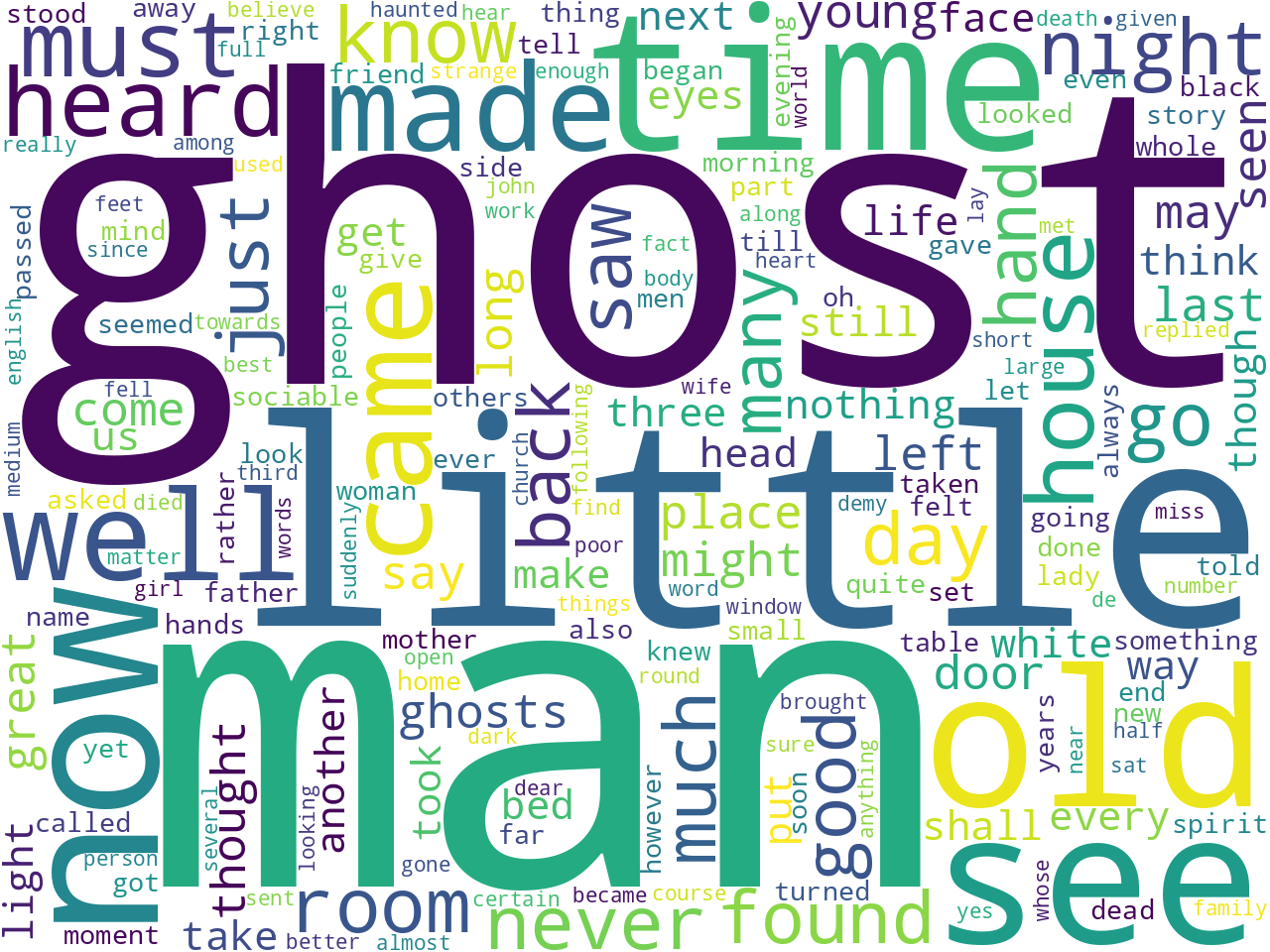
Unigrams
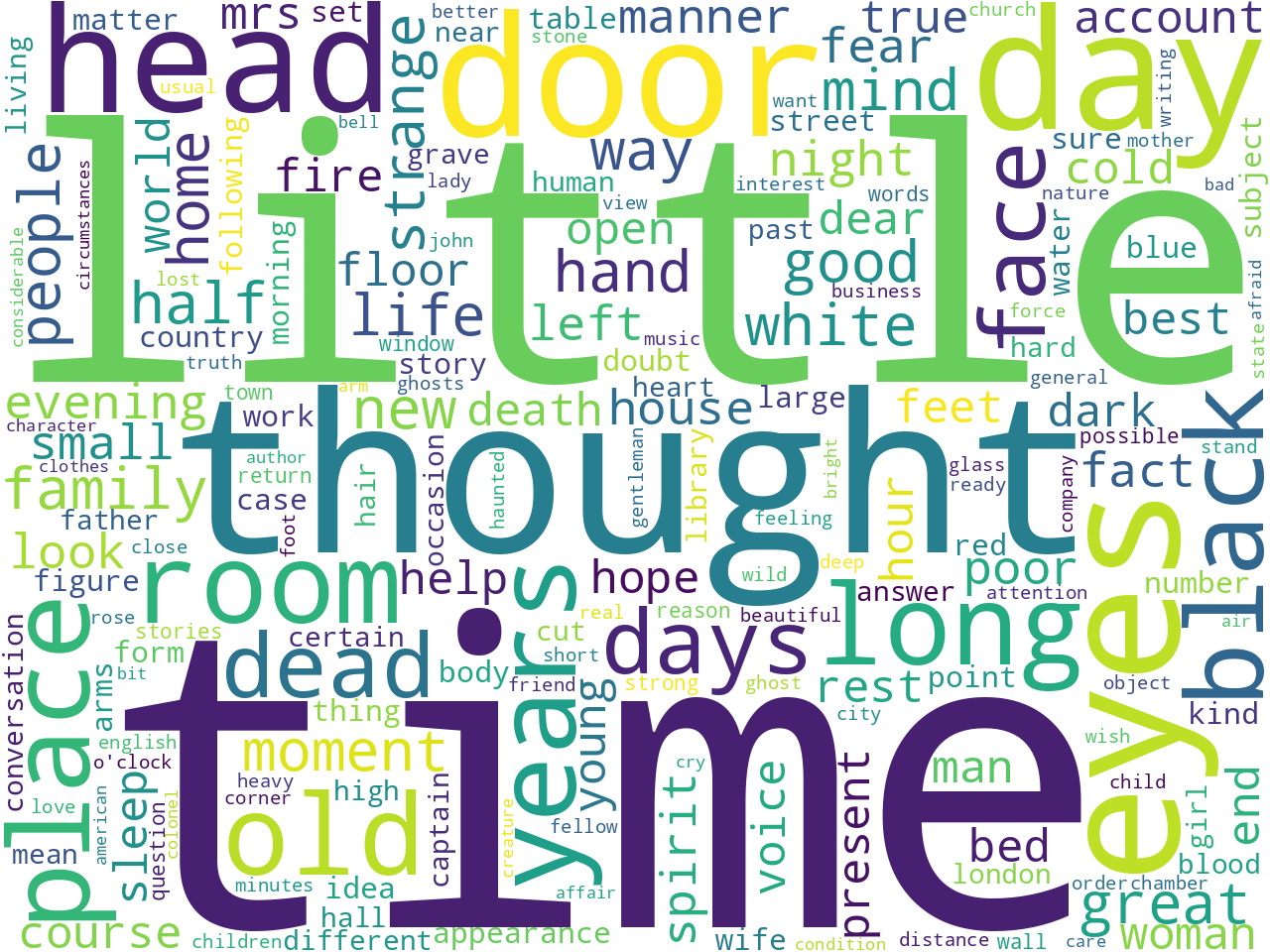
Keywords
Just for fun, let's read a HathiTrust collection called HaunthiTrust.
