How to Read a Whole HathiTrust Collection, or "How did Ralph Waldo Emerson define what it means to be a man?"
This Web pages outlines a process to use and understand ("read") the whole of a HathiTrust collection. Such a process is outlined below:
- articulate a research question
- search the 'Trust and create a collection
- download the collection file and refine it, or at the least, remove duplicates
- use the result as input to htid2books; download the full text of each item
- use Reader Toolbox to build a "study carrel"; create a data set
- compute against the data set to address the research question
- go to Step #1; repeat iteratively
The balance of this essay elaborates on each one of these steps and then summarizes the whole.
Step #1 of 7 - Articulate a research question
 Someone once said, "If you don't know where you are going, then you will never get there." The same thing is true of the reading process. If one does not articulate what they want to get out of the reading process, then one is not setting themselves up for success. Thus, at the forefront, it is useful to articulate a research question, or at the very least, a purpose. The questions or purposes can range from the mundane to the sublime. They can be as simple as "entertain me", "tell me about such and such", or to as complex as "What is love?" For the purposes of this essay, my research question is, "How did Ralph Waldo Emerson define what it means to be a man?" To answer this question, I will do my best to acquire the whole of Emerson's writings, and I will use a computer to assist in the reading process.
Someone once said, "If you don't know where you are going, then you will never get there." The same thing is true of the reading process. If one does not articulate what they want to get out of the reading process, then one is not setting themselves up for success. Thus, at the forefront, it is useful to articulate a research question, or at the very least, a purpose. The questions or purposes can range from the mundane to the sublime. They can be as simple as "entertain me", "tell me about such and such", or to as complex as "What is love?" For the purposes of this essay, my research question is, "How did Ralph Waldo Emerson define what it means to be a man?" To answer this question, I will do my best to acquire the whole of Emerson's writings, and I will use a computer to assist in the reading process.
Step #2 of 7 - Create a collection
It is rather easy to create a HathiTrust collection. Search the 'Trust. Mark specific results as items of interest. Create and/or add those items to a collection. Repeat until done or get tired. For the immediate purpose, I searched the 'Trust for things authored by Ralph Waldo Emerson, and to make my life easier, I limited all search results to full text items and originating from Harvard University. This resulted in a
collection of more than 300 items .
Step #3 of 7 - Refine the collection
While it is easy to create a collection, refining the collection is non-trivial. For example, there are quite likely many duplicates, and each duplicate may be expressed in very similarly but not exactly in the same way. Moreover, since collections are displayed in a format akin to the venerable catalog card, it is difficult to sort, group, and ultimately compare and contrast collection items.
An application called
OpenRefine is designed to address these issues, and while OpenRefine is not "rocket surgery", its use does require practice. Here is an outline describing how one might go about... refining a 'Trust collection file:
- download the collection file and save it as a .tsv file instead of a .txt file
- download and install OpenRefine
- launch OpenRefine and import the collection file, and for now the defaults are fine
- convert date values to numbers, numerically facet on the result, and remove unwanted items
- edit/cluster on author values, filter and/or facet on the result, and remove unwanted items
- edit/cluster on title values, filter and/or facet on the result, and remove unwanted items
- go to Step #4 until satisfied
- export the result as a tab-delimited file
At this point you may want to import the result into your favorite spreadsheet application in order to do any fine tuning.
I did all this work, and my original list of more than 300 items was whittled down to twenty-one. As a whole, the
list is very much representative of Emerson's entire writings .
Step #4 of 7 - Download full text
The next step is to actually get the data needed for analysis. If the student, researcher, or scholar require only a few items, then using the 'Trust's Web interface to download them might be the way to go. On the other hand, if more than a few items are required, then the process is more efficient (and certainly less tedious) if it were automated. This is exactly what the
HathiTrust Data API is for. Given a username, password, and 'Trust identifier, one can automate the acquisition of dozens, if not hundreds of items.
A few years ago I wrote a set of Perl scripts to do just this sort of thing. They are called
htid2books . The scripts can be run on just about any Windows, Macintosh, or Linux computer. Get a username/password combination from the 'Trust, store these secrets as local environment variables, download the Perl scripts, and run the
./bin/collection2books.shscript with the name of the refined collection file. The scripts will get a 'Trust identifier from the collection file, download each page of the item, concatenate all the pages into a single plain text file, do the same thing for the scanned JPEG images, concatenate all the images into a single PDF file, and repeat the process for each item in the collection. In the end one will have both
plain text (OCR) as well as
PDF versions of each item in the collection. Each item will have the same name as the given HathiTrust identifier.
