constitution unigrams
constitution bigrams
constitution keywords
This text outlines many of the how's when it comes to something I call Project Human Values. More specifically, it outlines:
This data set is really an amalgamation of two other data sets: 1) world constitutions, and 2) Blockchain documents. The process used to create these two data sets was very similar to each other:
In the end, each data set includes a number of things:
By definition, data sets are computable, and the Distant Reader Toolbox can compute against ("model") these data sets in a number of ways, including but not limited to: rudimentary counts & tabulations, full-text indexing, concordancing, semantic indexing, topic modeling, network graphs, and to some degree large-language models. For example, the following three word clouds illustrate the frequency of unigrams, bigrams, and computed keywords from the corpus of constitutions:
constitution unigrams |
constitution bigrams |
constitution keywords |
Whereas, these word clouds illustrate the frequency of unigrams, bigrams, and computed keywords from the Blockchain corpus:
 blockchain unigrams |
 blockchain bigrams |
 blockchain keywords |
To learn more about these individual data sets, see their home pages: 1) world constitutions and 2) Blockchain documents. Take note, because the two data sets are distinctive.
The same sorts of rudimentary frequencies (unigrams, bigrams and computed keywords) illustrated above can be applied to this combined data set of world constitutions and Blockchain documents. Upon closer inspection, these frequencies look a whole lot like the constitutions data set, but this is not surprising because the constitutions portion of the data set totals 4.7 million words or 86% of the whole:
 combined data set unigrams |
 combined data set bigrams |
 combined data set keywords |
Yet, by applying a variation of principle component analysis (PCA), and visualizing the result as a dendrogram, we can see there are two or three distinct sub-collections:
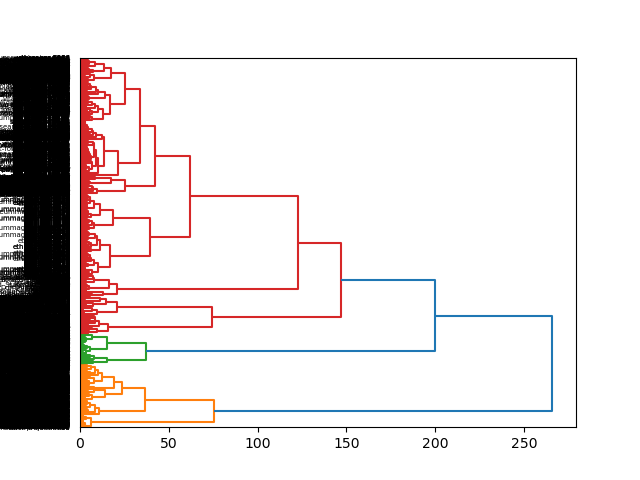 two or three distinct sub-collections |
The application of topic modeling illustrates the same point. For example, after arbitrarily topic modeling on twelve topics, the resulting themes include the following:
| labels | weights | features |
|---|---|---|
| ethereum | 0.11686 | ethereum user protocol blockchain system time people way security contract market network |
