Code4Lib Journal, Issue 55
This is a reading of Code4Lib Journal, Issue 55, January 2023.
The lastest issue of Code4Lib Journal came out yesterday, and I wanted to see how quickly I could garner insights regarding the issue's themes, topics, and questions addressed. I was able to satisfy my curiosity about these self-imposed challenges, but ironically, it took me longer to write this blog posting than it did for me to do the analysis.
Rudimentary text mining
First, the number of words in the issue is relatively small -- only 35,000 words. (Moby Dick is about 200,000 words long.) Visualizations depicting unigram, bigram, and keyword frequencies begin to tell of the issue's aboutness. A computed bibliography elaborates on the same themes.

unigrams |

bigrams |

keywords |
For more additional statistics describing the issue, see the computed summary.
Topic modeling
Topic modeling is a unsupervised machine learning process used to enumerate latent themes is a corpus. Given an integer (T), the underlying algorithm clusters the corpus into T groups, and because the words in each group are deemed to be physically close to each other, the resulting groups can be considered topics or themes. Since there are 9 articles in this issue, I denoted T to equal 9. After removing stop words and running the algorithm the following topics presented themselves:
| labels (topics) | weights | features |
| using | 0.46649 | using data use library new used code file |
| 0.06551 | google primo tag unpaywall manager links open | |
| records | 0.06229 | records record isbn python data author title |
| video | 0.06111 | video search videos lecture application text |
| vue | 0.05749 | vue html page strong code true fas hamburger |
| archival | 0.04857 | archival description digital materials systems |
| data | 0.03616 | data linked bibframe cataloging metadata name |
| app | 0.02710 | app value queue key delete export system studio |
| stress | 0.01552 | data stress word model fairseq research column |
To understand the results another way, the overarching theme of the issue is using data, as illustrated below:
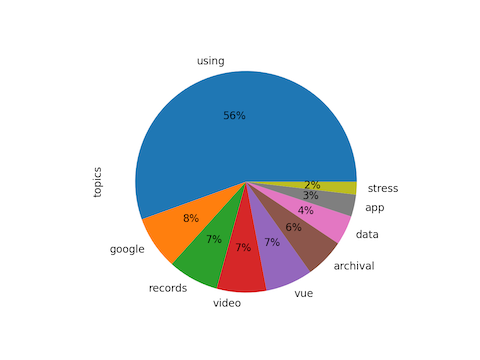
topics
Themes in-and-of themselves may be interesting, but they become more interesting when compared to metadata values such dates, places, or in this cases, authors. By supplementing the underlying model with author values and then pivoting the results, we can literally see the predominate topics discussed by each author. Notice how the editorial, the introduction written by Tidal is all the themes. Notice also how there is an underlying theme -- using data.
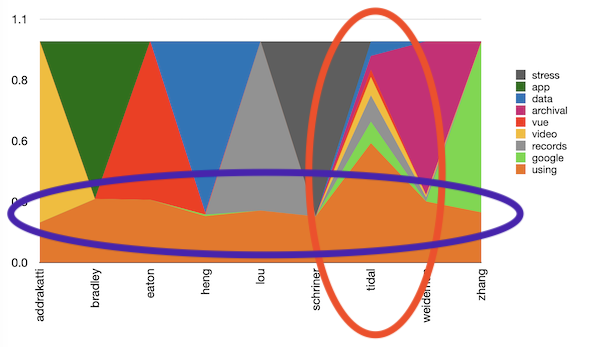
topics by author
Questions and answers
In the very recent past I have been playing with question/answer systems. Given a previously created model, it is possible to feed a text to a computer program, and the result will be a list of questions extracted by the model. One can then feed the question as well as the text to a second program in an effort to identify the answers. To my surprise, the process works pretty well and represents an additional way to conote the aboutness of a document.
I applied this technique to the editorial, and below are some of the more interesting question/answer pairs:
- Q: How long did I serve on the editorial committee for Code4Lib Journal?
- A: 7 years
- Q: I have learned quite a lot from what?
- A: my fellow editorial committee members
- Q: What describes the use of sequence-to-sequence models and how it can be applied for a variety of applications?
- A: Data Preparation for Fairseq and Machine-Learning using a Neural Network
- Q: What kind of editors are highly encouraged to apply to Code4Lib Journal?
- A: diverse communities
- Q: Where did I attend my first code4lib conference?
- A: North Carolina State University
The complete list of question/answer pairs is available as a part of the underlying data set.
Summary
Through the exploitation of rudimentary text mining, more sophisticated topic modeling, and even more sophisticated machine learning computing techniques it is relatively easy to get an overview of a given corpus.
The data set used to do this anaysis, complete with a cache of the original documents, is available as a Distant Reader study carrel at http://carrels.distantreader.org/curated-code4lib_issue_55-2023/index.zip.
Creator: Eric Lease Morgan <emorgan@nd.edu>
Source: This is the first publication of this posting.
Date created: 2023-01-21
Date updated: 2024-05-31
Subject(s): readings; Code4Lib;
URL: http://carrels.distantreader.org/curated-code4lib_issue_55-2023/