This is an automatically generated overview of the Distant Reader study carrel called journal-isccIndonesianJournalOfCancerChemoprevention-doaj.
Given a corpus of narrative text, the Distant Reader and the Distant Reader Toolbox create data sets, and these data sets are affectionately called "study carrels". As data sets, study carrels are intended to be read by people as well as computers, and their purpose is to supplement the reading process, to increase use & understanding.
Study carrels are designed to be computable, and this Web page is the result of one such computing process; here you will find a simple analysis of the carrel's extracted features. Use the features to characterize the content of the carrel, and then use them like items in a back-of-the-book index for more in-depth analysis.
Outlined below are some introductory features of the carrel:
| Feature | Value | Description |
|---|---|---|
| creator | ubuntu | Under what username was this carrel created? |
| date created | 2024-10-11 | When was this carrel created? |
| size in items | 31 | How many items are in the carrel? |
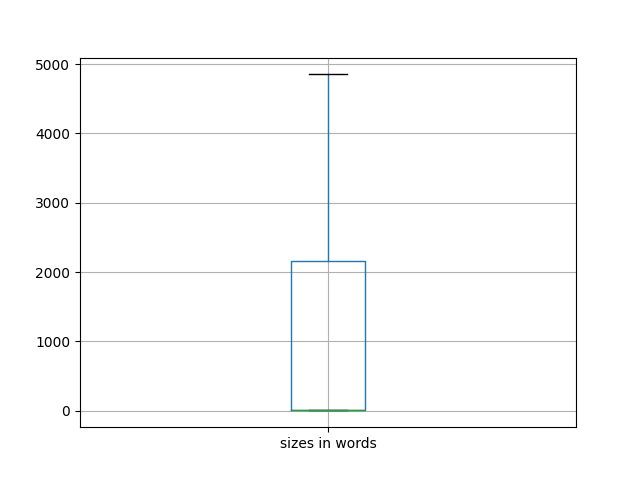
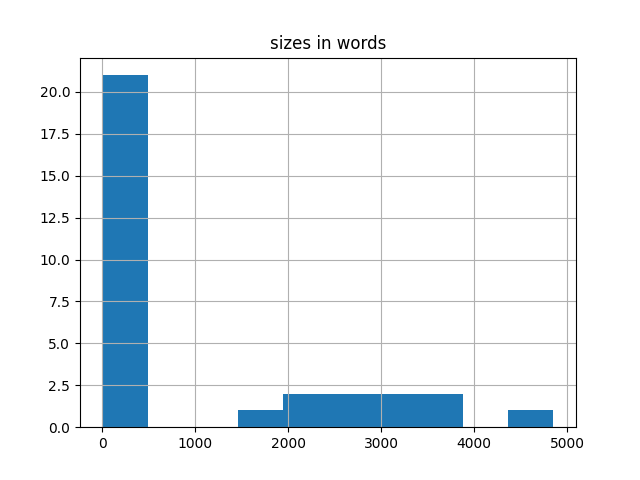
| size in words | 30,359 | Measured in words, how big is this carrel? By comparison, the Bible is about 800,000 words long. |
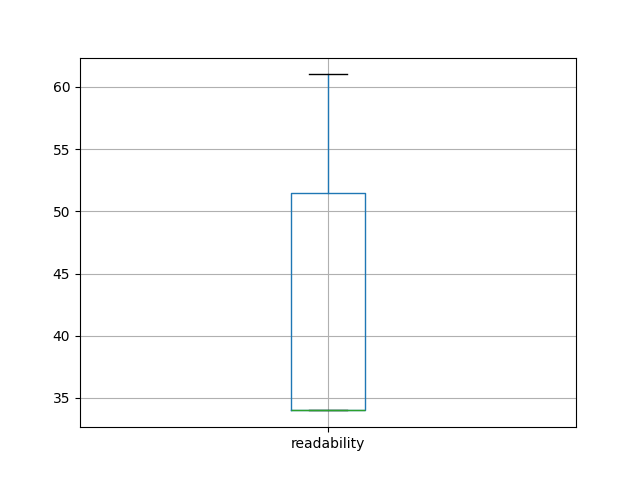
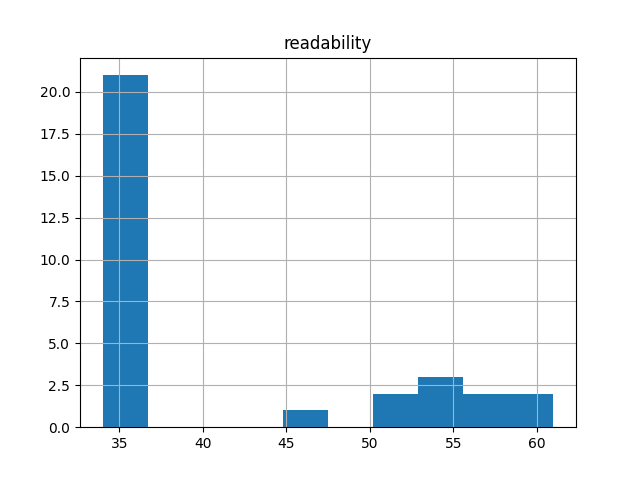
| readability score | 40 | Where 0 denotes impossible and 100 denotes easy, how difficult is this carrel to read? |
| other files | stopwords | What words have been denoted as function words such as "the", "a", and "an"? |
| other files | entire corpus | What does a bag-of-words form of the carrel look like? |
Measured in words, how big are the items in this carrel? To what degree are they of similar size? Are any of the items particularly large or small? In general, the typical scholarly journal article is between 5,000 and 8,000 words long.
