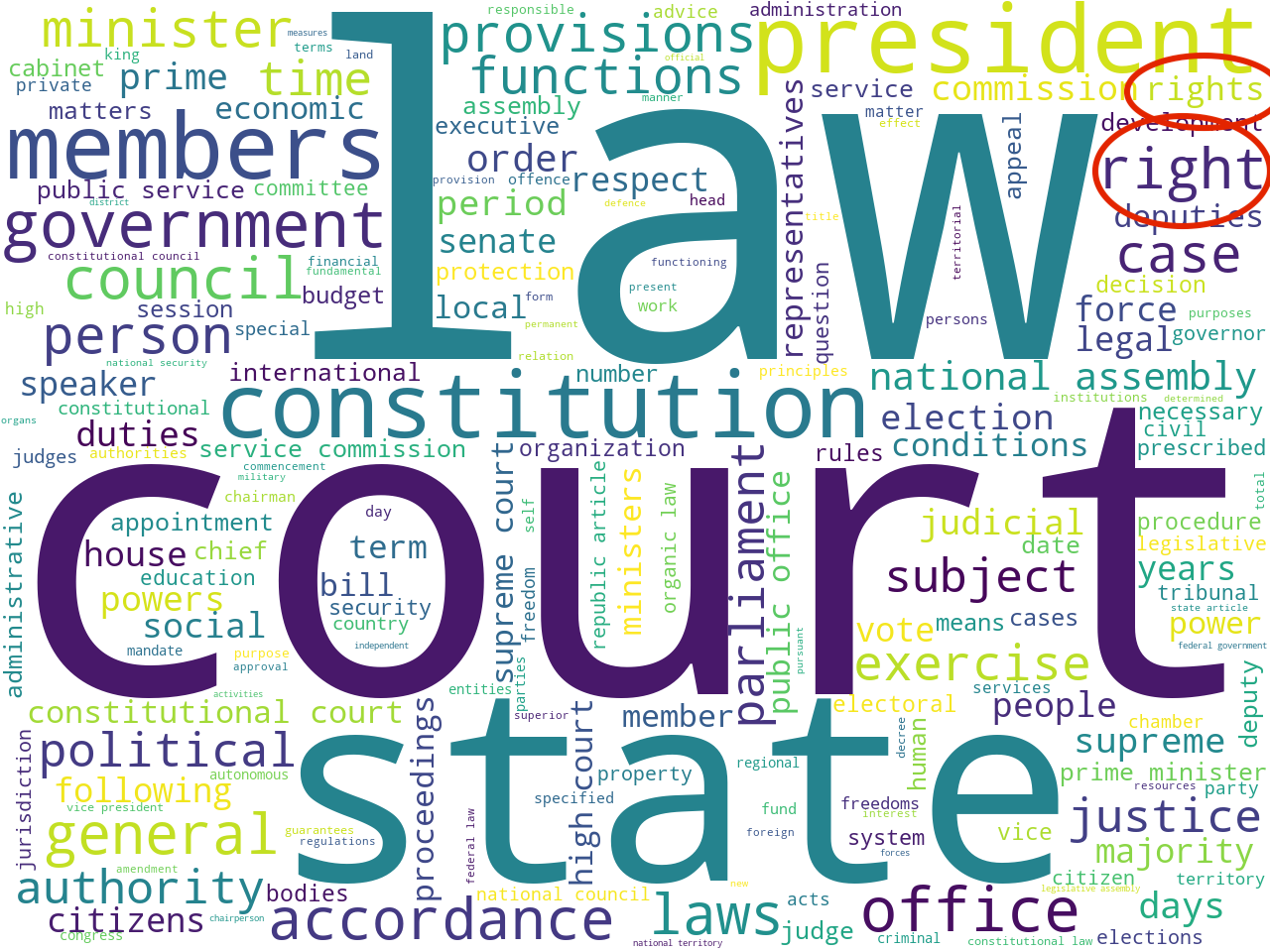
organizations and keywords
(The Reader creates a generic report against any and every study carrel, and the report hightlights many of the carrels' extracted features, like the ones above. For more detail, see the generic index page.)
