I did some rudimentary investigations of public schools in New Orleans after extracting sets of documents on given topics, namely: black, charter, new, schools, and teachers. Below is an introduction to what I found.
First, I used the topic modeling process to divide the original corpus into 16 topics. Of those topics, five were identified as particularly interesting: black, charter, new, schools, and teachers. I then extracted the 100 most relevent documents (abstracts) from each topic, and I created a new data set -- this study carrel. Thus, this data set is only 93,000 words long while the original data set was 490,000. Similarly, this data set only conains 500 documents (100 documents times 5 topics), and the original data set contained 2,700 documents. This data set is much smaller than the original. I then summarized the newly created data set, and the summarization can be seen here.
Next, denoting twelve topics, I topic modeled the new data set, and the following themes presented themselves:
labels weights features
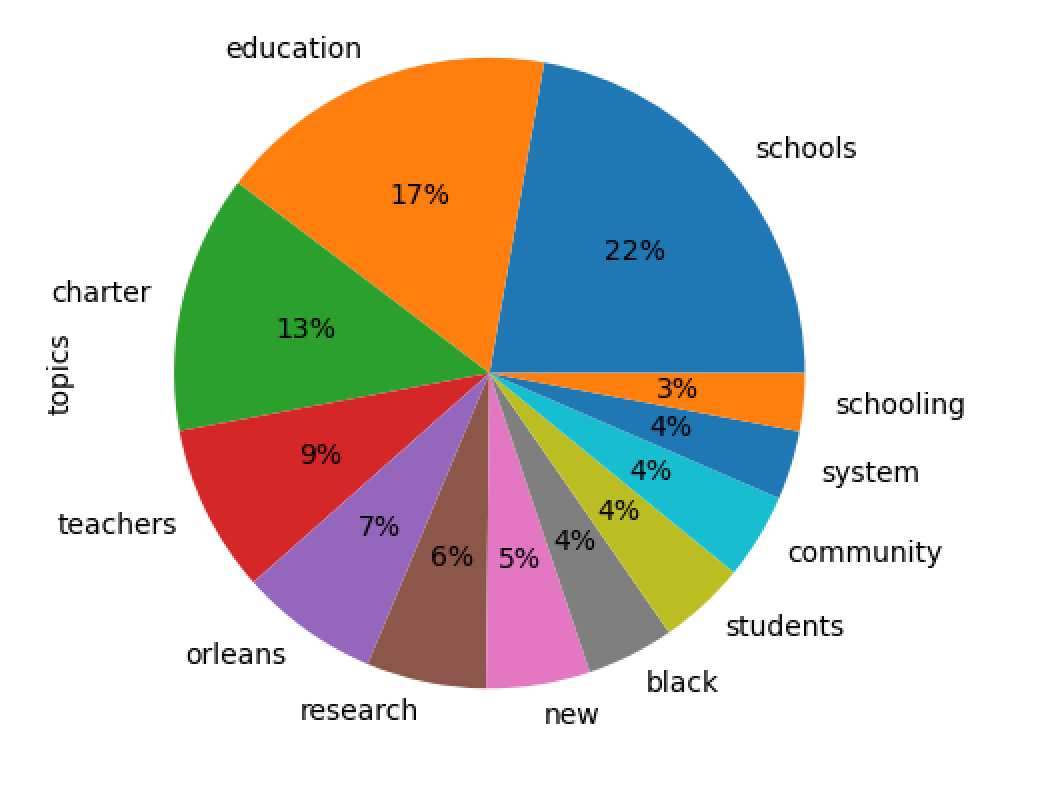
schools 0.21268 schools charter students public traditional st...
education 0.16707 education schools charter public policy state ...
charter 0.12676 charter leaders data schools study board findi...
teachers 0.08227 teachers teacher principals charter schools pr...
orleans 0.06846 orleans new schools public parish board state ...
research 0.05872 research new policy policies foundations organ...
new 0.05094 schools charter new orleans education educatio...
black 0.04290 black racial social practices students race sc...
students 0.04277 students schools kipp college program high imp...
community 0.04209 research community schools article social proc...
system 0.03381 new system public program orleans fund year ev...
schooling 0.02830 education schooling business new social articl...