| hedera | 0.07101 | hedera hyperledger project network blockchain technology foundation blog community case event linux |
| contract | 0.06993 | contract eip ethereum transaction gas proposal improvement code value specification account address |
| proof | 0.0589 | proof transaction state datum node block chain shard contract ethereum tree rollup |
| block | 0.05481 | block validator transaction builder proposer time slot node fee chain mev eth |
| address | 0.04346 | address contract function token erc uint nft param return standard interface account |
| besu | 0.03167 | besu contributor call meeting release agenda time cookie content apac trust article |
| peer | 0.03107 | peer channel chaincode fabric node network organization transaction service datum policy configuration |
| law | 0.022 | law state article right president constitution case year government power court service |
| article | 0.01331 | article law president republic state right member court assembly government council constitution |
| person | 0.00962 | person court office section member parliament provision commission constitution law act minister |
| state | 0.00188 | state federation hluttaw union yang region pertuan que russian india uganda territory |
Visualizing the first two columns of the table, above, illustrate a mixture of blockchain and constituion-like themes. After augmenting the underlying model with a categorical variable for type of document (constitution or Blockchain), and after pivoting the underlying model, we can see what themes are associated with constitutions and what themes are associated with Blockchain documents. The blockchaing documents are much more diverse:
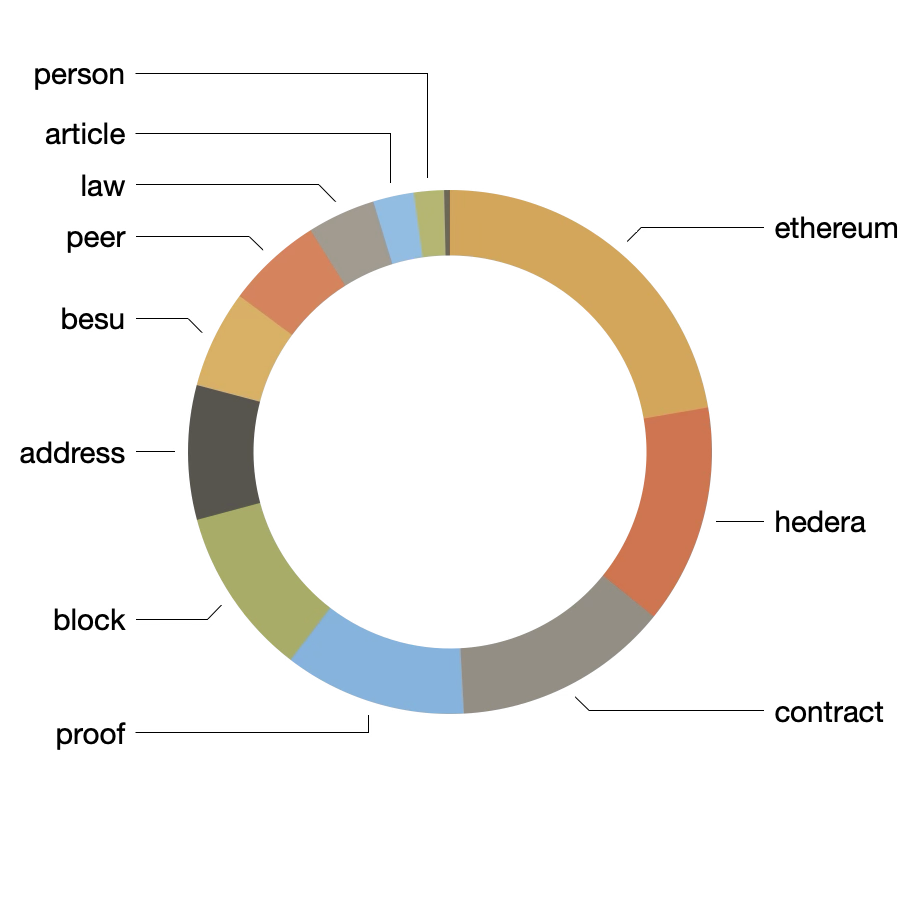 |
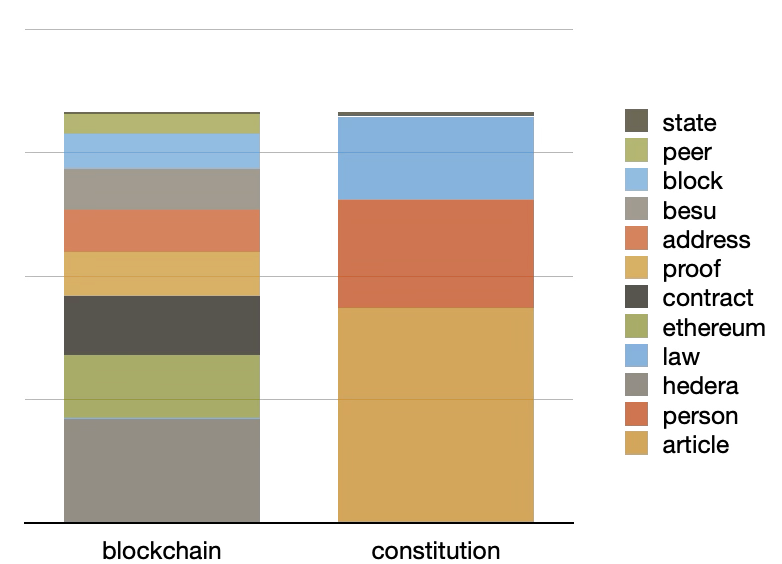 |
In short, the two data sets have been combined into a single data set, but they have retained their original character.
Our ultimate goal is/was to compare and contrast the human values in world constitutions and Blockchain documents. What values are mentioned? To what degree are these values mentioned? What values are mentioned in world constitutions but not in Blockchain documents, and vice versa? What values are shared between world constitutions and the Blockchain community? To address these questions, we created a named-entity extraction model, applied the model to our corpora, output measurements, and finally, articulated generalizations garnered from the measurements.