Topic modeling is another technique used to determine scope. [3] After augmenting the stopword list with frequently occurring non-noun words, and after denoting twelve as the number of topics to enumerate (simply because twelve is an easy number of topics to visualize), the following themes and pie chart presented themselves. This of topics as if they were "themes":
topics weights features
law 0.37606 law state assembly rights right president coun...
president 0.23961 president office person court constitution par...
assembly 0.18298 president law assembly council court constitut...
government 0.17196 law government members provisions laid committ...
state 0.14389 law state congress constitution established ge...
house 0.10213 state law house representatives president coun...
court 0.10158 court person electoral commission party electi...
person 0.08694 person office law court constitution member mi...
right 0.07397 law state president right constitution court c...
parliament 0.07244 parliament government constitution provincial ...
council 0.03844 state law house council federation court const...
provision 0.02342 court assembly provision order person lord ire...
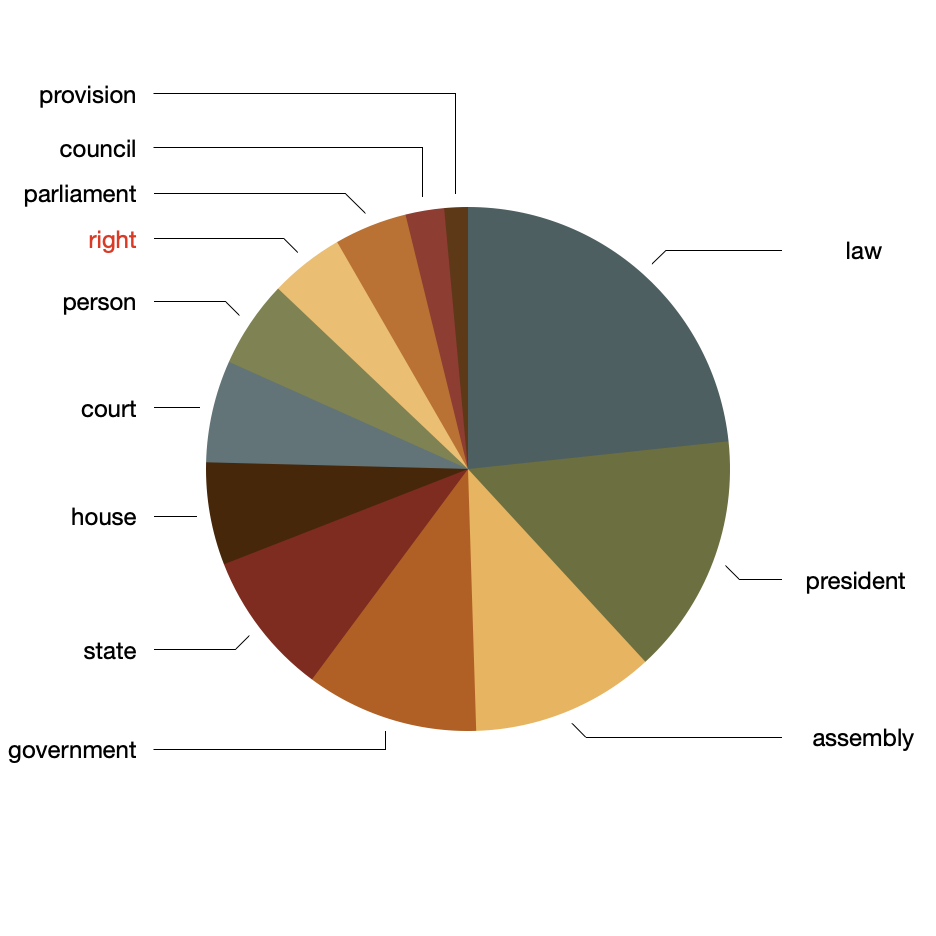
From the results, above, we can see the corpus is not about human rights, per se, but instead about the things and workings of governments. Human rights plays a role, but not an overwhelming one. Thus, if the concept of human rights is not a major theme in the corpus, then measuring its degree may be challenging. You can't measure something that doesn't exist. That said, there are still many ways to learn how the idea of human rights is manifested.