Step #5 of 7 - Build a "study carrel"; create a data set
At this point in the process we have a bibliography (the collection file) linked to sets of full text through a HathiTrust identifier. Using the traditional analysis process, the student, researcher, or scholar would print (and possibly bind) the PDF files, and with pen or pencil in hand, begin to read the corpus. The same student may open the files on their computer, and read them on screen using some sort of note-taking feature. In either case, such a process is time intensive, not very scalable, but very immersive.
Alternatively, by applying text mining and natural language processing against the corpus, and then saving the result as a set of structured data, the same student, researcher, or scholar can model ("read") the result to: 1) examine the corpus at a distance, and 2) address specific research questions through computation. This is what another tool --
the Distant Reader Toolbox -- is intended to do. Once the Toolbox is installed, creating a study carrel is as simple ("famous last words") as the following command:
rdr build <carrel> <directory>
where:
<carrel>is the name of the study to be created (for example,
emerson-works), and<directory>is the name of the directory were the harvested files are stored (for example,
./emerson-works)
Step #6 of 7 - Address the research question
A research question has been articulated. Content has been identified, collected, and organized into a data set. It is now possible to do some analysis ("reading") against the corpus, and there are many different types of analysis. Each of these types are really modeling processes -- different methods for viewing the whole of the collection.
Extent, aboutness, and frequencies
One of the first things the student, researcher, or scholar will want to do is review the extent of the collection and answer the question, "In terms of size and scope, how big is the corpus?" In this case,
the corpus contains 21 itemsand
the total number of words in the corpus is 1.7 million. By comparison, Melville's
Moby Dickis about .2 million words long. Tolstoy's
War & Peaceis about .5 million words long. And the
Bibleis about .8 million words long. Consequently, our corpus is just more than twice the size of the
Bible.
At this point it is also useful to
peruse the corpus in the form of a bibliography . In this case each bibliographic entry includes an author, a title, a date, a unique identifier, a computed summary, a set of computed key (subject) words, extents, and full path names to the original as well as plain text documents on the local file system. Below is such an entry:
id: hvd.hw1zwi
author: Emerson
title: Journals (v. 06)
date: 1882
words: 118005
flesch: 81
summary: Influence of Jesus and good men. There is no symmetry in great men of the first or of
the tenth class.
keywords: age; alcott; beauty; best; better; books; boston; character; charles; church; come; day;
