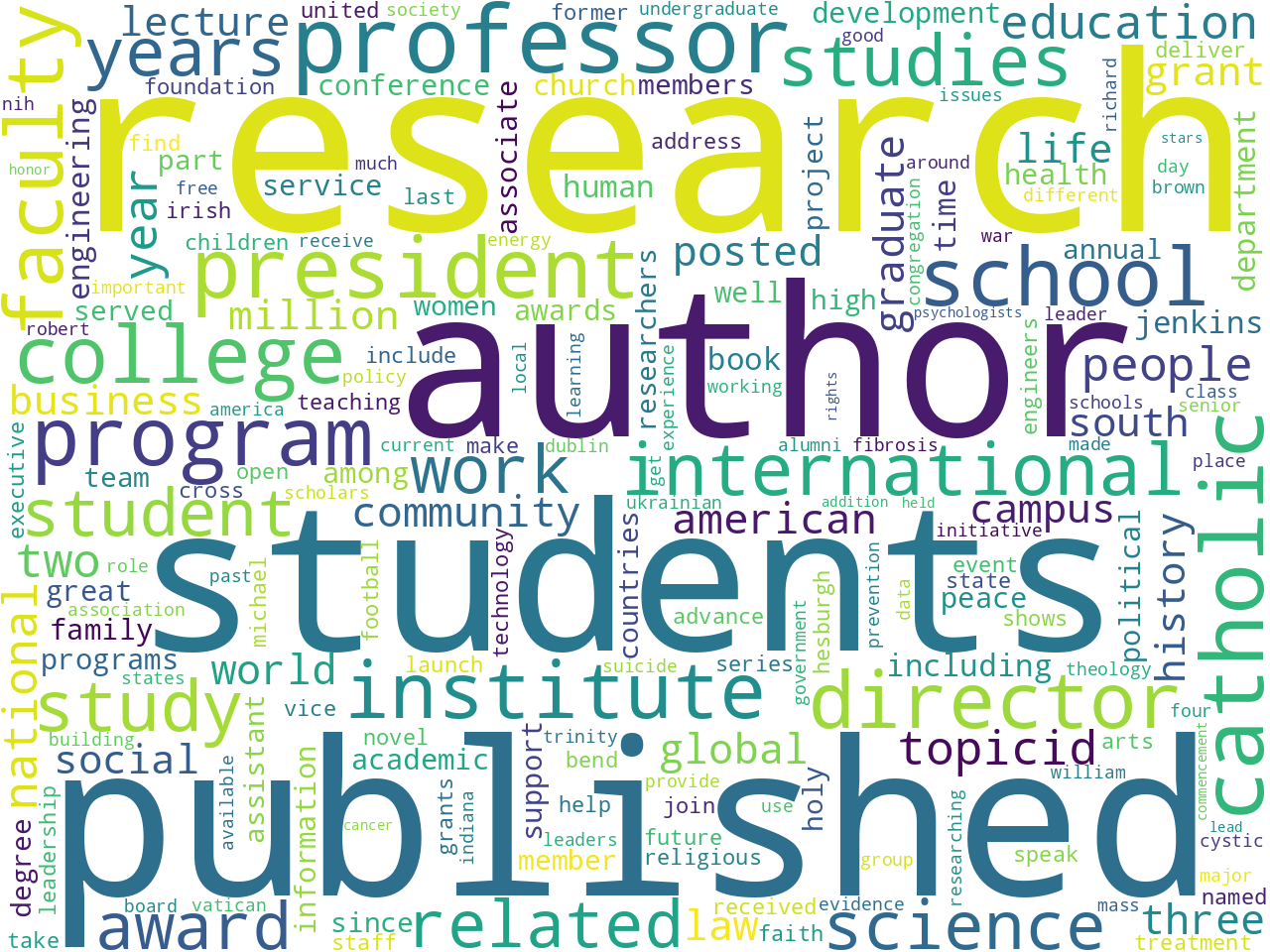
most common words
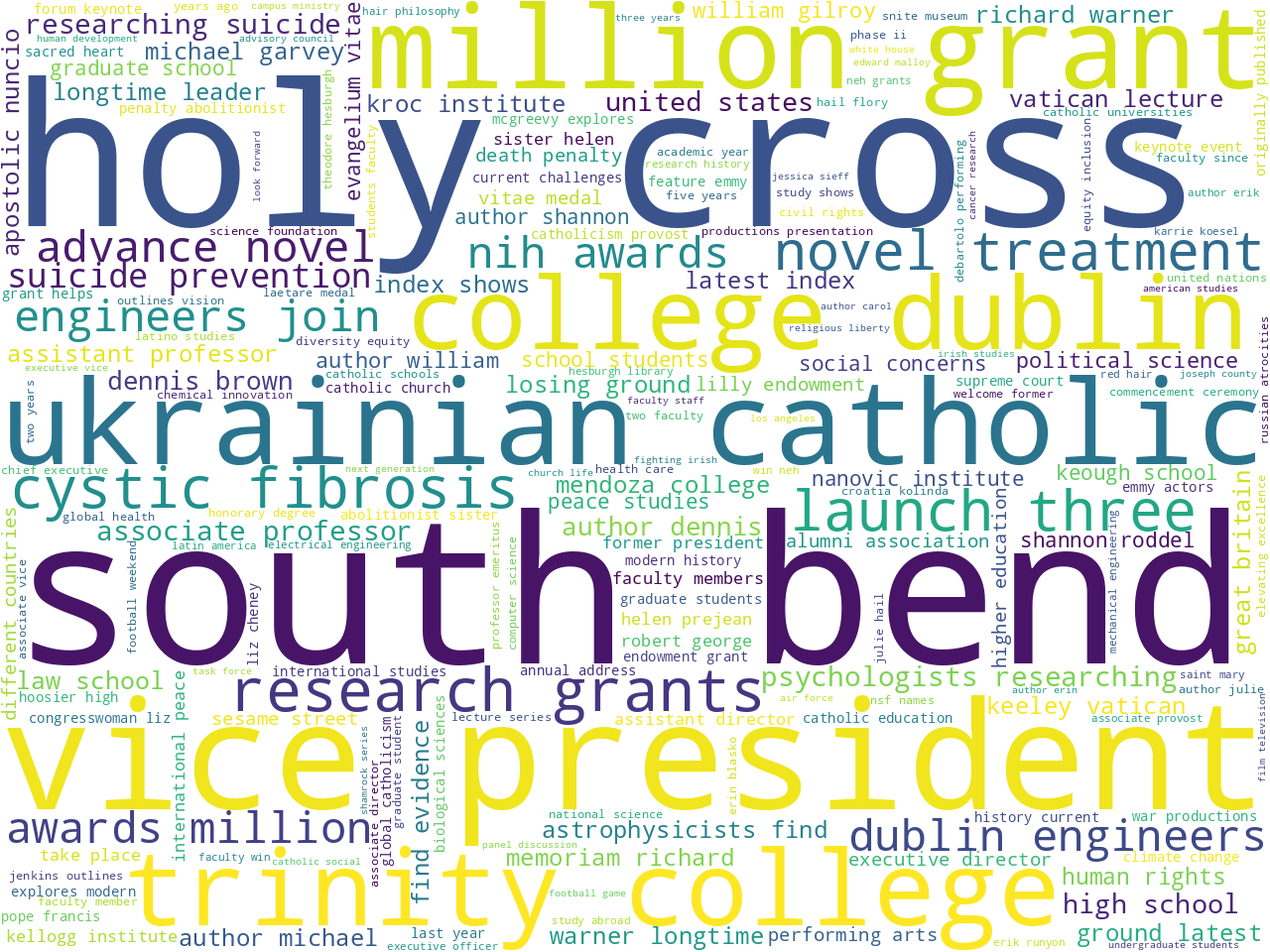
most common two-word phrases
I have done a bit of analysis -- reading -- against the set of news distributed by the University of Notre Dame, and below is some of what I learned.