Using a metric called Flesch -- where 0 means nobody can read the item, and 100 means everybody can read it -- how difficult are the items in this carrel to read? Shakespeare's Sonnets are relatively easy to read (with a score of about 90) because their vocabulary is small and the sentences are short. The typical novel by Jane Austen or Herman Melville have scores in the 70's. Scholarly articles are more difficult (scores between 50-70) because their langauge is more specialized. Texts of poor optical character recognition quality typically have very low scores.
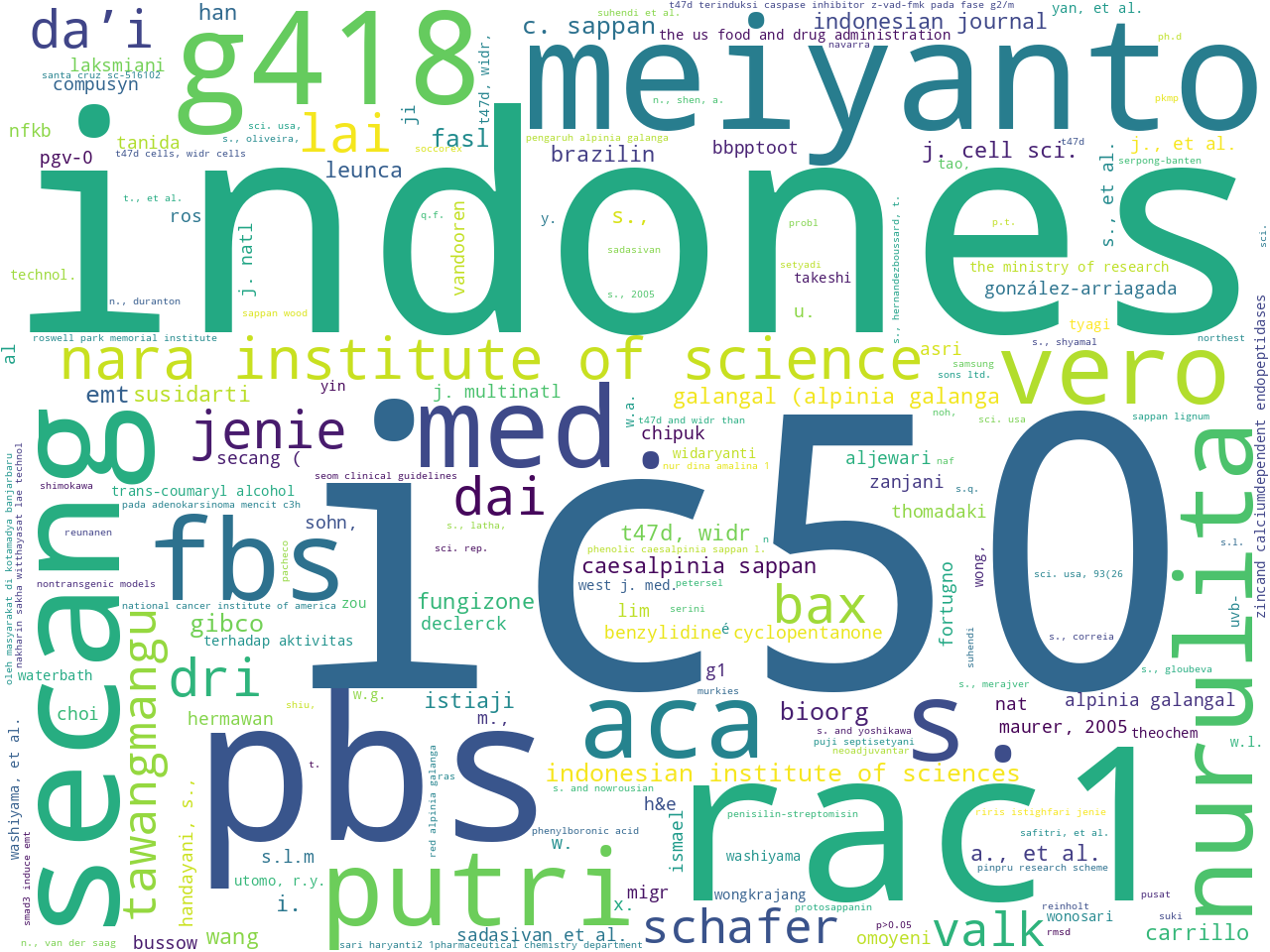
Excluding stop words, what are the most frequent individual words and two-word combinations in the corpus, thus addressing the question, "What are the items in this study carrel about?"