emerson; england; essays; experience; eyes; fact; fine; friends; genius; god; good;
great; history; house; intellect; journal; law; life; light; like; little; long; look;
love; man; men; mind; natural; nature; new; old; passage; people; persons; place; poet;
poetry; poor; power; read; rest; said; second; series; society; spirit; things; thought;
time; truth; way; webster; woman; work; world; years; young
cache: /Users/eric/Documents/reader-library/emerson-works/cache/hvd.hw1zwi.pdf
plain text: /Users/eric/Documents/reader-library/emerson-works/txt/hvd.hw1zwi.txt
The next thing one will want to do is determine which words, phrases, or features are prominent. Addressing this issue gives us an idea of what the corpus is about. There are many different ways to make such an assessment. Examples include determining the frequencies of ngrams, collocations, parts-of-speech, named-entities, and keywords. Both the extents and frequencies can be automatically generated through the Toolbox's summarize command:
rdr summarize <carrel>
where <carrel> is the name of the study carrel to be analyzed (for example,
emerson-works)
The result is a
generic HTML page containing things akin to rudimentary descriptive statistics, and below are some of the more interesting frequencies (unigrams, bigrams, nouns, and keywords, respectively):

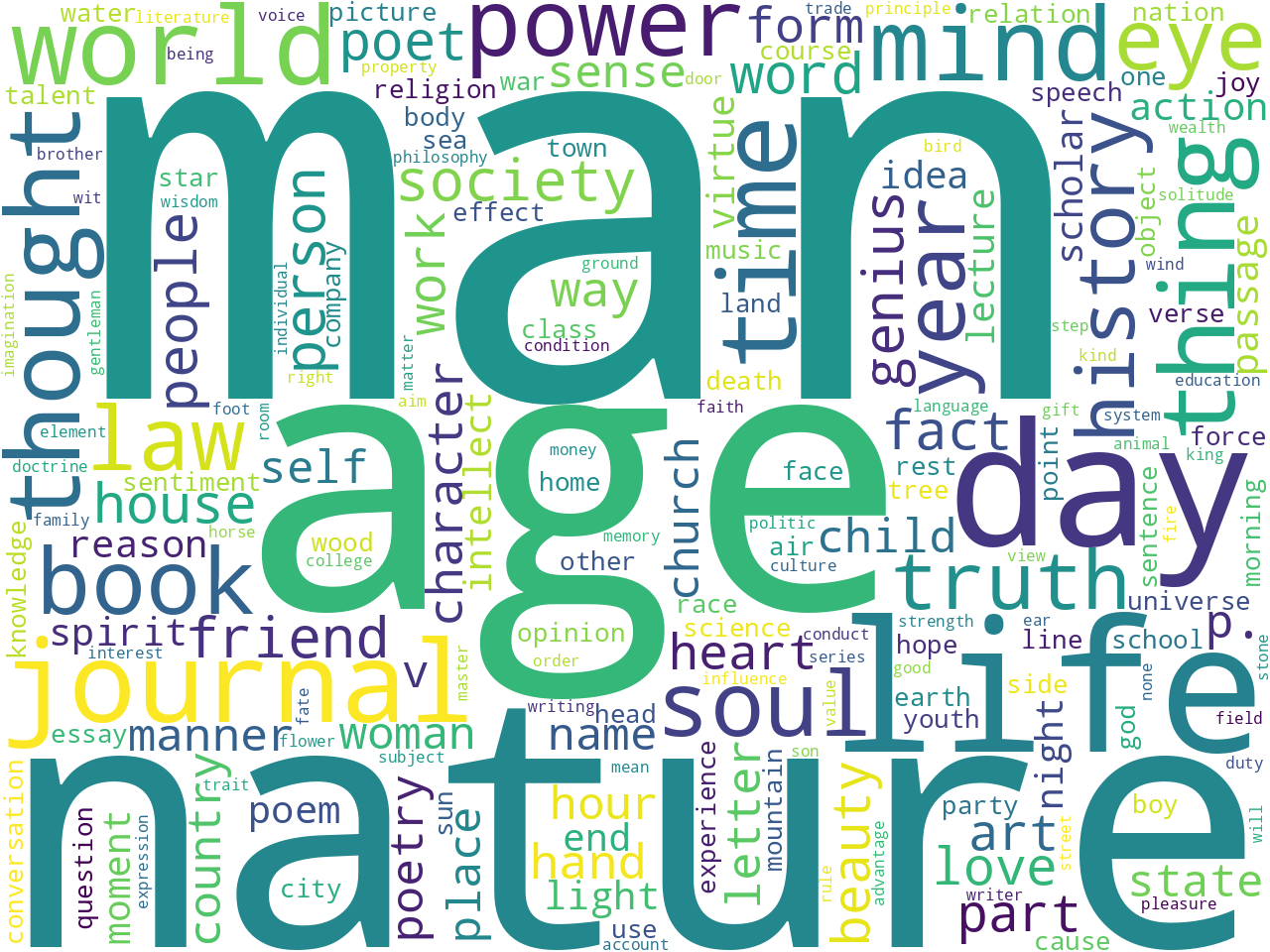
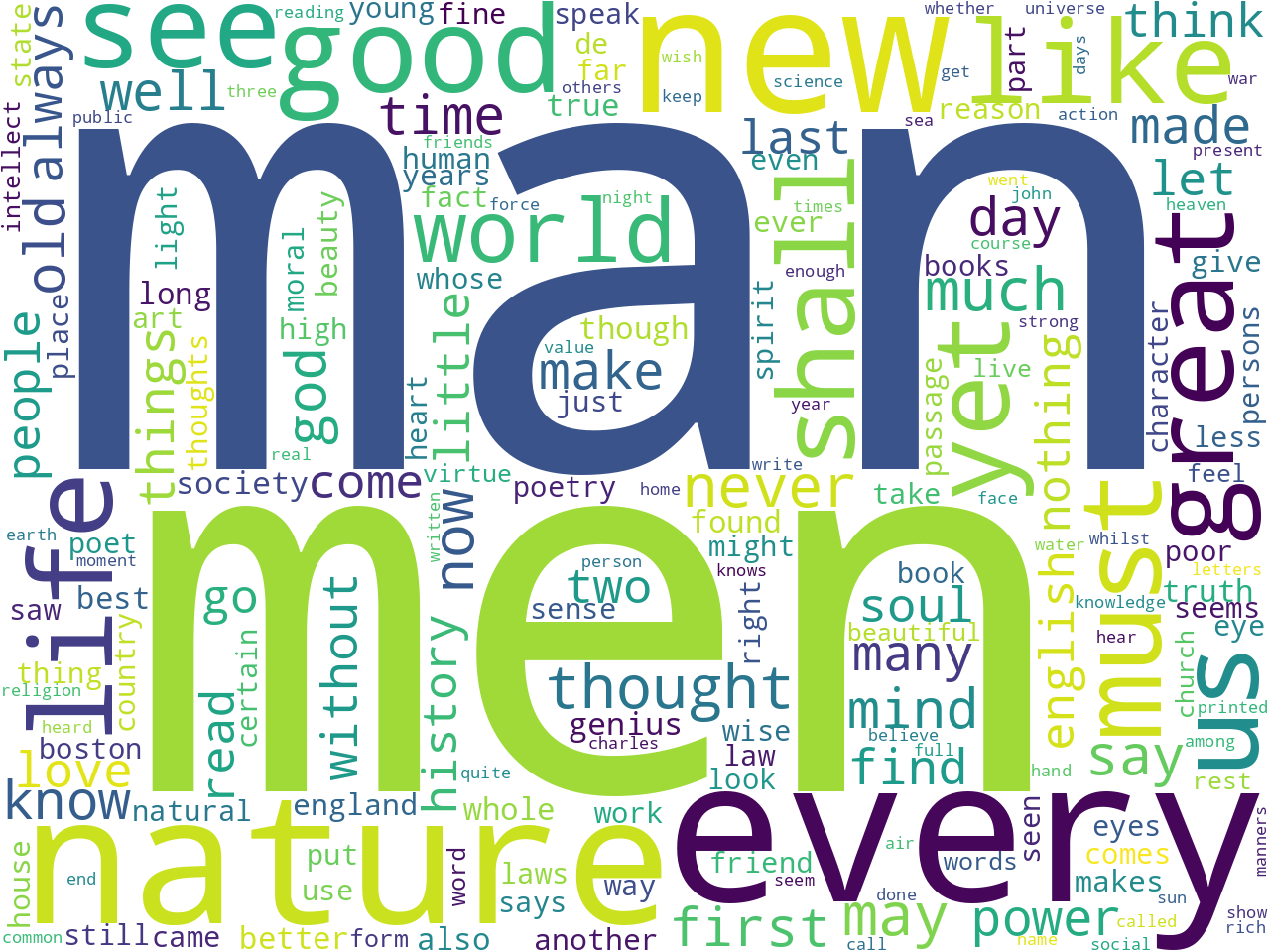