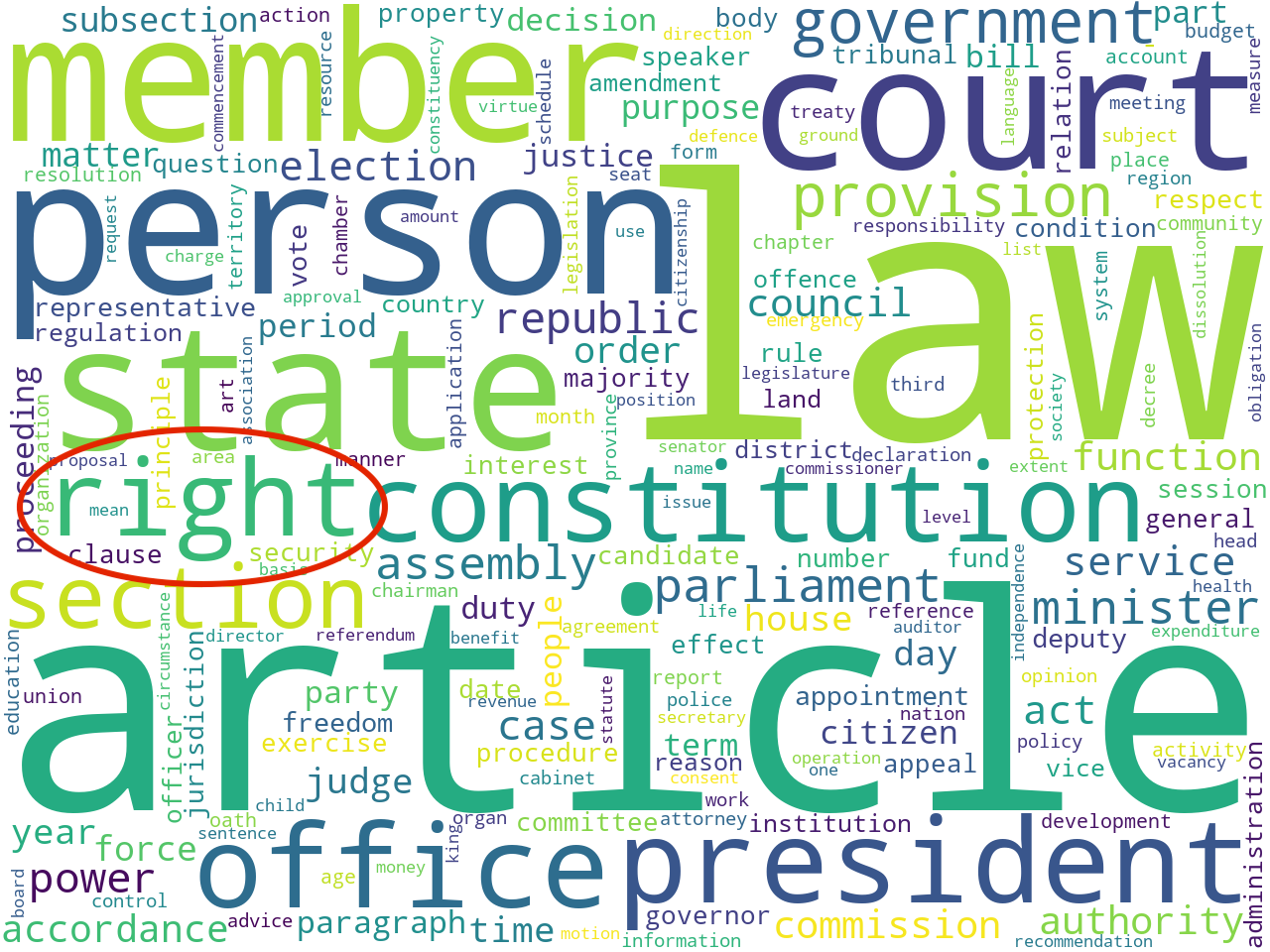
For example, the word "right" manifested itself as a statistically significant keyword; the word "right" is statistically associated with many of the constitutions. This can be visualized at a network graph where nodes are constitutions or keywords, and edges denote when a constitution is described by a keyword. In our case, below, countries/constitutions are brown and keywords are gray. The more central the keyword, the more often it is held in common by different countries. The size of each label connotes the number of associations it has with other nodes. Thus, as predicted by the previous modeling techniques, the corpus is about "government", "members", "law", "court", "state", etc. We can also see the presence of "rights" words, but not many. Moreover, we can see what countries/constitutions are associated with the words "right" and "rights". The United Kingdom is highlighted because it is not associated with the words "right" nor "rights".