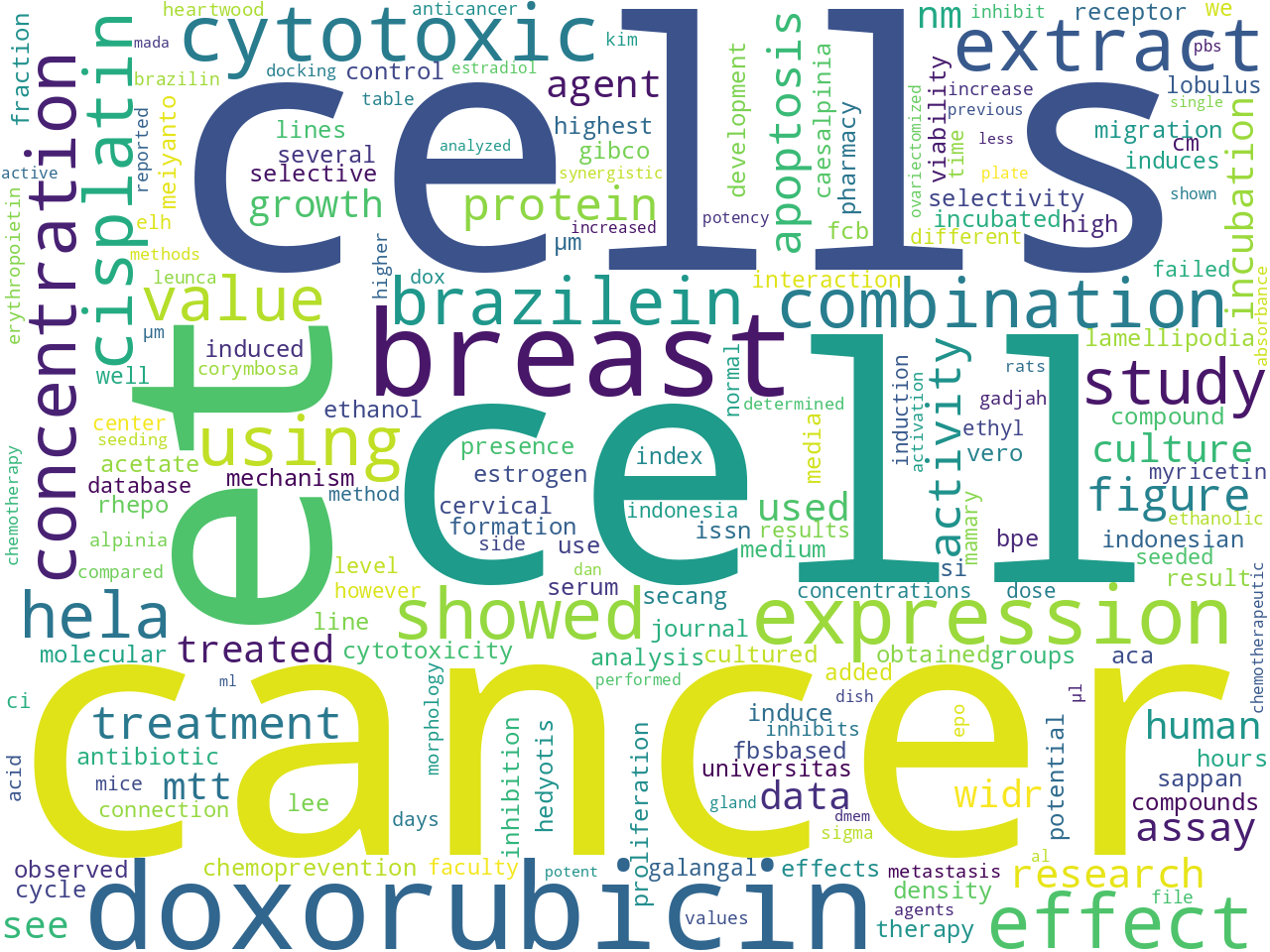 unigrams |
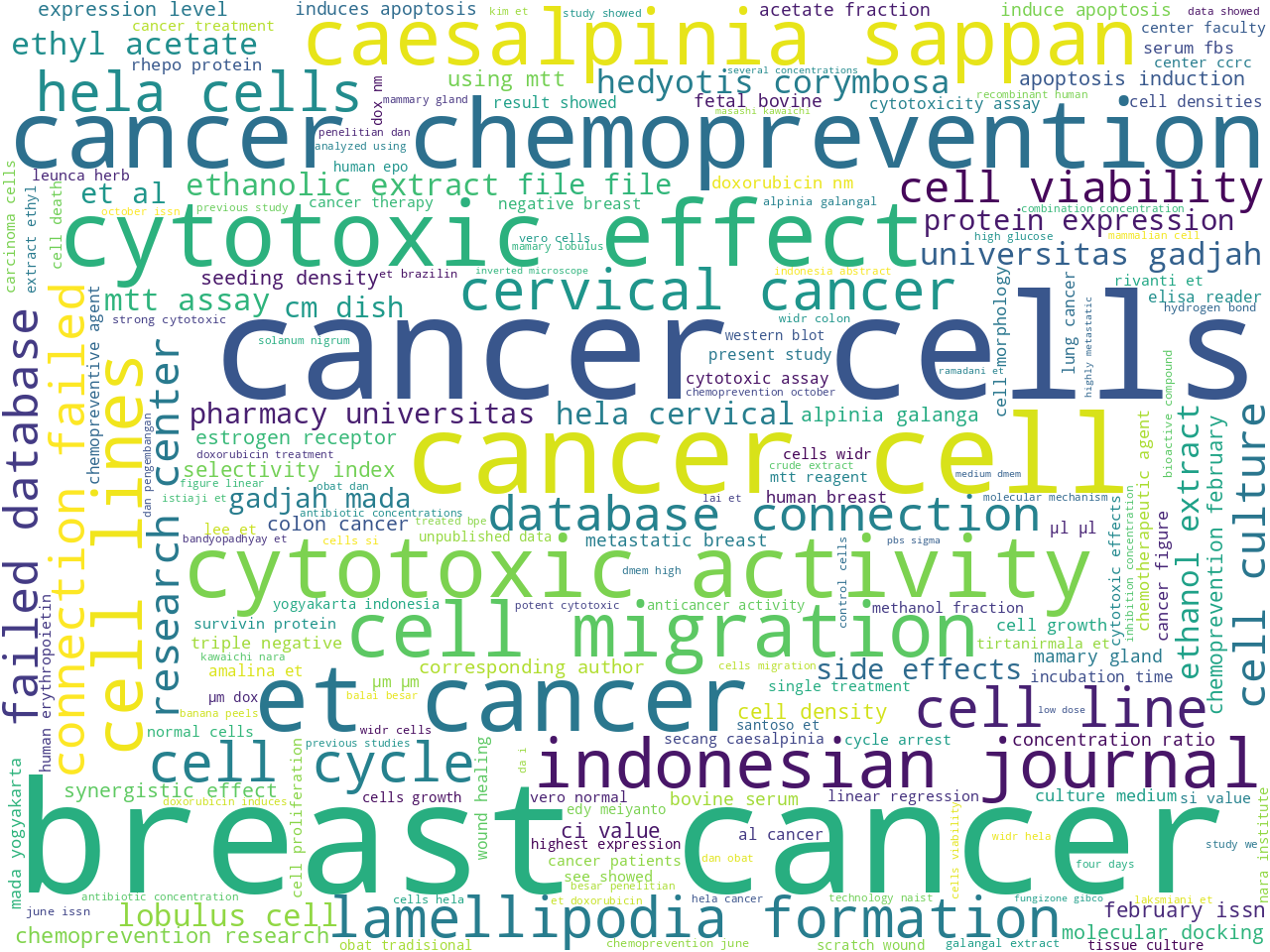 bigrams |
The most frequent extracted parts-of-speech features address questions of "What is discussed in this corpus, what do they do, and how are they described?"