Based on my experience, this study carrel is larger than many, and since the words "man" or "men" appear prominently across the frequencies, I believe there is a good chance we will be able to learn how Emerson defined what it means to be a man.
Feature reduction and clustering
Through the use of a few additional techniques, the student can garner a more refined view of what the corpus is about. For example, feature reduction (PCA) is one way to determine how many different clusters of documents or themes may exist. Furthermore, topic modeling (LDA) enables us to cluster the corpus into N clusters, where N is the number of desired topic/themes. Once a topic model has been generated, it is possible to supplement the model with metadata, pivot the resulting table, and visualize how different topics are manifested over time, between authors, or between titles.
The following Toolbox commands demonstrate the point. The first outputs a dendrogram illustrating how many gross themes may exist in the carrel. (Apparently there are two.) The second performs topic modeling on the corpus with two topics elaborated upon with twelve words each. The third illustrates how those two topics manifest themselves in the whole of the corpus. The last command illustrates how the two themes are manifested in each title:
-
rdr cluster emerson-works
-
rdr tm emerson-works -t 2 -w 12
-
rdr tm emerson-works -p read -o chart
-
rdr tm emerson-works -p read -o chart -y bar -f title
Possibly, there are two dominant themes on the corpus, and the corpus is grossly divided between the two, as illustrated with following dendrogram:
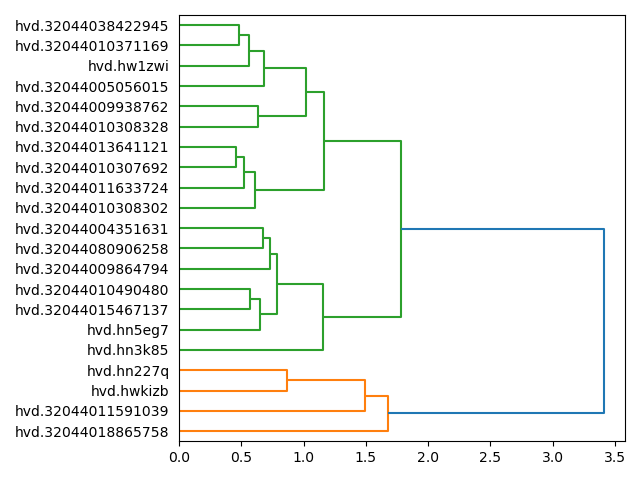
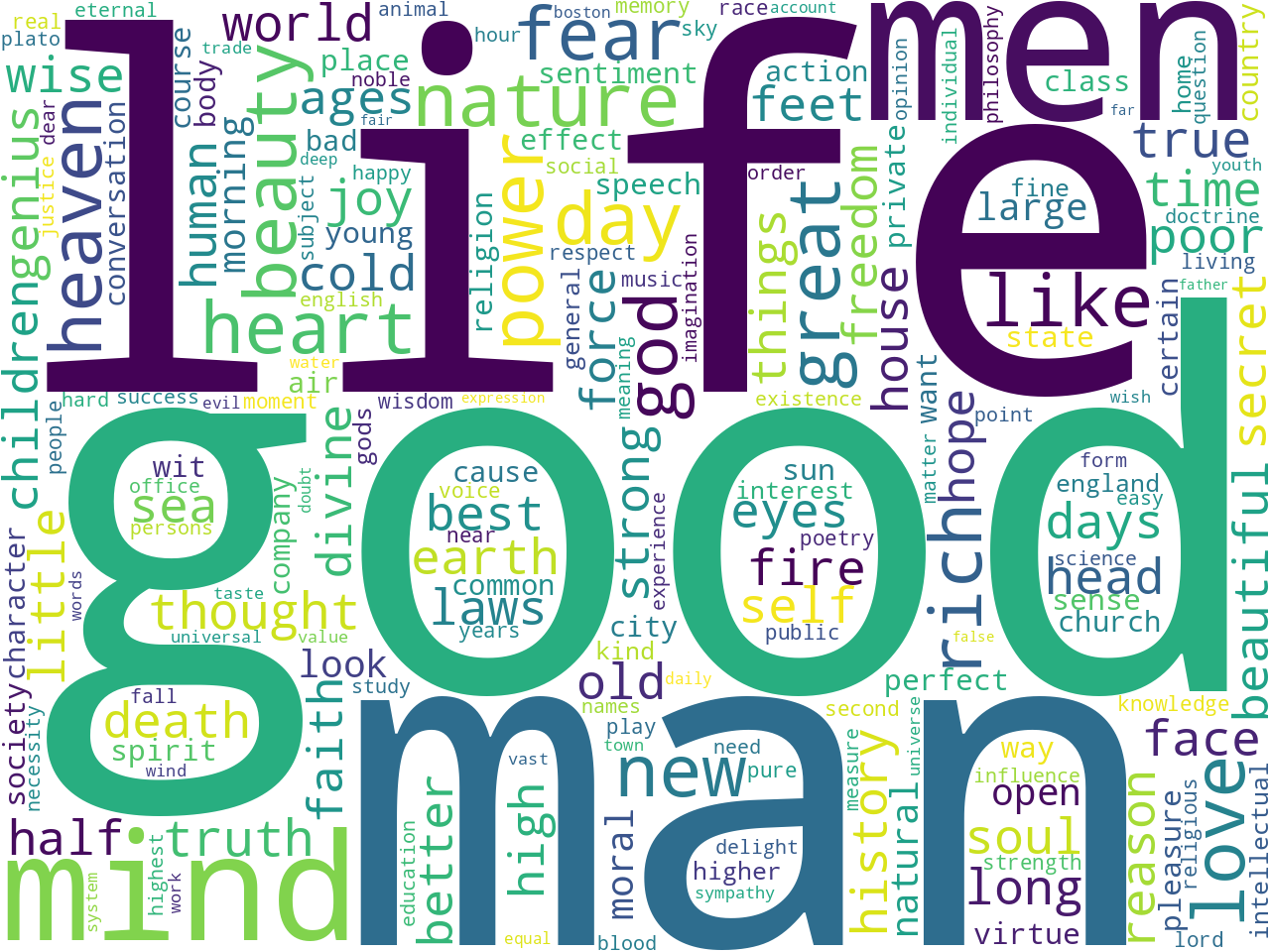
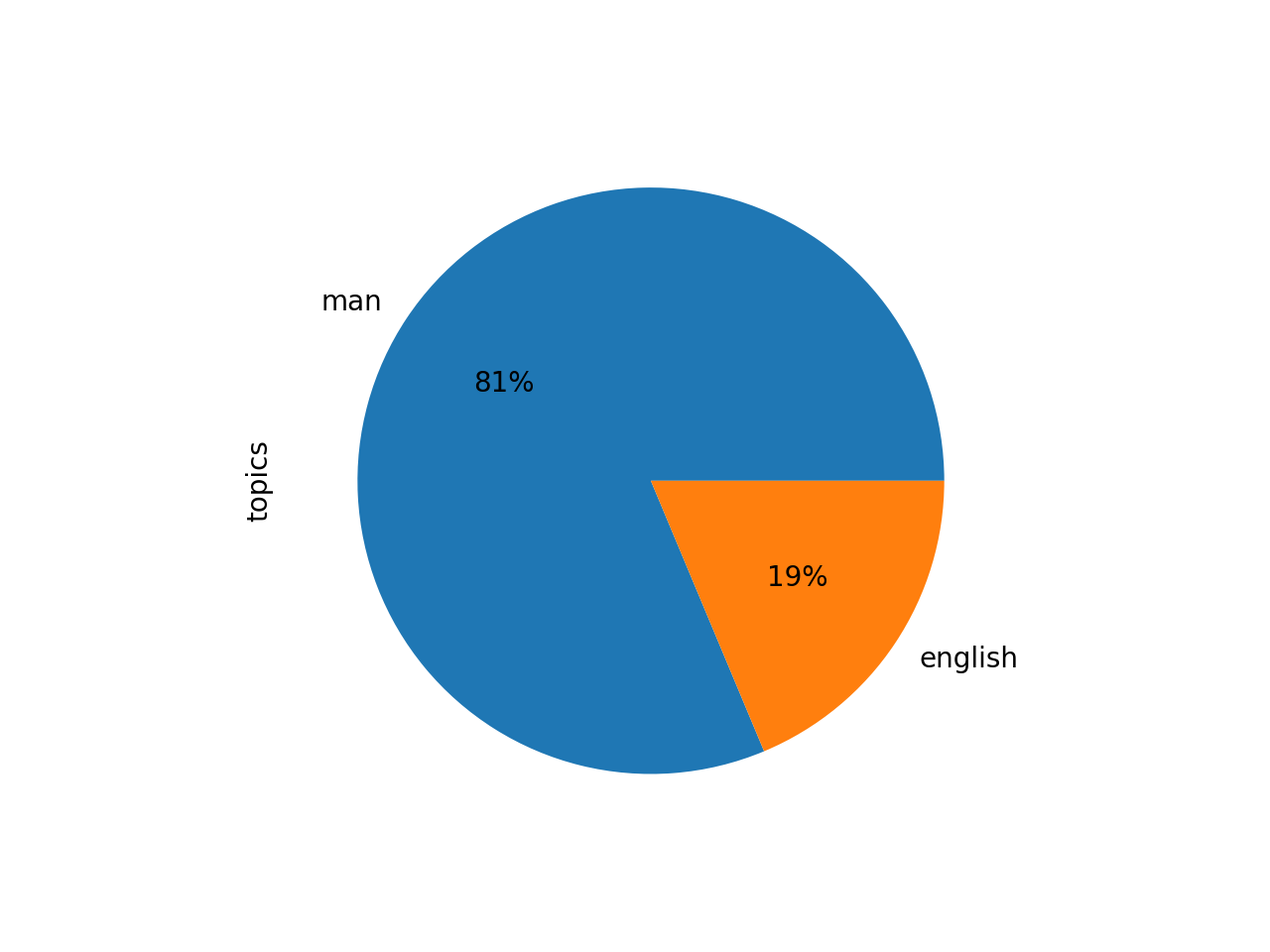
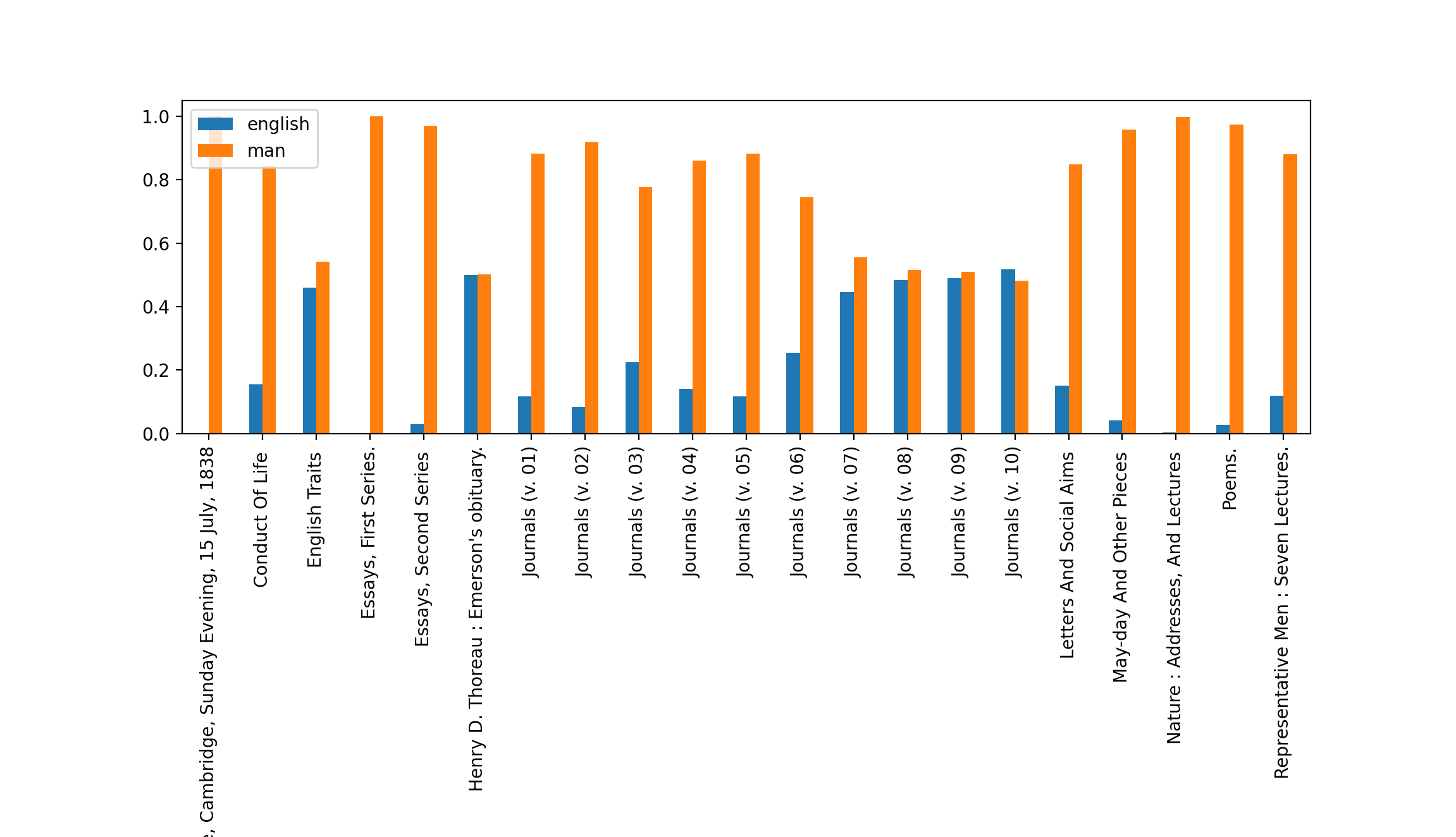
A theme of "man" is very prominent, and it is qualified with words like "men", "every", "nature", "life", "world", "good", "great", "shall", "must", "see", and "new". The second theme -- english -- is qualified with words like "england", "new", "good", "people", "see", "old", "men", "like", "day", "house", and "much":
labels weights words
man 2.19010 man men every nature life world great good sha...
english 0.50353 english new england good like see old people m...
The pie chart illustrates how three-quarters of the texts are about "man" (which is similar to the result of the feature reduction modeling process, and illustrated with the dendrogram), and the bar chart illustrates how many of his journals emphasized "english":
Information retrieval
After going through the aforementioned processes, the inquisitive researcher ought to have identified words, phrases, concepts, patterns, and/or anomalies of interest. Through the use and exploitation of a few information retrieval techniques, the same researcher can identify snippets of text, complete documents, or subsets of documents elaborating upon these things of interest. the techniques include concordancing, full text searching, and/or querying the underling relational database. Personally, I find concordancing for specific noun-verb combinations to be very useful. For our purposes, examples include: man is, men are, people are, humans are, etc. The results are more authoritative than frequencies or the clustering of documents, but they require additional thinking and interpretation to understand. Based on the result of some concordancing (
rdr concordance emerson-works -q 'man is'), apparently men are noble stoics, robins, fish, or obedient. Only a tiny number of the entire concordance results is listed below, but the whole result is linked
here :
to his wife he says of scott , " the man is a noble stoic , sitting apart here a
o causa conciliandi gratiam , that a man is a robin , and the chain is perfect ,
robin , and the chain is perfect , a man is a fish . it is not for nothing , tha
at is sweet or bitter . [ the ] good man is obedient to the laws of the world ,
The scholar will want to identify specific phrases of interest, use full text indexing to discover in which document(s) the phrases occur, and then peruse those documents in order to look at the phrases in a larger context. The following command queries the corpus for the phrase "man is" or "men are" and returns a relevancy-ranked list of matching documents:
rdr search emerson-works -q '"man is" OR "men are"'
For all intents and purposes, every document in the carrel includes the phrases "man is" or "men are', but very first document in the returned list is entitled
Representative Men . Hmmm... The process seems to be working.