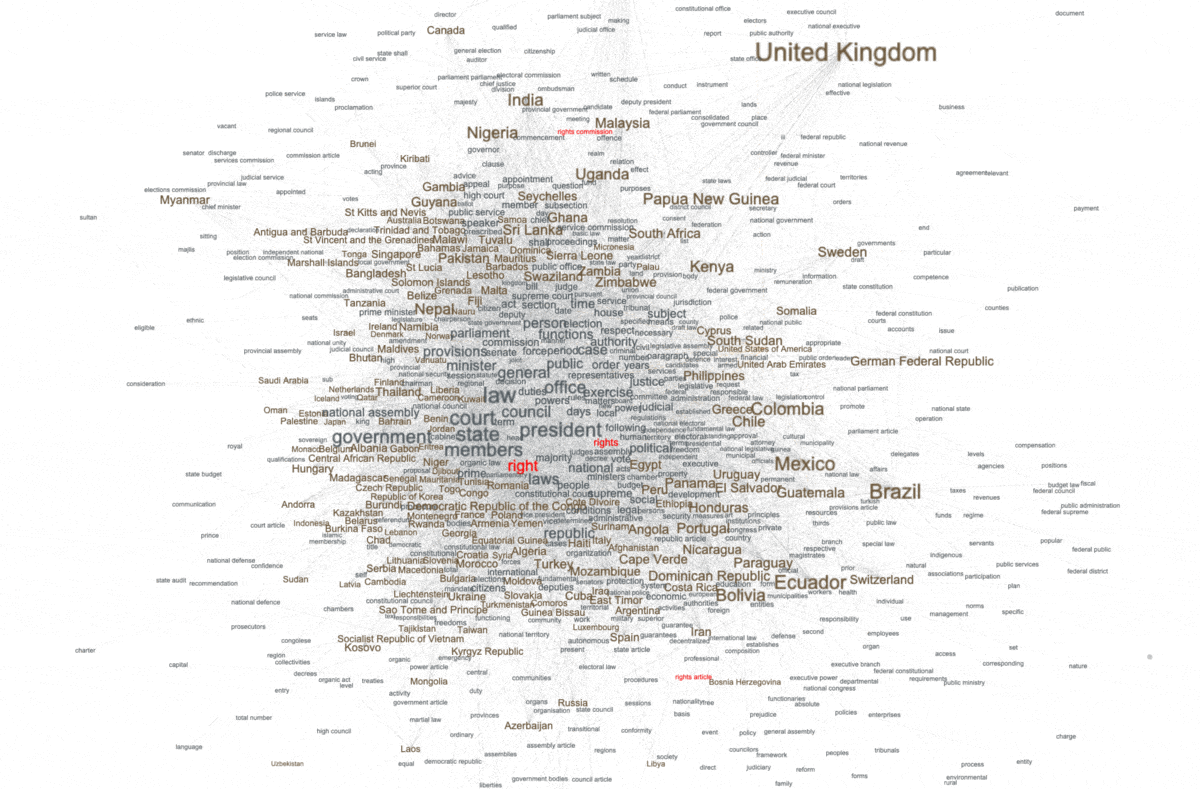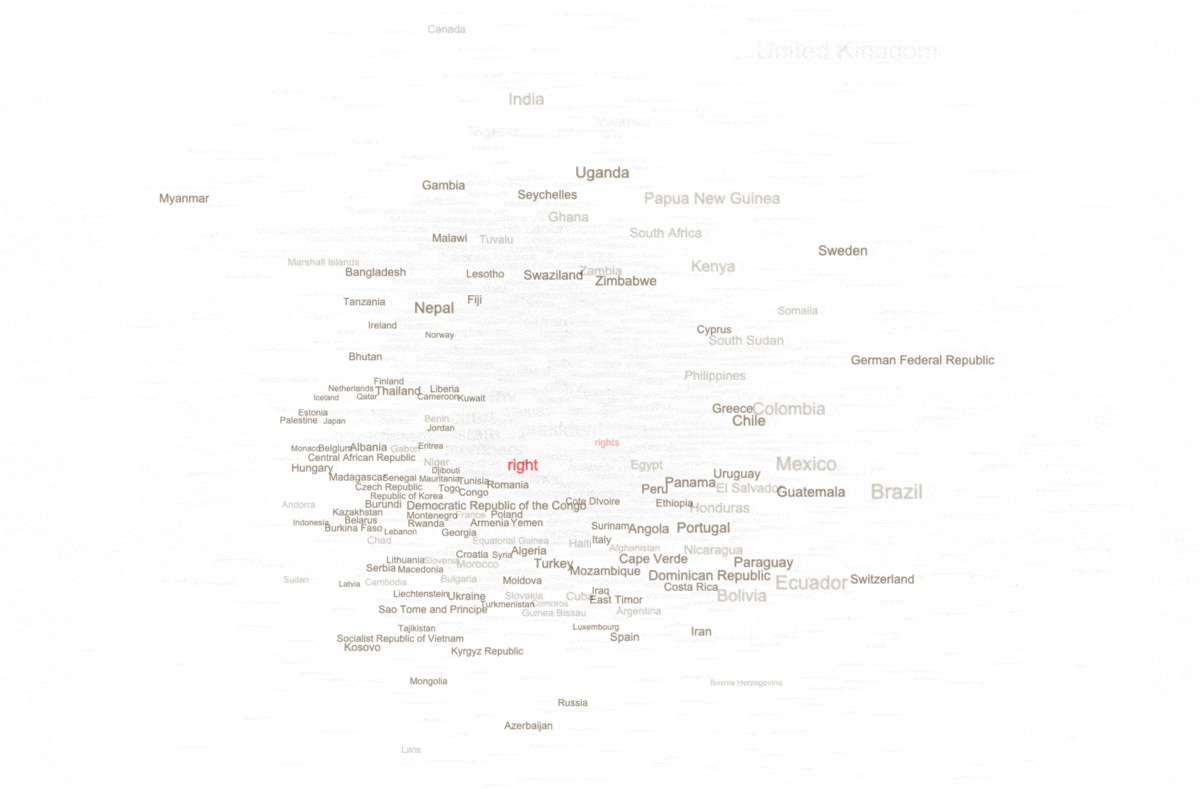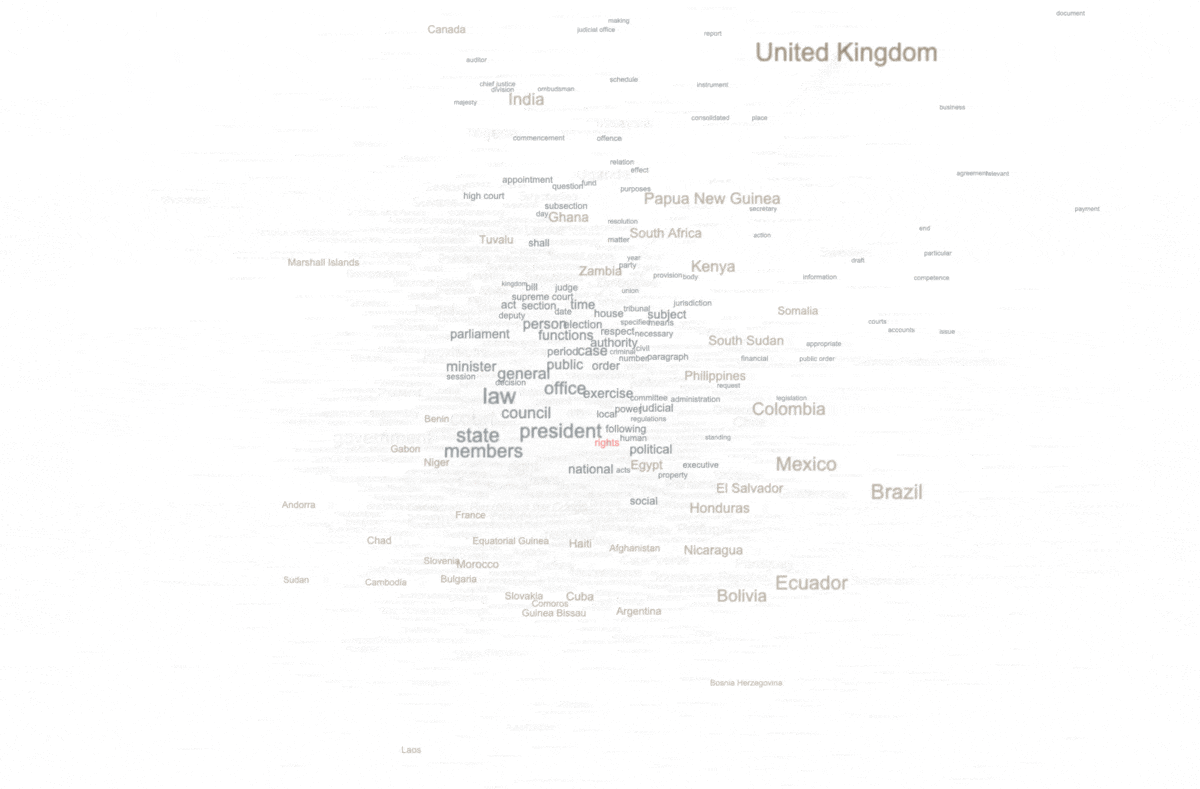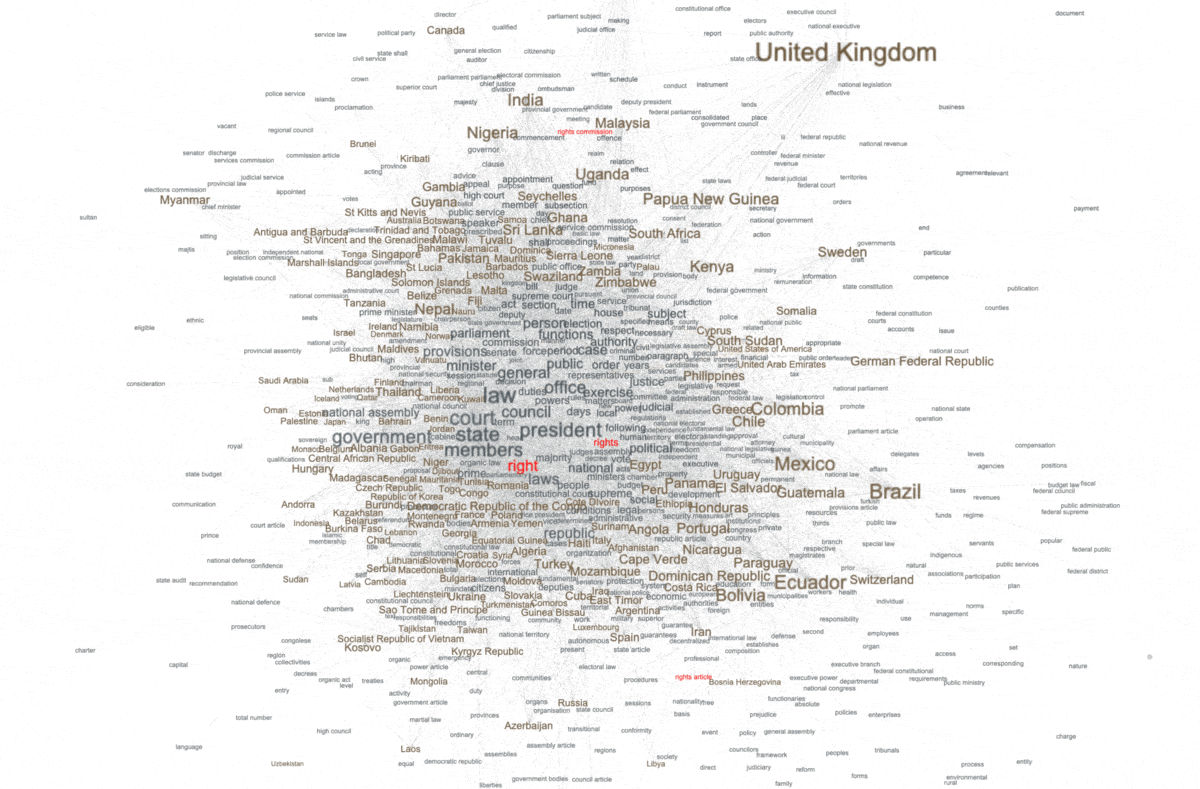
keywords, specifically "right" and "rights", and their relationship(s) with countries/constitutions
In order to measure "human rights-ness" we need sets of words connoting the idea of human rights, and we call such a set of words a lexicon. To paraphrase John Firth, a famous linguist, "You shall know a word by the company it keeps." Thus, in order for us to know the meaning of human rights in the context of the constitutions, we ought to examine the words surrounding the phrase "human rights".
Moreover, since words are merely proxies for ideas, all lexicons are imperfect; langauge is both dynamic and ambiguious, and consequently, in more cases than not, words only approximate the true meaning of an idea. With these things in mind, it is irresponsible to make our observations or take our measurments sans a more accurate and more comprehensive lexicon; we need more than the words "human" and "rights" in order to do our evaluations.
That said, there are basically two ways to posess a lexicon: 1) to be given one, or 2) to compute one. In both cases, lexicons can be augmented in a number of different ways. In the end, I will use three lexicons for my measurements. One is rooted in a lexicon given to me by Jarek; I will very much use the given words sans any modification. The second is rooted in the content of the Universal Declaration of Human Rights; I will make the imperfect assumption the Declaration is the perfect constitution. The third lexicon will be computed against the words in the corpus of constitutions.