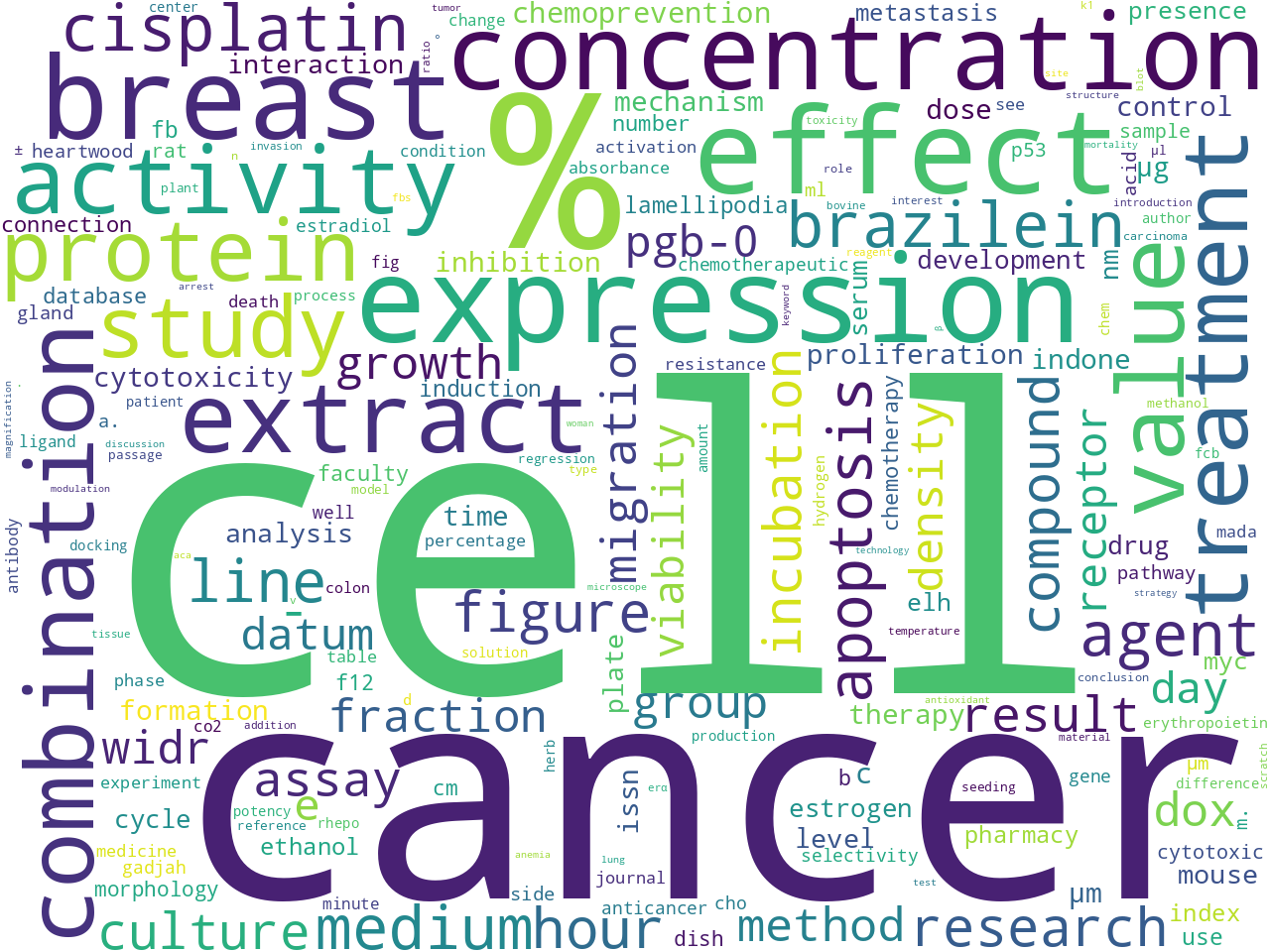 nouns |
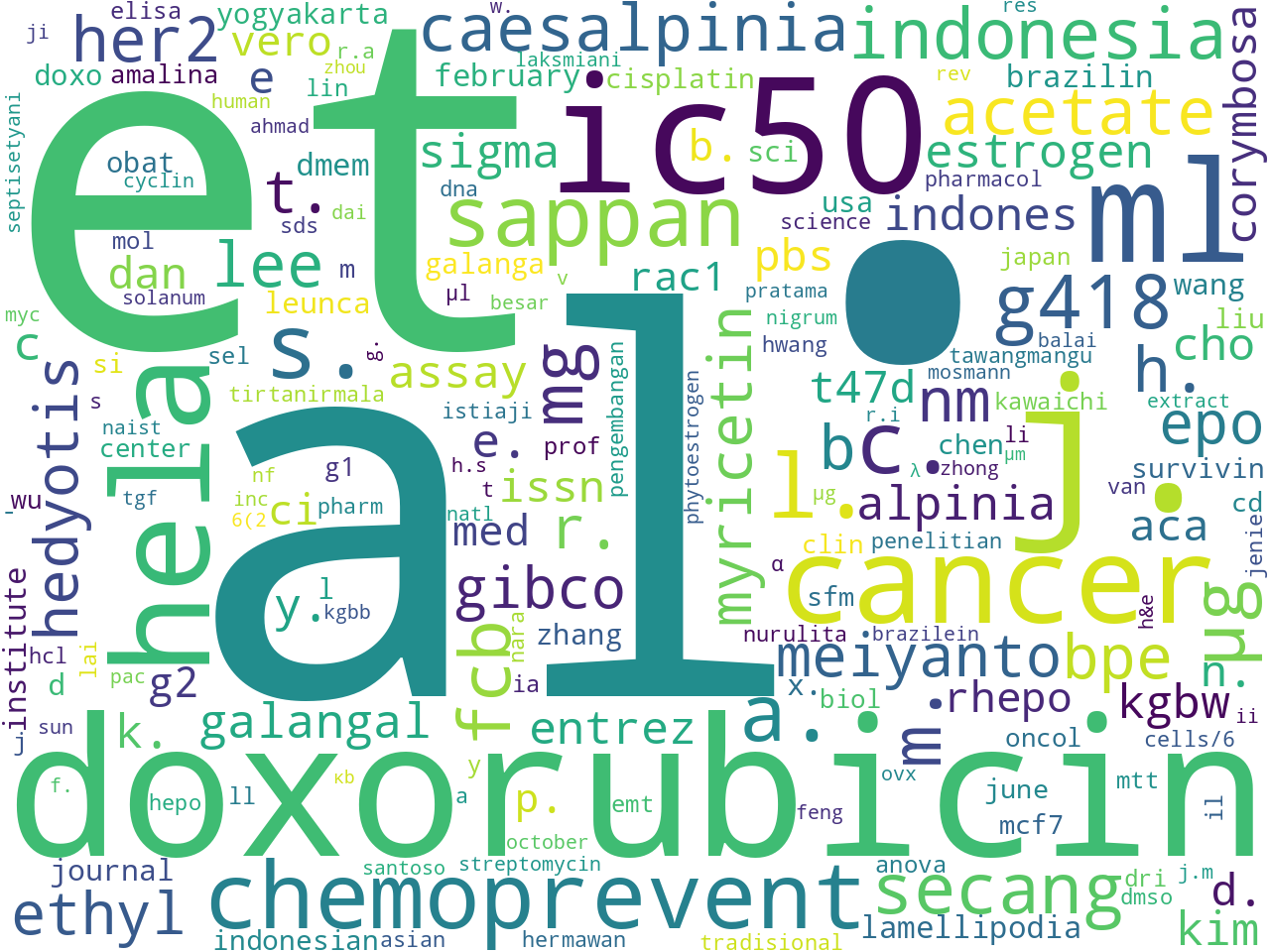 proper nouns |