:)
Grammars and semantics
For the most part, written languages are made up of nouns, verbs, and adjectives. These fundamental building blocks are called parts-of-speech, and they are combined together to form sentences. The rules for constructing sentences are called "grammars", and as grammatically correct sentences are articulated, the hope is to communicate semantically sound -- meaningful -- thoughts, feelings, or beliefs. Thus, by associating the words of a document with parts-of-speech and analyzing the result in terms of grammar, it is possible to identify meaningful sentences. Unfortunately, assigning parts-of-speech values is a non-trivial task, and it is not uncommon to express a sentence in non-grammatical ways. Thus, grammatic and semantic analysis is computationally challenging because computers do not operate very well with ambiguity.
All that said, it is possible to compute against a corpus and extract semantically interesting (and possibly meaningful) concepts. For example, the following Toolbox command outputs a sorted list of semi-structured statements whose subject is the word "man" and whose predicate is a form of the lemma "be":
rdr grammars emerson-works -g sss -n man -l be -s
A truncated list of results follows, thus outlining what a man might be, but the whole list is linked
here :
- man is a beggar who only lives to the useful
- man is a bundle of relations
- man is a channel through which heaven floweth
- man is a consumer
- man is a scholar
While quick and easy, such results are not complete sentences and therefore not complete ideas. Use the information retrieval techniques (above) to identify whence the statements came, and thus garner more context.
A different approach is to: 1) extract all the sentences from the carrel with the form <nounphrase><predicate><nounphrase>, 2) loop through the result searching for variations of the word "man" in the first noun phrase, 3) of the result, identify predicates containing a form of the lemma "be", and 4) output the matching sentences. Using such an algorithm, some of the definitions of man, man, woman, women, people, persons, human, or humans include the following, and all of them, as computed by this algorithm, are linked
here :
- A man is a golden impossibility.
- A divine person is the prophecy of the mind; a friend is the hope of the heart.
- Human life and its persons are poor empirical pretensions.
- For, rightly, every man is a channel through which heaven floweth, and, whilst I fancied I was criticising him, I was censuring or rather terminating my own soul.
- A man is a god in ruins.
- Man is a rude bear when men are separated in ships, in mines, in colleges, in monasteries.
Such results are more semantically sound -- more meaningful.
Yet another approach is to extract all the sentences in a corpus and prompt the researcher for a question, such as "What is a good man?" or "What is a great man?" Software can then measure the typographical (Euclidian) distance between the given questions with the extracted sentences, and finally return the sentences in sorted order. Using this approach the definitions of good or great men include the items below, but the full list is linked
here :
- The good man differs from God in nothing but duration.
- The good man has absolute good, which like fire turns every thing to its own nature, so that you cannot do him any harm.
- A great man is a new statue in every attitude and action.
- The great man loves the conversation or the book that convicts him, not that which soothes or flatters him.
Step #7 of 7 - Go to Step #1
The computing process used to read the the whole of Emerson's works ought to have provoked at least a few new questions in you, the student, researcher, or scholar. In fact, the process may have generated more questions than answers. Such is an inherent aspect of the research process. Consequently, it behooves the student to repeat the process because research is iterative. Go to Step #1.
Summary
This missive outlined a process that can be used to read the whole of a HathiTrust collection.
Some of you, gentle readers, may be challenged with the process, and the root of that challenge may be in the definition of the word "read". My reply is grounded in the assertion there are many different types of reading. One reads a scholarly article differently than they read a novel. One reads a novel differently than they read a candy bar wrapper. One reads a candy bar wrapper differently than they read movie credits, recipes, road signs, insurance policies, etc.
With the advent of computers and the increasing amount of digitized materials (as well as materials born digitally), there is a need to learn how to read in a new way. This new way of reading, coined by Franco Moretti in the year 2000, is called "distant reading", and it is intended to complement the process of "close reading". This missive outlined a form of distant reading.
Distant reading is not intended to be a replacement for traditional reading nor close reading. Instead, it is a supplemental process with its own distinct advantages and disadvantages. For example, distant reading scales very well; one can quickly peruse, analyze, or characterize ("read") the whole of a corpus rather easily. On the other hand, distant reading suffers from the lack of nuance and context; written language is inherently ambiguous, and as mentioned previously, computers suffer greatly sans highly structured data/information. It can not be stated strongly enough, distant reading is not a replacement for traditional reading but rather a supplement.
In conclusion, the process outlined in this essay can be applied to any type of literature. Ask a question. Collect materials which might address the question. Ideally, describe the materials with metadata. Perform text mining and natural language processing against the collection, and save the result as a data set -- something inherently computable. Compute against the data set in an effort to address the question. Repeat.