The collection was created by Miranda Bennett, and she posted it to the one of the HathiTrust Slack channels. From her posting:
Spooky Season fun in the HTDL: I'm putting together a collection called HaunthiTrust to assemble Full View items with Halloween-ready illustrations. Looking for an ominous Zoom background? I recommend pulling an image from Haunted houses: tales of the supernatural, with some account of hereditary curses and family legends
While the purpose of the collection is/was to assemble illustrations, I couldn't help but to do some analysis against.
The collection includes 13 documents for a total of 600,000 words. (By comparison, Moby Dick is about 200,000 words long.) Coming in at an average readability score of 80 (where 0 is impossible to read and 100 readable by anybody), the documents are pretty readable. Ngram and keyword analysis begin to allude to the collection's aboutness -- ghosts. Duh!
Unigrams |
Keywords |
Peruse the rudimentary bibliography (complete with computer-generated summaries and keywords), as well as the simple analysis for more details. All of the original PDF files are saved in the cache.
After looking more closely at the ngrams and keywords, I asked myself "What are ghosts, and how are they described?" To answer the question, I appplied concordancing to the collection for the words "ghost", "ghosts", "spirit", and "spirits". I saved the results to a plain text file, removed the query words, and illustrated the result as a simple word cloud, which addresses the question, "When the words ghost or spirit are used, what other words are mentioned in the same breath?" The answer is illustrated below, and upon further investigation, some of the ghosts in the collection have names such as The Sociable Ghost, The White Ghost, and The Canterville Ghost:

Another way to accomplish the similar goal it so output counts of bigrams and filter them with the query words. The result is a three-column table (source, target, and weight) that can be visualized as a network diagram. From the results, the words "ghost" and "ghosts" and "spirit" share a number of words. Notice also how the words "white" and "canterville" are heavily weighted to the word "ghost":

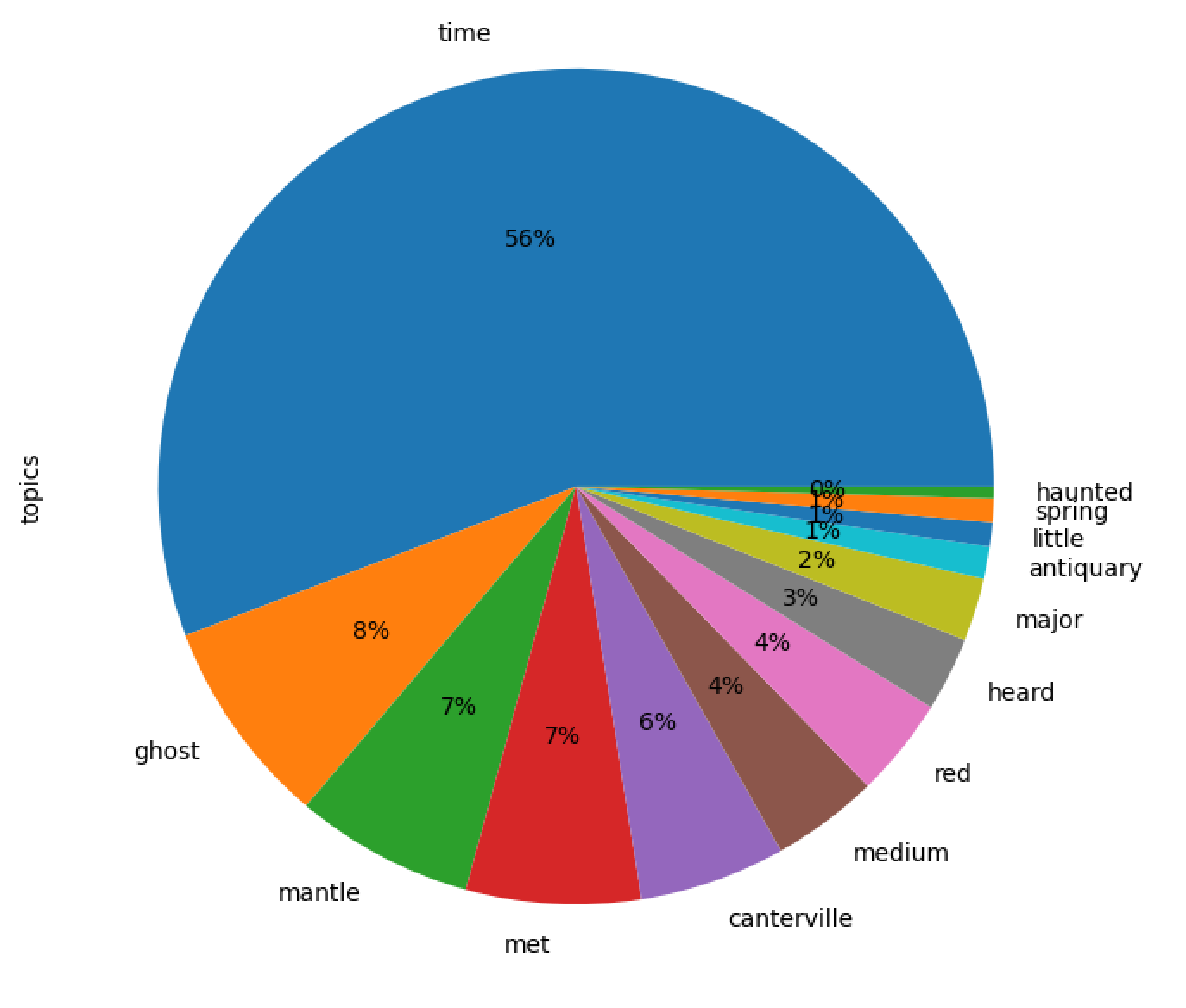
Next I wanted to see the degree each item in the collection where distint from every other item. To address this challenge, I first applied topic modeling to the corpus. Since there are 13 items in the collection, I denoted the enumeration of 13 topics. The resulting topics follow:
| labels | weights | features |
|---|---|---|
| time | 1.67466 | time now man see old little well made |
| ghost | 0.24092 | ghost sociable man young ghosts around know th... |
| mantle | 0.20769 | ghost mantle green stories wilmsen emmeline me... |
| met | 0.20282 | met ghosts others barker parton dawson thing s... |
| canterville | 0.16960 | ghost canterville halloween mrs otis children ... |
| medium | 0.12423 | medium phenomena madame blavatsky spirit table... |
| red | 0.11550 | red white give blue eye spectre light green |
| heard | 0.08639 | ghost heard room house white bed seen told |
| major | 0.07318 | major jones alive old mary indians camp thaw |
| antiquary | 0.03733 | antiquary ghost-stories number parkins abbot a... |
| little | 0.02795 | little demy ghosts library leather lady mother... |
| spring | 0.02745 | spring deceased due mamma dense blue guides alec |
| haunted | 0.01354 | haunted houfe introduction hung plain daunted ... |
In order to get an idea of the degree each topic is manifested in the collection as a whole, I created the following pie chart. As you can see, there is a domonante topic, and many subtopics.