We took a semi-supervised approach to the creation of our model. It began by asking domain experts to create prioritized lists of human values from their domain. This resulted in two lists. Subsets of these lists (constitution and Blockchain) are below:
| constitutions | Blockchain |
|---|---|
| power | security |
| freedom | trust |
| order | transparency |
| unity | integrity |
| respect | privacy |
| justice | equality |
| equality | decentralization |
| security | consensus |
Because the meaning of words is ambiguous and depends on context, we used a thesaurus called WordNet to identify when a word alludes to a human value as opposed to something else.
For example, one of our given human values is "equality", but this word has many meanings. We looped each of our given human values through WordNet and extracted the associated definitions. We then read the definitions and determined which one or more of them alluded to human values as opposed to something like mathematics. When then took note of the definition's associated synset (think "identifier") and repeated the process for each value. This resulted in two new lists (constitutions and Blockchain), each in the form of a JSON file. Some of the items in the lists are shown below. Notice how each defintion alludes to values, and each defintion is associated with a different WordNet synset:
{
"power" : [
{"power.n.01" : "possession of controlling influence"},
{"ability.n.02" : "possession of the qualities (especially mental qualities) required to do something or get something done"}
],
"freedom" : [
{ "freedom.n.01" : "the condition of being free; the power to act or speak or think without externally imposed restraints" },
{ "exemption.n.01" : "immunity from an obligation or duty" }
]
}
We then use the Natural Language Toolkit (NLTK) to extract all the sentences from our data set, and then we created a subset of all our human values, specifically a subset of the higher prioritized items. We then looped through each sentence and created a subset of them each containing at least one of our human value words. We the applied the Lesk Algorithm (as implemented in the NLTK) to identify the human value word's synset value. If the value of the synset is in our dictionary of synsets, then the sentence was reformatted into a new JSON file denoting the offset in the sentence where the value is located and the sentence itself. This JSON form is something needed by the next step in our process. Here is an example of a reformatted sentence. The first posits a human value (respect) starting at character 88 and ending at character 95. The second posits another human value (transparency) starting at character 184 and ends at character 196:
[
["i never knew people could enjoy writing tests like you do, you've got my uttermost most respect.",
{"entities": [[88, 95, "HUMANVALUE"]]}
],
["since the start of the project, one of our primary dreams has been to not just deliver a world-class product, but also build a world-class organization, with quality of governance and transparency suitable for a foundation that would be tasked with helping to organize the maintenance of the ethereum code for potentially decades to come.",
{"entities": [[184, 196, "HUMANVALUE"]]}
]
]
We call these JSON files "annotations". They can be found at ./etc/annotations.json and they were created using ./bin/ner-find-and-disambiguate-values.sh and ./bin/ner-find-and-disambiguate-values.py.
Finally, we used spaCy to actually create our model. See: https://spacy.io/usage/training This entailed:
The training process is one of vectorization. Each sentence is tokenized, vectored, and associated with the string between the offsets. All of this is specified in a spaCy configuration file ./etc/ner-config.cfg. Along the way a model is saved to disk, compared to the testing set, and a accuracy score is returned. When all of the sentences have been vectorized the best version of the model is retained.
When we created our models based on only a few of the higher prioritized values, our accuracy scores were very high -- in the 90's, but the amount of sample data was small. If we created our model based on all of our prioritized values, then the model's accuracty was lower than 60%. To identify a balance between accuracy and representation, we iterated to Step #3 until the model was never lower than 75%. The resulting model, in the form of a .zip file, is located at ./etc/model-best.zip.
The entire process, from Step #1 to Step #4 is encapsulated in a single file -- ./bin/ner-build.sh -- and the log file of our most successful run is located at ./etc/ner-build.log.
Given our model, we then meaured the breadth and depth of human values in our data set, and the process was relatively easy:
This resulted in the creation of a tab-delimitd file allowing us to address our research questions. We can count and tabulate each value, and we can identify the union and intersection of the values in the different types of documents (constitution or Blockchain). All of the steps outlined above, as well as the resulting TSV file, are located at: ./bin/values2table.sh, ./bin/values2table.py, and ./etc/human-values.tsv.
This data set was created using a tool called the Distant Reader Toolbox, and the whole of the data set ought to be available for downloading at http://carrels.distantreader.org/curated-human_values-2025/index.zip. For more detail regarding Distant Reader study carrels see readme.txt.
Eric Lease Morgan <emorgan@nd.edu>
Navari Family Center for Digital Scholarship
Hesburgh Libraries
University of Notre Dame
May 7, 2025