A rudimentary way to accomplish the third option is through the use of concordance: query for a word or phrase, output the words around the given word/phrase, count & tabulate the results, and visualize. Below is the result of such a process, and apparently, when the phrase "human rights" is written, so are the words "freedoms", "commission", "fundemental", etc.:

tag cloud of words surrounding the phrase "human rights" in the set of constitutions
Another way to accomplish the same task is by creating a network graph of bigrams containing the words "human" and "rights". This is akin to a process called collocation. To model the text in this way we: find all bigrams where one of the ngrams is a given word, count & tabulate the result, create a graph where each node is the pair of ngrams and the edge is their frequency, and visualize the result. Using this technique similar but different results manifest themselves. We are particularly interested in the words common with "human", "right", and "rights", and notice how some of the words from the previous technique are echoed below:
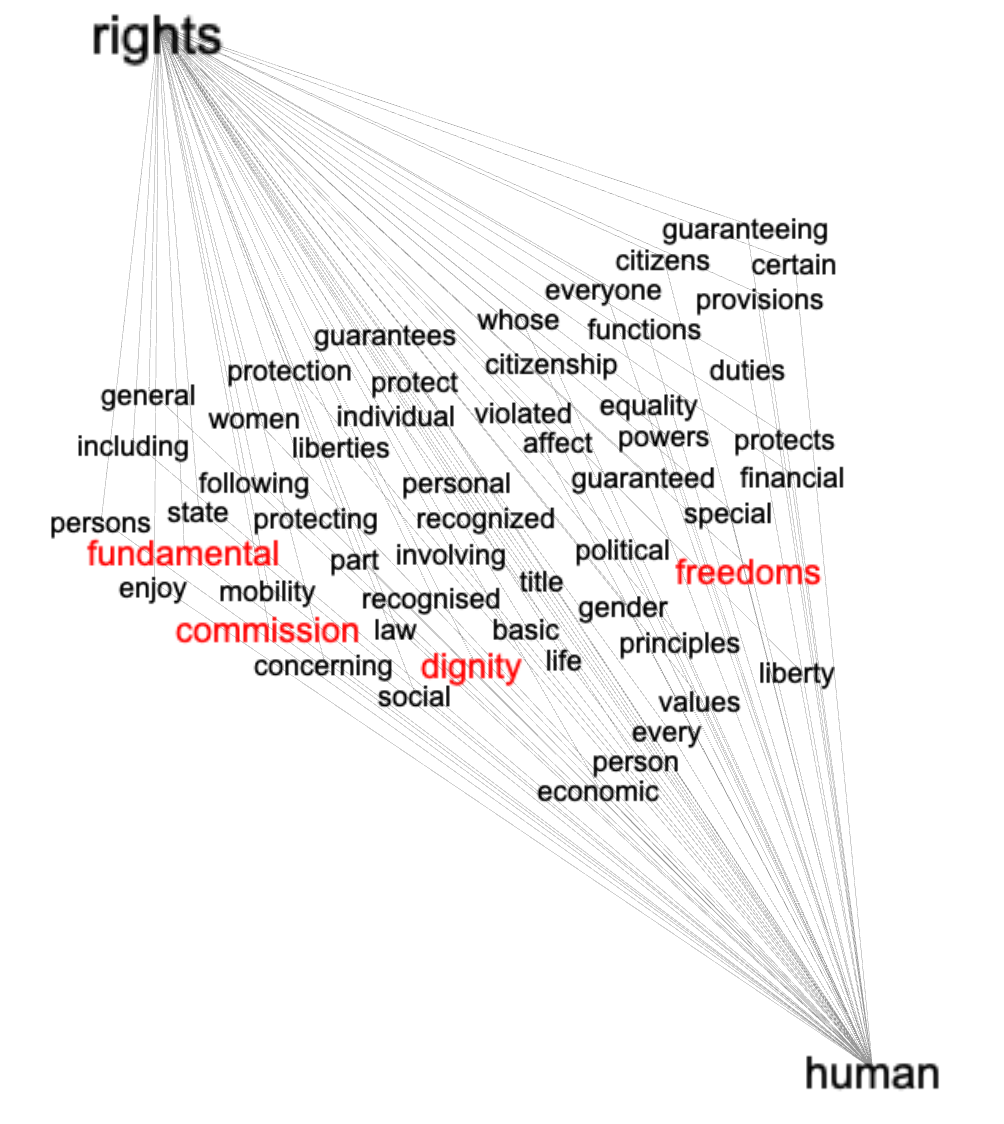
words in common of the bigrams containing "rights" and "human"