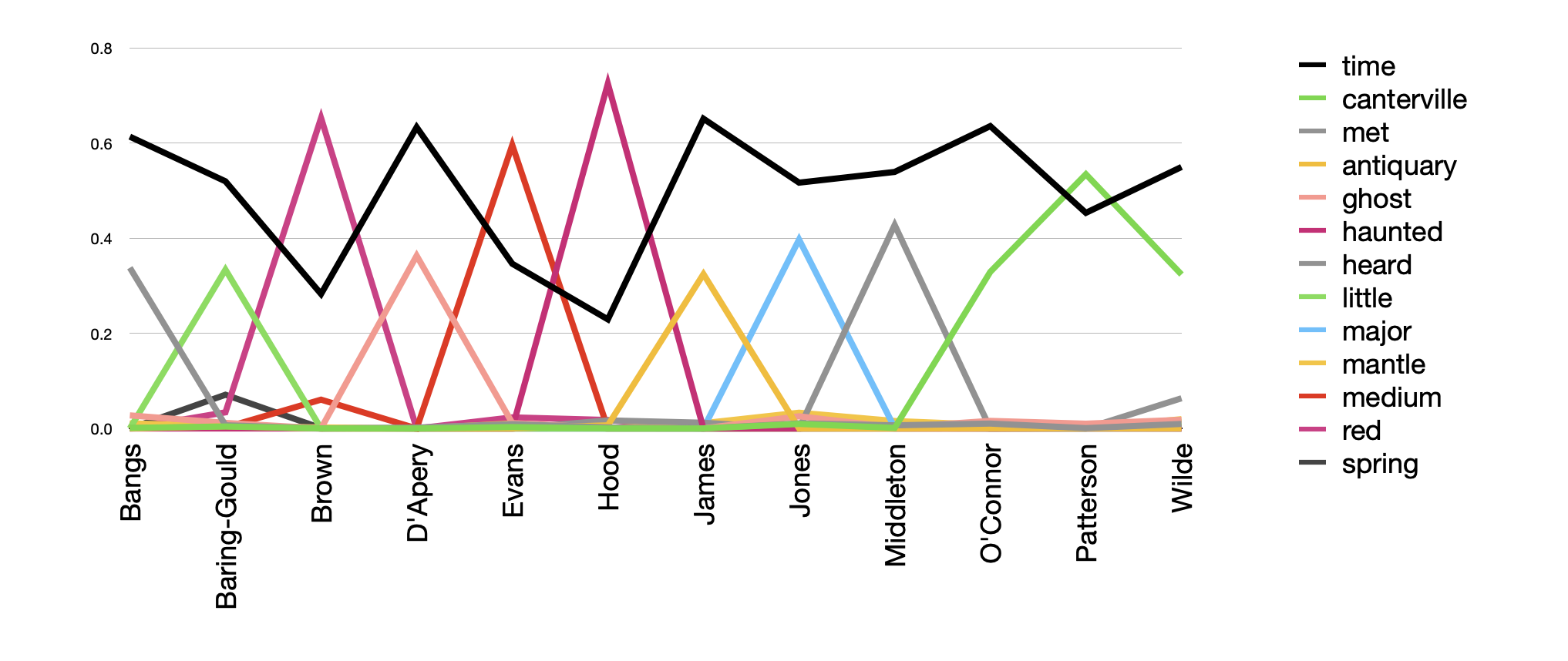
I then augmented the underlying topic model to include author names, pivoted the model, and plotted the result. With the exception of authors Brown and Hood, each author's name is associated with a distinct topic, and the topic of time-man-old-little is common throughout.
Need a recommendation on which stories to read about ghosts? Well, I searched the collection for items where the title includes the word ghost, the summary includes the word ghost, and the computed keywords included ghost. Based on the relevancy ranked results, consider:
This analysis was done using a suite of software called the Distant Reader Toolbox. The Toolbox creates platform- and network-independent data sets afffectionately known as "study carrels", and the study carrel used to do this particular analysis ought to be temporarily available at the following URL. Download it, and do you own analysis:
http://carrels.distantreader.org/curated-haunthi_trust-2022/index.zip
Fun with text mining, natural langauge processing, distant reading, and digital scholarship.
Eric Lease Morgan <emorgan@nd.edu>
Navari Family Center for Digital Scholarship
University of Notre Dame
Date created: October 10, 2022
Date updated: May 31, 2024