A visualiztion of the result ought not be surprizing. The set of documents are about schools, education, charter, etc.:
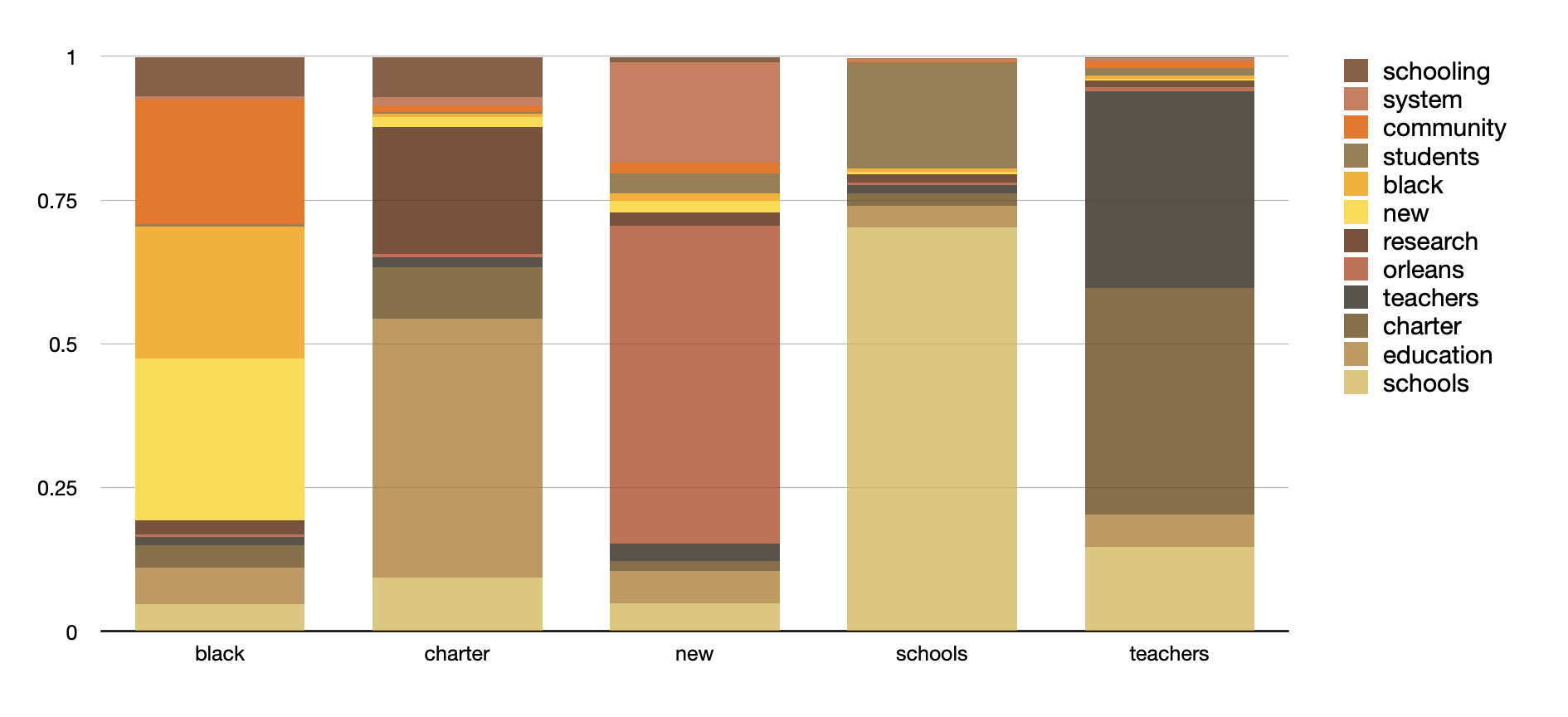
The topic model can be pivoted on the computed topics, and we can literally see that black documents are really about "black", "community", and "new". Put another way, since all of the bars in the charts are distinctive, each set of documents are distinctive as well:
Searching the collection for documents that are very much about Katrina, I was able to identify four, but one is a dupicate:
I then applied concordance functionality to the whole of the corpus to see how the word "katrina" was used. The result is long.
We started out with more than 2,700 citations/abstracts. We identified a few topics of interest, and then we created a subset of of 500 documents. I sincerely believe this subset is more informative and more on-target when compared to the original.