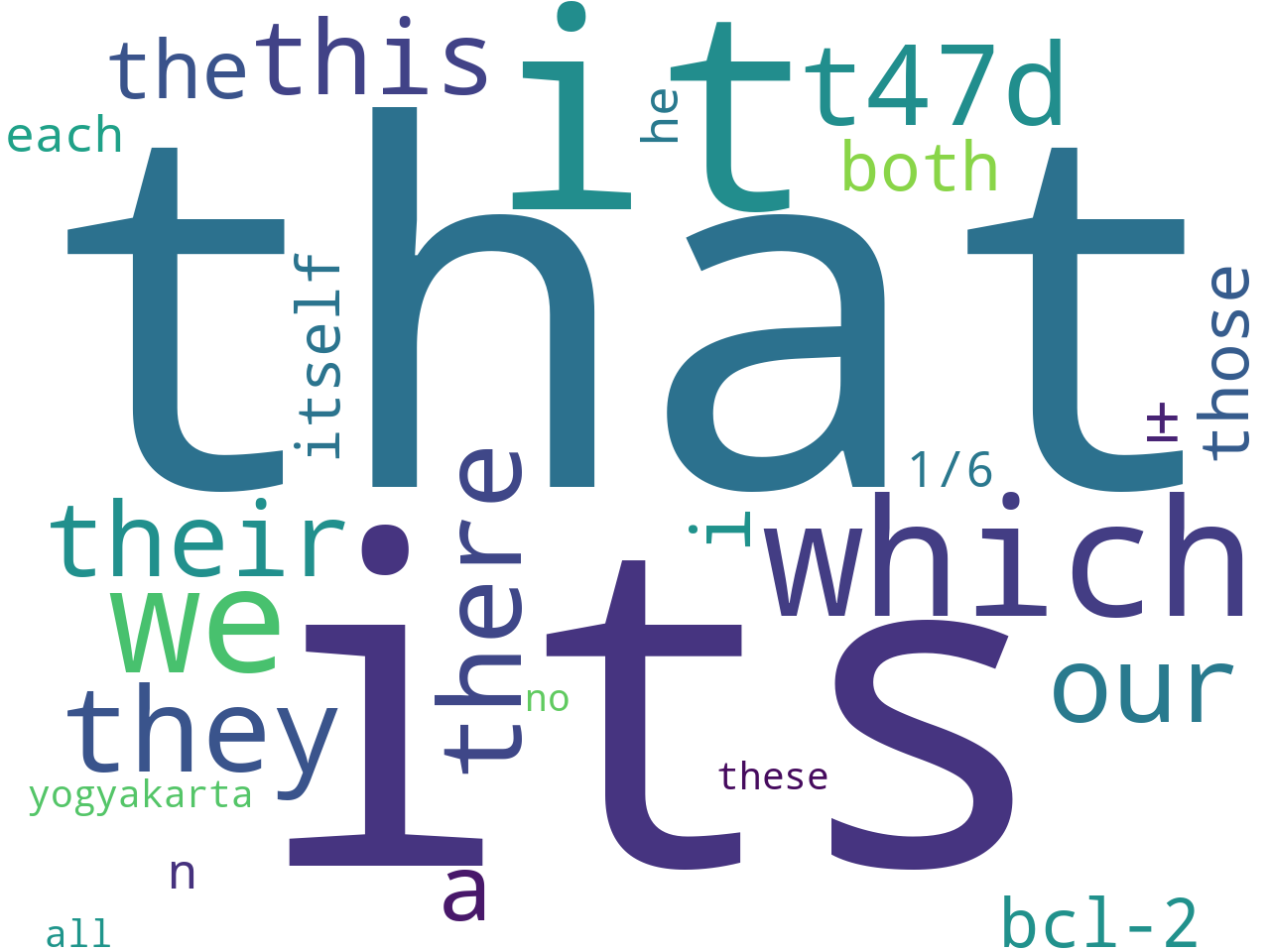 pronouns |
 verbs |
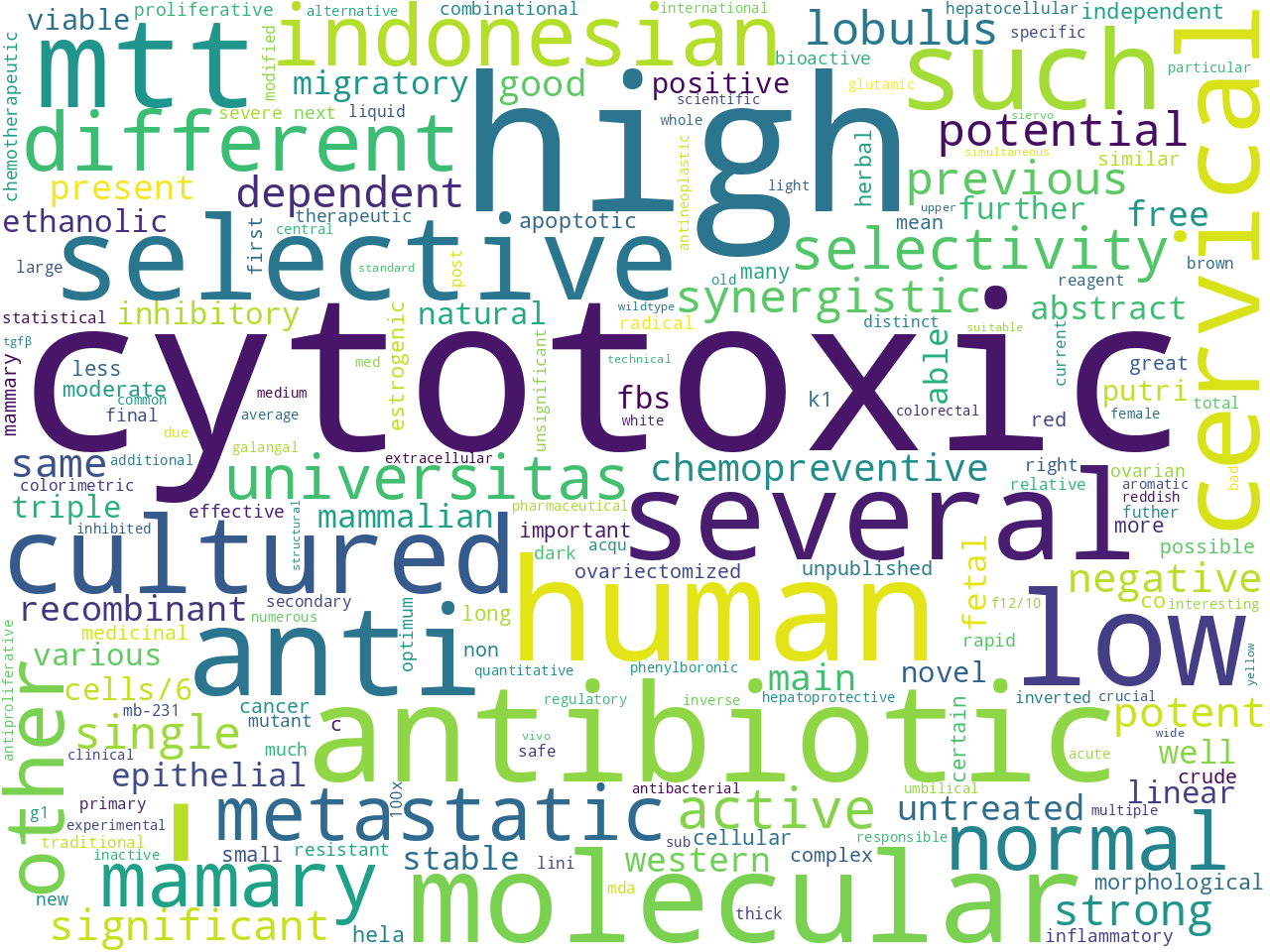 adjectives |
