
Figure 1: Words

Figure 2: Keywords
This missive outlines what I learned by analyzing the qualitative responses found in a survey on the topic of artificial intelligence. While the volume of content was relatively small, I assert there are some concerns regarding the use of artificial intelligence, and the concerns surround the use of AI by students and their ability to do research.
tl;dnr - concerned about students' overreliance on AI tools (e.g., ChatGPT) for homework, potentially plagiarizing other authors' works if these tools are improperly used; excited about learning how to use AI tools for research/teaching I would like to learn more about reliable AI tools for research & teaching.
The content to be analyzed was originaly supplied as a Microsoft Excel file, and I manually modified the file to make it more amenable to computation. These modifications included: removing extraneous newline (carriage return) characters, renaming many of the columns to more computationally-friendly values, normalizing the columns containing categorial values, and saving the result as a CSV (comma-separated values) file named ai-responses.csv. I then wrote a program (csv2reader.py) for the purposes of enhancing the responses. More specifically, based on the value of email address, I created "author", "title", and "file" columns. The program also concatonated the qualitative columns ("excites" and "more") into a new column called "comments". Finally, the program exported each of the comments as individual files and associated them with the author, title, and date values. The results of this process can be seen in the folder/directory called "comments". Lastly, I used the comments folder/directory as input to a tool of my own design -- the Distant Reader -- in order to create a data set, affectionately called a "study carrel". All the analysis of the survey was done against this data set. †
The original data set is relatively small (only 50 or so rows), and only forty of those rows included comments. Moreover, the totality of the comments is only 1,900 words long. Read a sort of bag-of-words model of all the comments. The rudimentary bibliography is another model of the responses.
After counting & tabulating the frequency of words as well as statistically significant keywords, the following two word clouds begin to illustrate themes in the responses. The results are very similar, but the keywords are more nuanced:
Figure 1: Words |
Figure 2: Keywords |
Topic modeling -- an unsupervised machine learning process used to enumerate latent themes -- is a popular natural language processing technique. Topic modeling is not very nuanced when it comes to such a small corpus, yet I was able to extract the following four themes, which echo the results of the rudimentary analysis:
topics weights words
research 2.42941 research tool tasks bias get students think
concerns 1.99596 concerns tools work using students data get
help 1.35237 help think know work students good privacy areas
quick 0.68564 quick information people write ensure clear
The weight of each topic can be compared to the whole through the use of a pie chart. From the results, you can see the comments were mostly about "research", but "research" is just a label for the cluster of words including: research, tool, tasks, bias, get, students. and think.
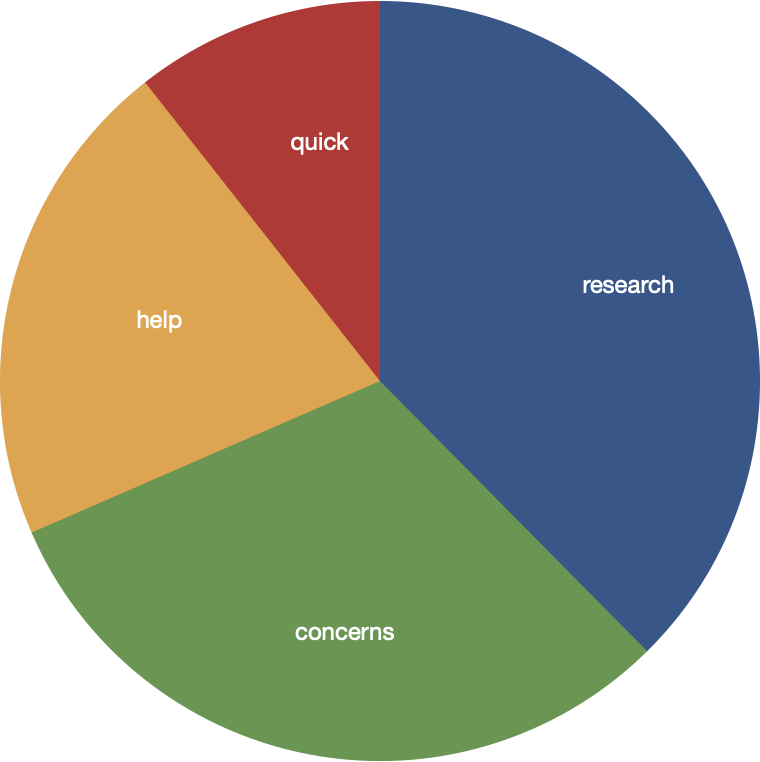 Figure 3: Topic modeled topics and their relationship to the whole |
Each response in the given data set was associated with a number of columns containing categorical values. These columns addressed the questions: Are you using AI tools?, Do you have a paid subscription?, and Would you be interested in a group information session? Given the computed topics and these categorial values, I pivoted and visualized the model to address the question, "To what degree does the current use of AI tools affect respondent's comments?" The result was non-conclusive; the computed topics were similarly distributed between respondent's use of AI tools. In other words, everybody has concerns regarding AI, no matter how often they are used:
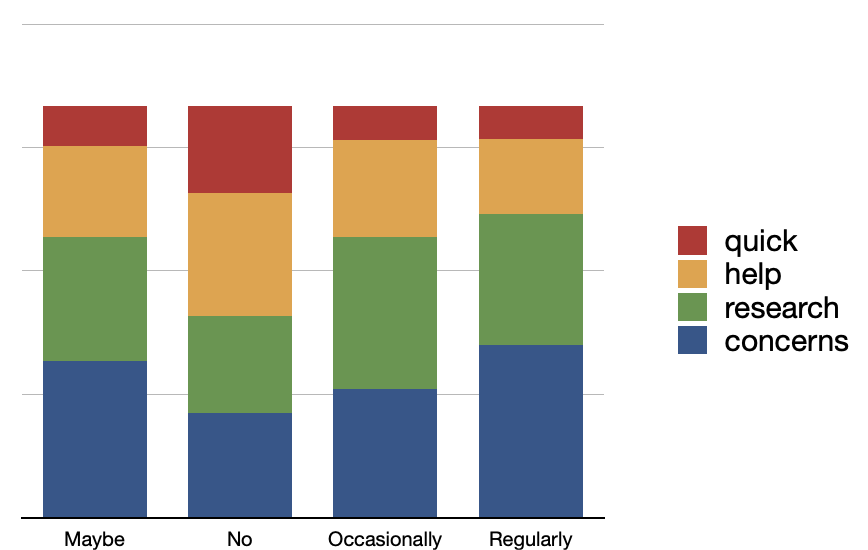 Figure 4: Topics compared to use of AI tools |
Survey respondents wrote comments, and comments include keywords. These things are akin to the nodes and edges of network graphs. Network graphs posses mathematical properties that can be used to highlight different characteristics of the graph. The following network graph illustrates the significance of keywords, their relationships to each other, as well as their relationships to respondents. The size of keywords and their proximity to the center denote greater significance. As you can see, the network graph analysis echoes words and themes from the previous analysis:
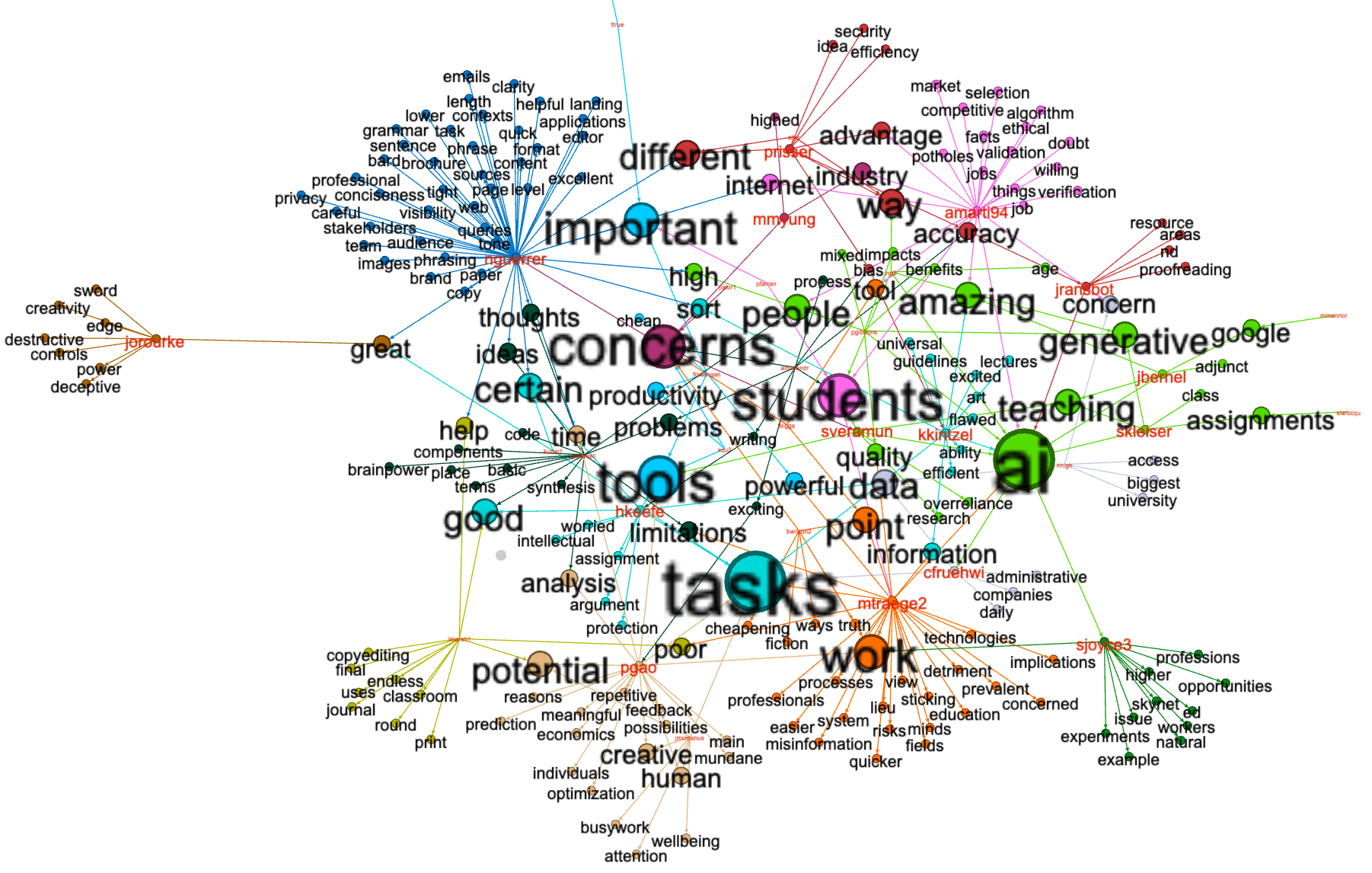 Figure 5: Network graph highlighting keywords and their relative relationships to each other as well as respondents |
To paraphrase a linguist named John Rupert Firth, "You shall know a word by the company it keeps", and consequently it behooves this analysis to extract the sentences containing the significant words. These words include but are not limited to: concerns, students, tasks, and maybe research and tools. Below is a list of sentences containing these words, and the sentences are ordered by the number of significant words they contain:
Using a number of different natural langauge processing modeling techniques, a small set of qualitative data extracted from a survey was analized. The word "concern" was deemed significant, and once observed in the context of sentences, the concerns surround students, their ability to do research, and the usefulness of AI as a tool.
As an experiment, the survey results were indexed against an OpenAI large-language model (LLM), and they were queried using a different OpenAI LLM. The following question was asked, "What concerns do survey respondents have about artificial intelligence (AI)?", and the following response was returned:
Survey respondents have expressed concerns about several aspects of artificial intelligence (AI). Some are worried about students and professionals relying too heavily on AI, which could hinder their education and critical thinking skills. There is also concern about the potential for AI to spread misinformation or poor-quality information if it is limited to regurgitating human knowledge. Another concern is the misuse and abuse of AI, as well as its biases and potential to mislead. Additionally, there are worries about the outsourcing of intellectual tasks to AI that could be beneficial for individuals to do themselves. Finally, there is a concern about AI having access to university data and the potential implications of that.
† - The entire data set ("study carrel") ought to be available for downloading at http://carrels.distantreader.org/curated-a_i_survey-2024/index.zip.
Eric Lease Morgan <emorgan@nd.edu>
Navari Family Center for Digital Scholarship
Hesburgh Libraries
University of Notre Dame
Date created: January 13, 2024
Date updated: June 2, 2024