Next steps would be to apply addidtional text mining and natural language processing against the result to become more intimately aware of the content. This means the more rigorus use of ngram analysis, network diagrams, and exploitation of grammars. For example, we might ask ourselves, "With what other words is the word 'charter' associtated?" And the result looks something like this: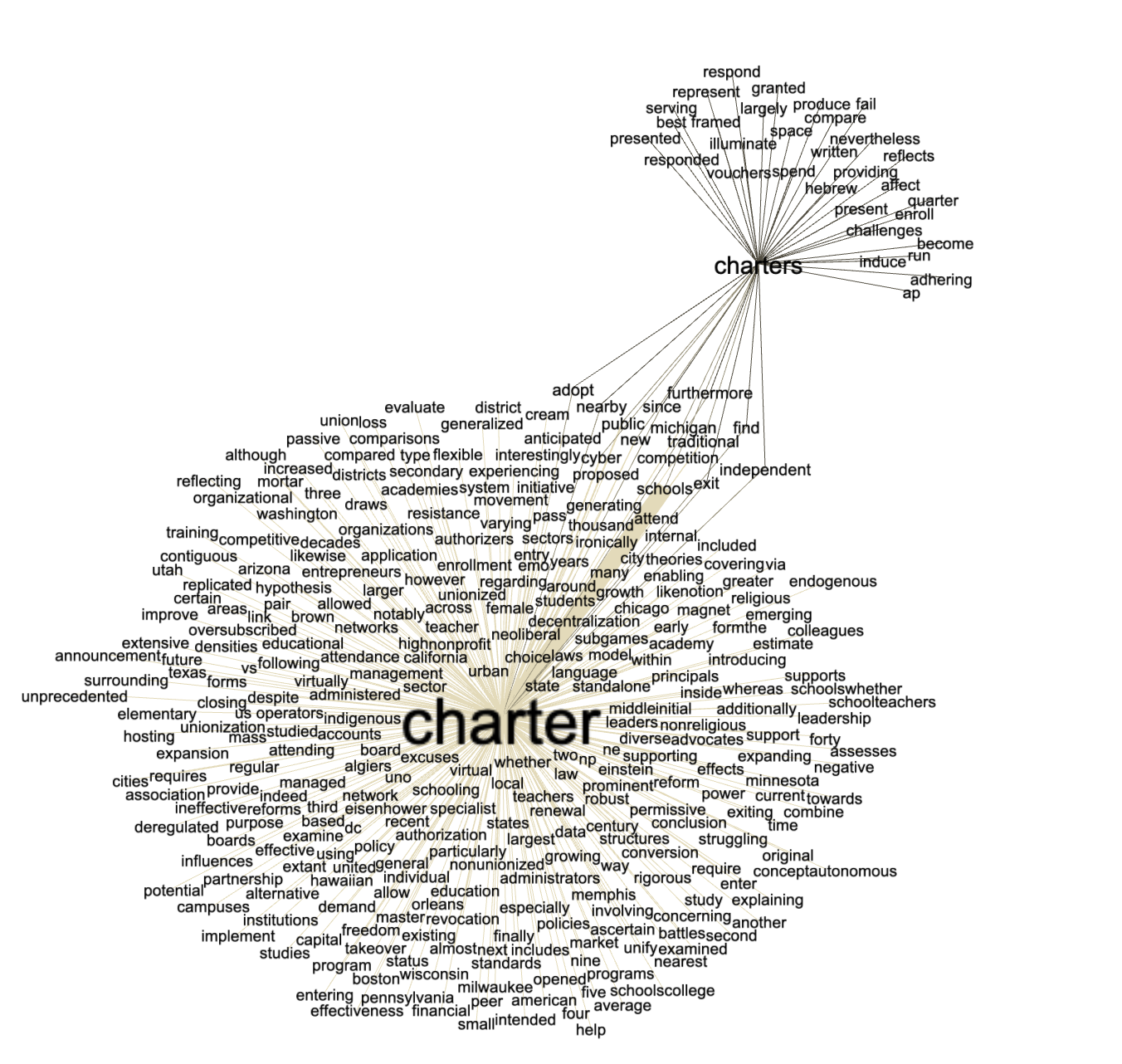
But then again, remember, "Whenever you have a hammer, everthing begins to look like a nail."
This data set -- study carrel -- ought to be available for downloading at http://carrels.distantreader.org/curated-katerina_and_charter_schools-2023/index.zip.
Eric Lease Morgan <emorgan@nd.edu>
Date created: Feburary 2, 2023 (Ground Hog's Day)
Date updated: June 1, 2024