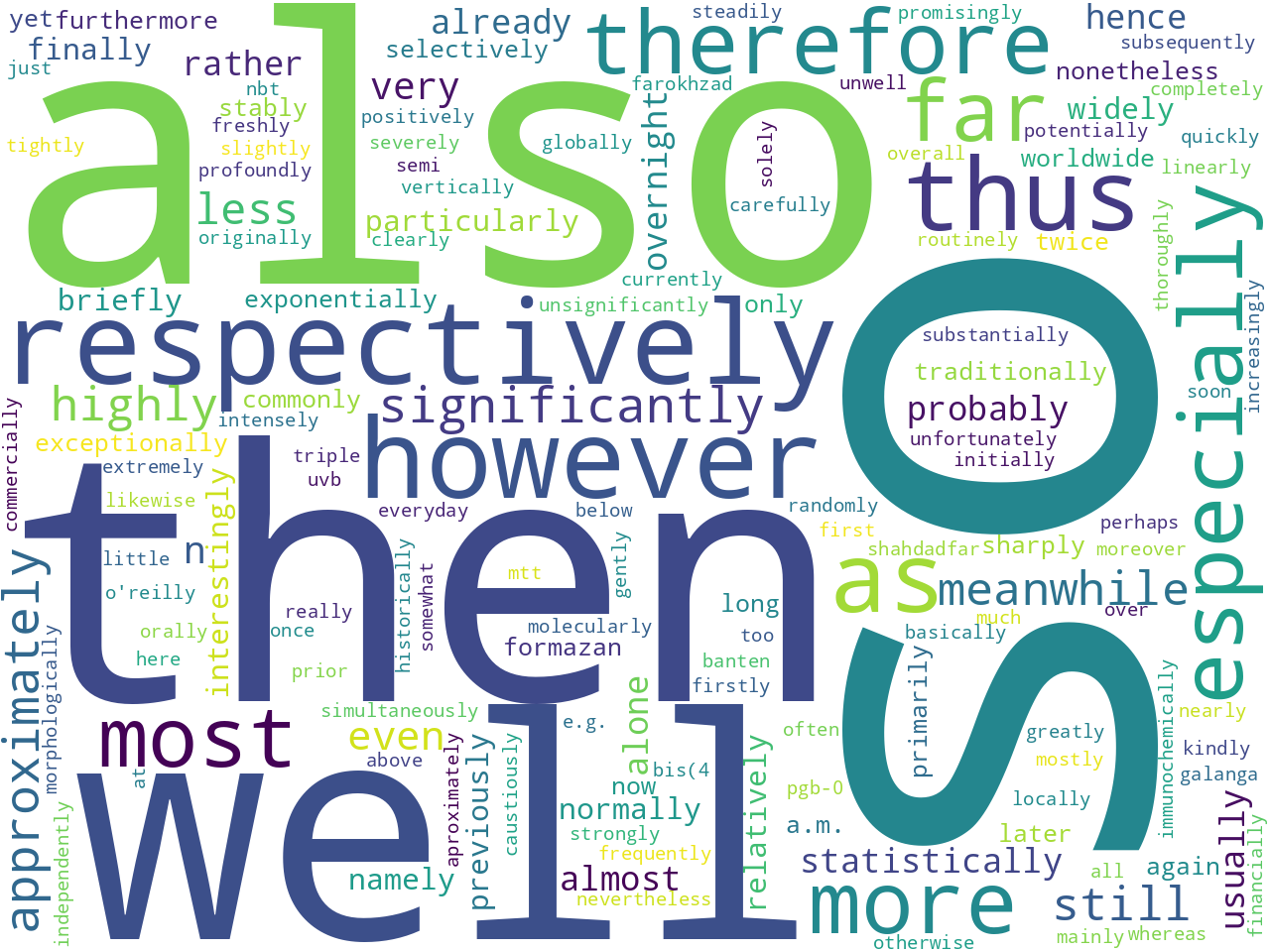 adverbs |
Similar to nouns, named-entities are real-world things but they are more specific. They help address questions of who, where, and how many.