A more modern way to determine what words are used in conjunction with other words is through the use of word embedding or what is sometimes called "semantic indexing". Semantic indexing is a process of vectorizing words, plotting them in an n-dimensional space, and calculating the (cosine) distance between them. Vectors (words) pointing in similar directions are considered to be words spoken (or written) of a similar nature or have similar connotations. After modeling the constitutions in this way, searching for the words "human" and "rights", and identifying additional words pointing in similar directions, we identify even more words used in conjunction with phrase "human rights". Again, the words and their associations are visualized, below, as a network graph:
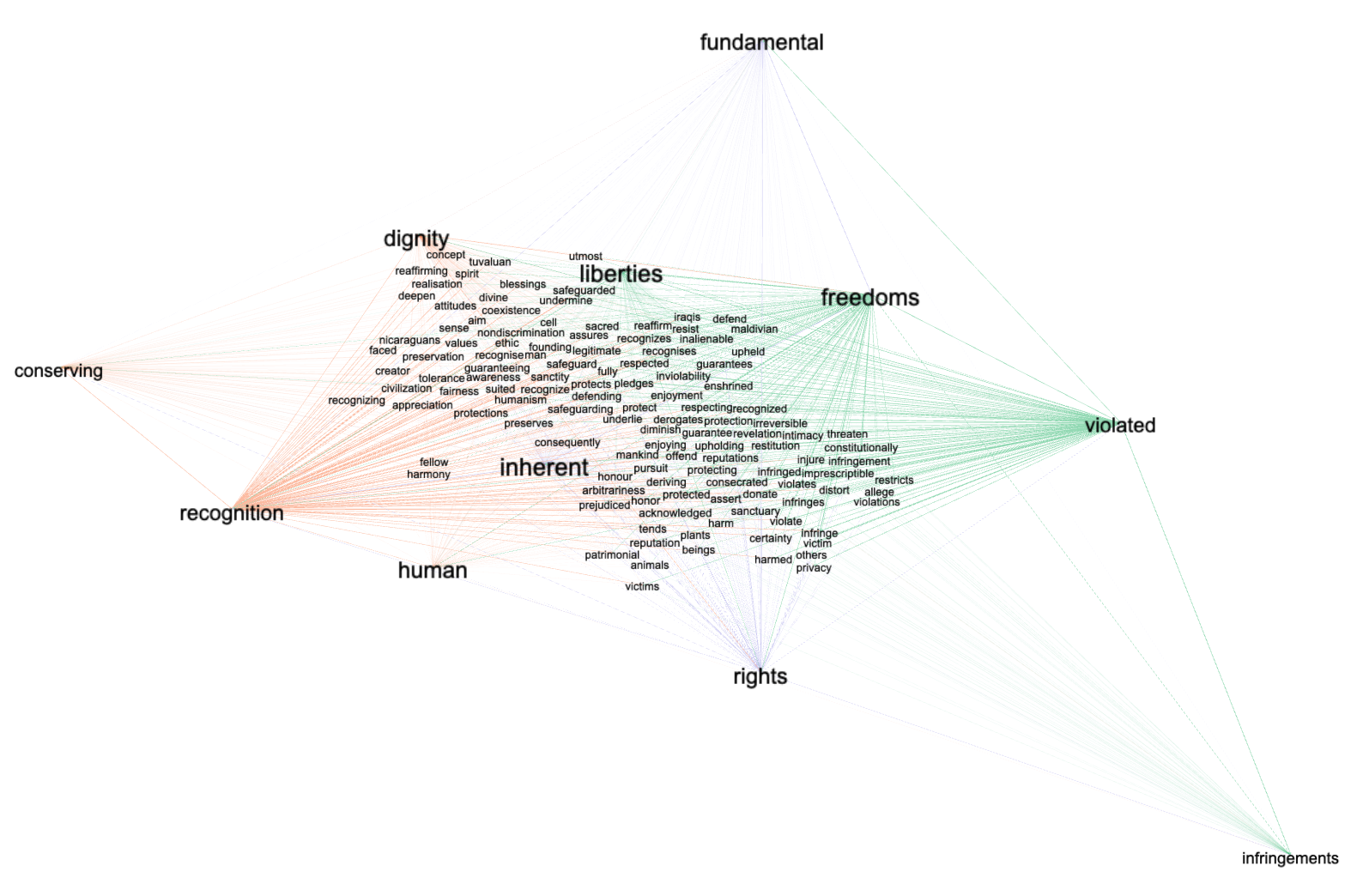
after semantic indexing, visualizing the words used in conjunction with the words "human" and "rights"
This data set was created using a tool called the Distant Reader Toolbox, and the whole of the data set ought to be available for downloading at http://carrels.distantreader.org/curated-world_constitutions-other/index.zip.
Eric Lease Morgan <emorgan@nd.edu>
Navari Family Center for Digital Scholarship
University of Notre Dame
October 31, 2023