 any entity |
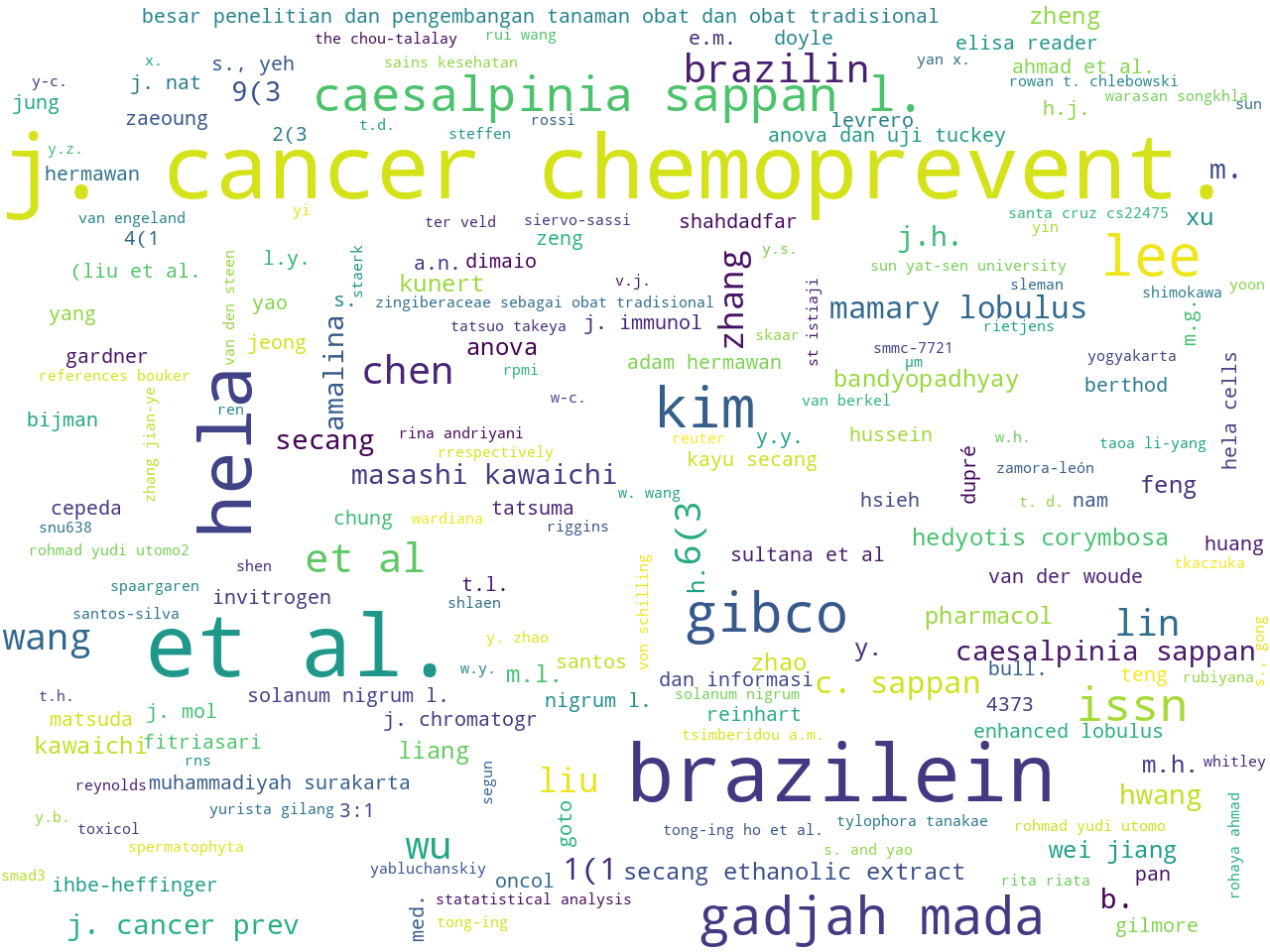 persons |
 geo-political entities |
 organizations |
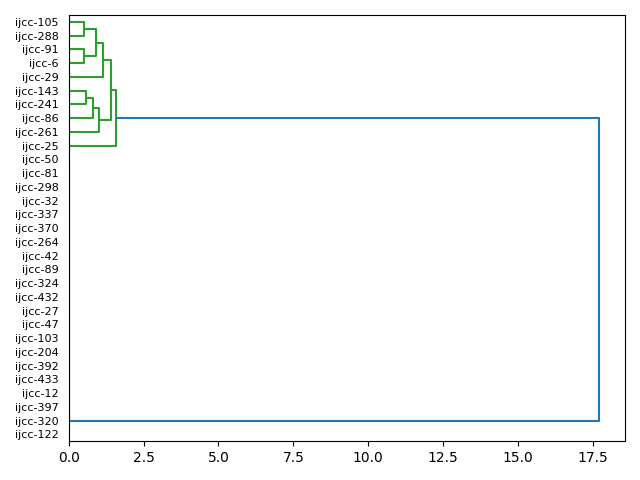
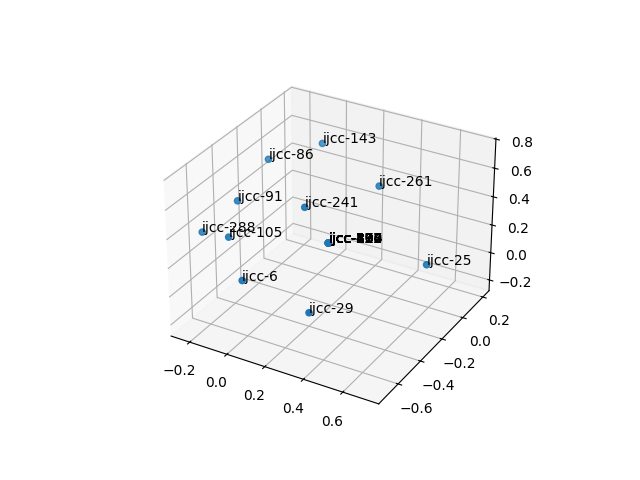
Through the use of a variation of the principle component analysis alogorithm, it is possible to plot the location of study carrel items in two- and three-dimentional spaces, thus addressing the questions, "To what degree is this study carrel holistic; to what degree are the items in this carrel easily subdivided into smaller group?"
Excluding stop words, and through the use of a variation of the term frequency-inverse document frequency algorithm, the set of computed keywords are akin to subject terms, and they help address the questions of, "What are the items in this carrel about and to what degree?"

Depending on how the carrel was computed against, the following point to additional models:
For more detail about study carrels, their structure, and how they can be used, start with the read me file.
Each and every study carrel contains a number of subdirectories (folders). The first two are about the carrel's content:
The next few subdirectories contain extracted features in the form of tab-delimited text files:
Very important. All of the content in the subdirectories above are readable by any spreadsheet application, database program, or programming language. Therefore, you do not need special software to do analysis.
There are two additional subdirectories in every study carrel:
All of this is just the beginning. For more detail about study carrels, their structure, and how they can be used, begin with the read me file.
Date created: 2024-10-11