A lot of the University's news is distributed via the Web, and the root of the news is located at https://news.nd.edu. Late last calendar year I used program called wget to crawl the news site and cache the result. Upon closer inspection of the cache, I noticed how some of the Web pages were echoed and indexed in a number of auxiliary pages. I deleted the echoes and index pages, and I copied all of the news stories to a single directory. I then applied a tool called the Distant Reader Toolbox against the directory. This resulted in a data set of news stories which I proceeded to analyze.
There are about 10,000 articles in the data set, which includes articles from about the past two decades, I think. The data set is about 6.1 million words long, which is bigger rather than smaller. By comparison, Moby Dick is about .25 million words long, and the Bible is about .8 million words long.
Now that I have the data, what do I want to know? Well, my research questions are, "What does the news discuss? Who and what is in the news? If I were to enumerate the themes of the news, then what might those themes be, and to what degree are they mentioned compared to the other themes?" In the end, I really want to know, "What are the University's emphases?"
One way to address these questions is to observe simple frequencies. For example, illustrations of the most common words, two-word phrases, nouns, pronouns, named-entities, and statistically significant keywords all allude to what is brought to light in the news. If you ignore things like "facebook", "youtube", "twitter", and "grace hall" (which are all a part of the news feeds' boilerplate texts), then things like research, Catholicism, and awards present themselves. Upon closer inspection, a few disciplines present themselves. Medicine, law, religion, and business are good examples. See below:
most common words |
most common two-word phrases |
 nouns |
 pronouns |
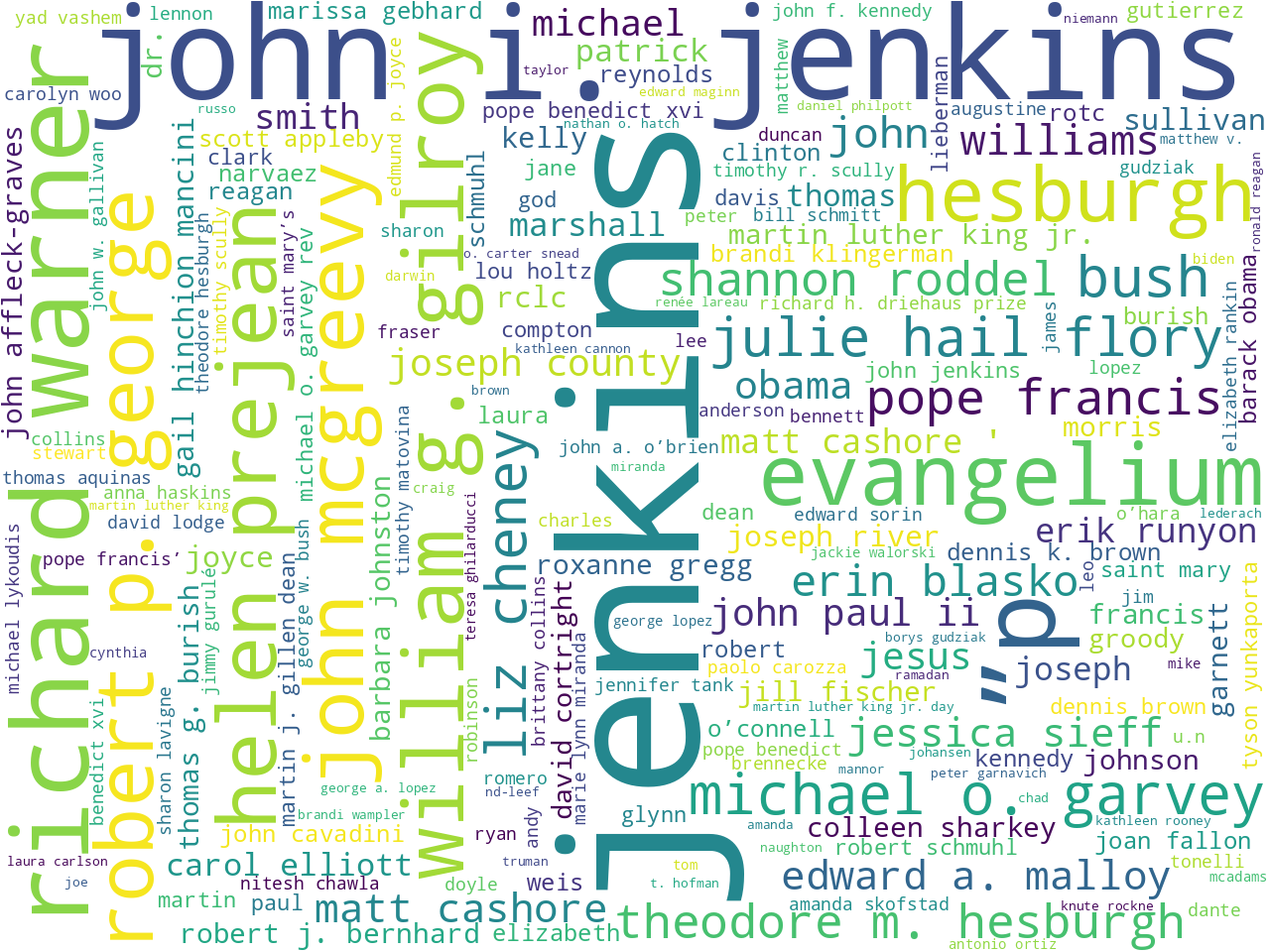 persons |
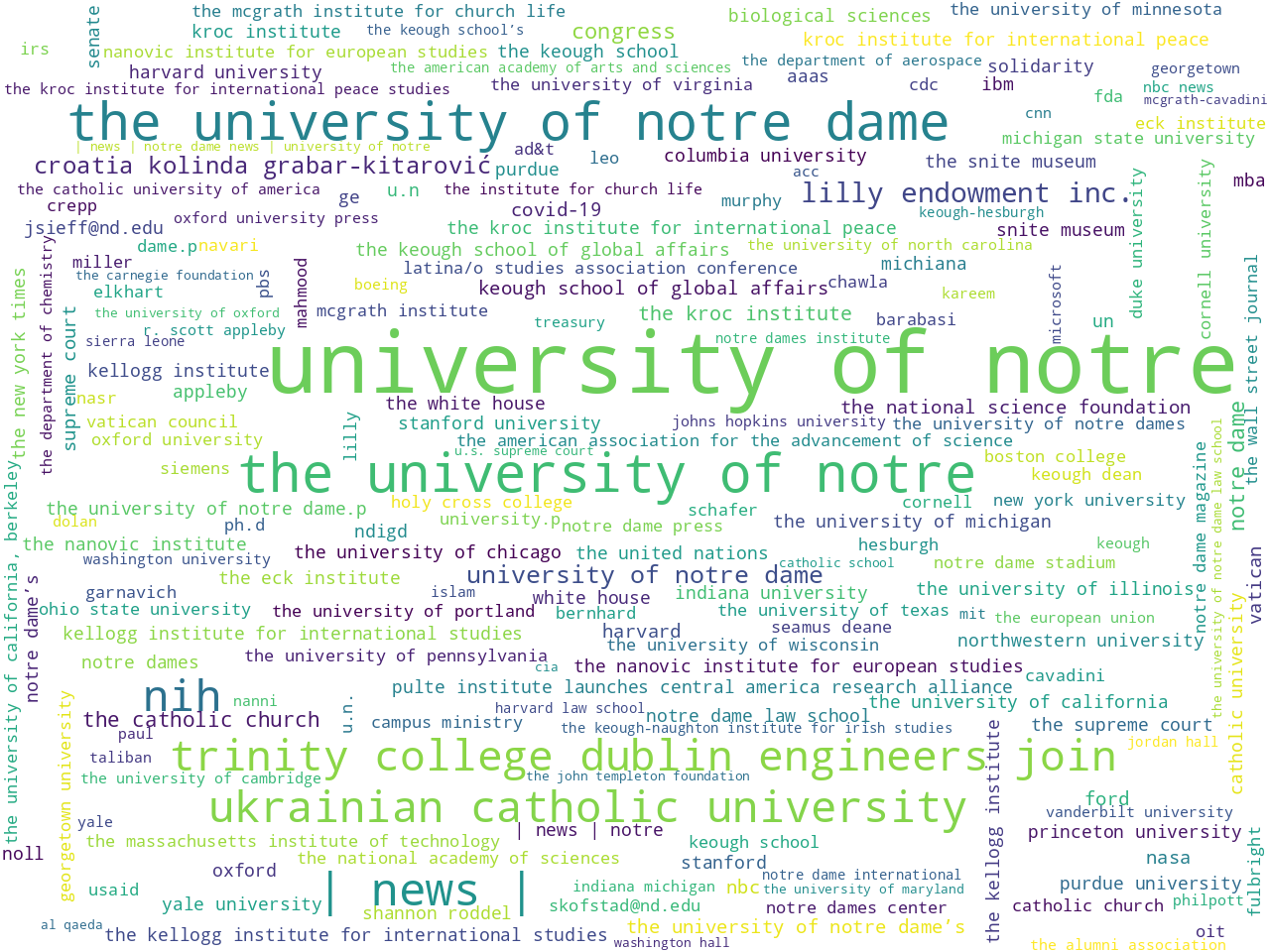 organizations |
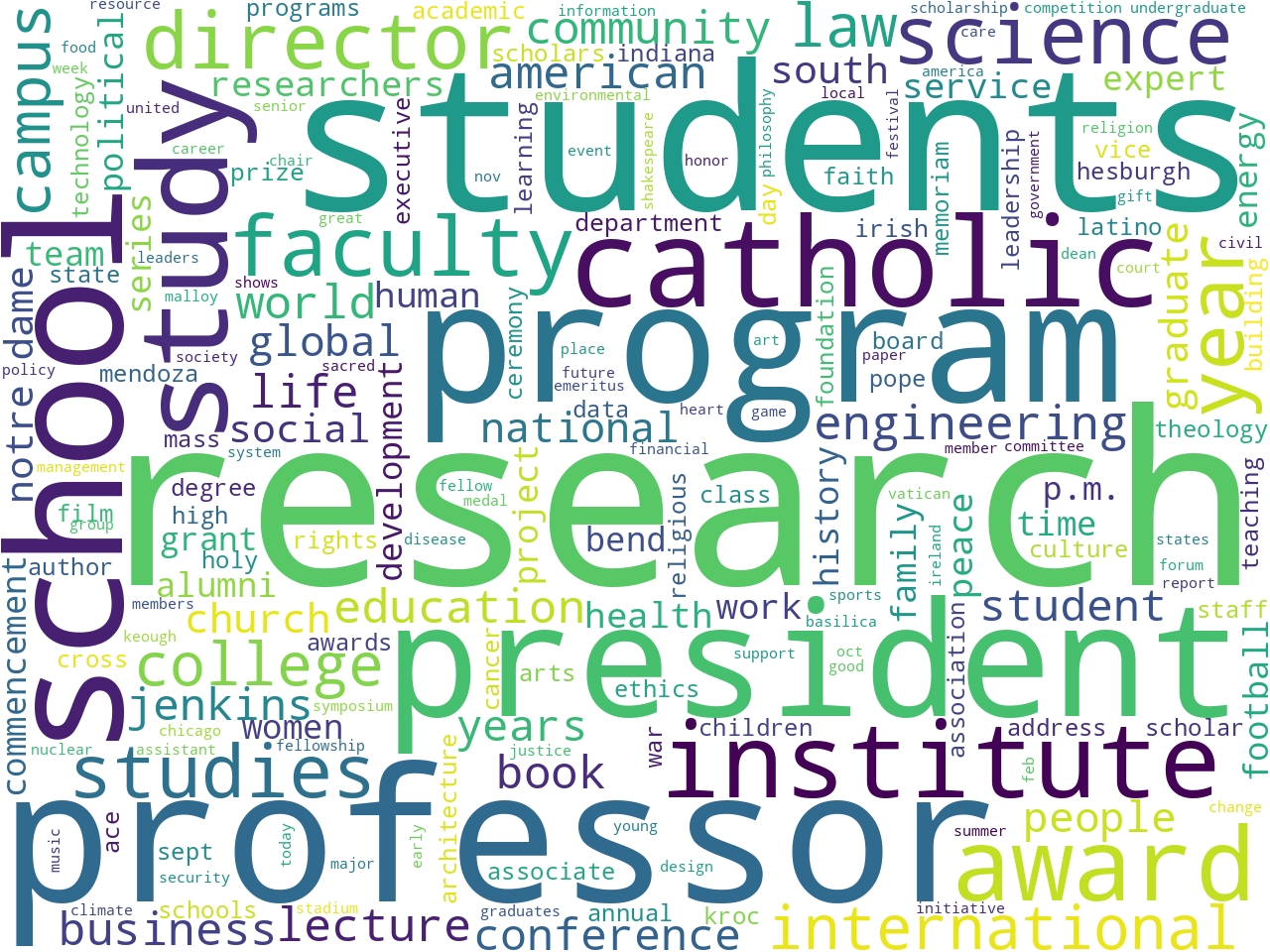
statistically significant keywords
The observations above are akin to a set of descriptive statistics, and for more detail see the automatically generated summary page complete with more descriptive statistics and rudimentary bibliographics.
Using the statistically significant keywords as query terms -- while ignoring things like "notre", "dame", "university", and "news' -- what sorts of articles are represented by the keywords? Below are some examples, and for the most part, the stories seem to be about people:
Another way to connote "aboutness" is to apply topic modeling. Succinctly stated, topic modeling is an unsupervised machine learning process used to enumerate latent themes in a set of texts. Given an integer (T), topic modeling will divide a set of texts into T subsets, and each subset can be likened as a theme or "topic". (By the way, there is no correct value for T, after all, how many things -- T -- is the whole of Shakespeare's writings about? That said, topic modeling can be quite informative.)
If I denote T equal to 1, then I can answer the question, "If there was one word used to describe the aboutness of the news corpus, then what would that word be?" After applying topic modeling, the answer is "research".
If I denote T equal to 4 and if I denote 4 words (features) to be used to elaborate upon the resulting four topics, then the result looks like this:
topics weights features
students 0.27181 students program school president
professor 0.22178 professor catholic institute international
people 0.15017 people time years life
research 0.13037 research study professor science
The story become even more interesting when T equals 16:
labels weights features
students 0.16036 students program education school programs sch...
people 0.13684 people time life years world good think know
president 0.12150 president degree served board years vice gradu...
lecture 0.10432 lecture conference author published professor ...
south 0.08750 south community bend campus students local bui...
professor 0.08170 professor book history american published stud...
research 0.07842 research study shows data published social col...
award 0.07240 award students graduate student awards researc...
law 0.07149 law political professor court rights war justi...
catholic 0.07021 catholic church holy faith life cross pope jen...
engineering 0.06900 research engineering science professor faculty...
international 0.06491 international institute peace global studies r...
film 0.06018 film arts music art author published performin...
football 0.04996 football jenkins athletics stadium irish game ...
cancer 0.04220 research cancer health researchers study disea...
physics 0.02319 physics stars research space star nuclear team...
The following pie chart illustrates the weights of each theme compared to the others. Notice how no single theme dominates:
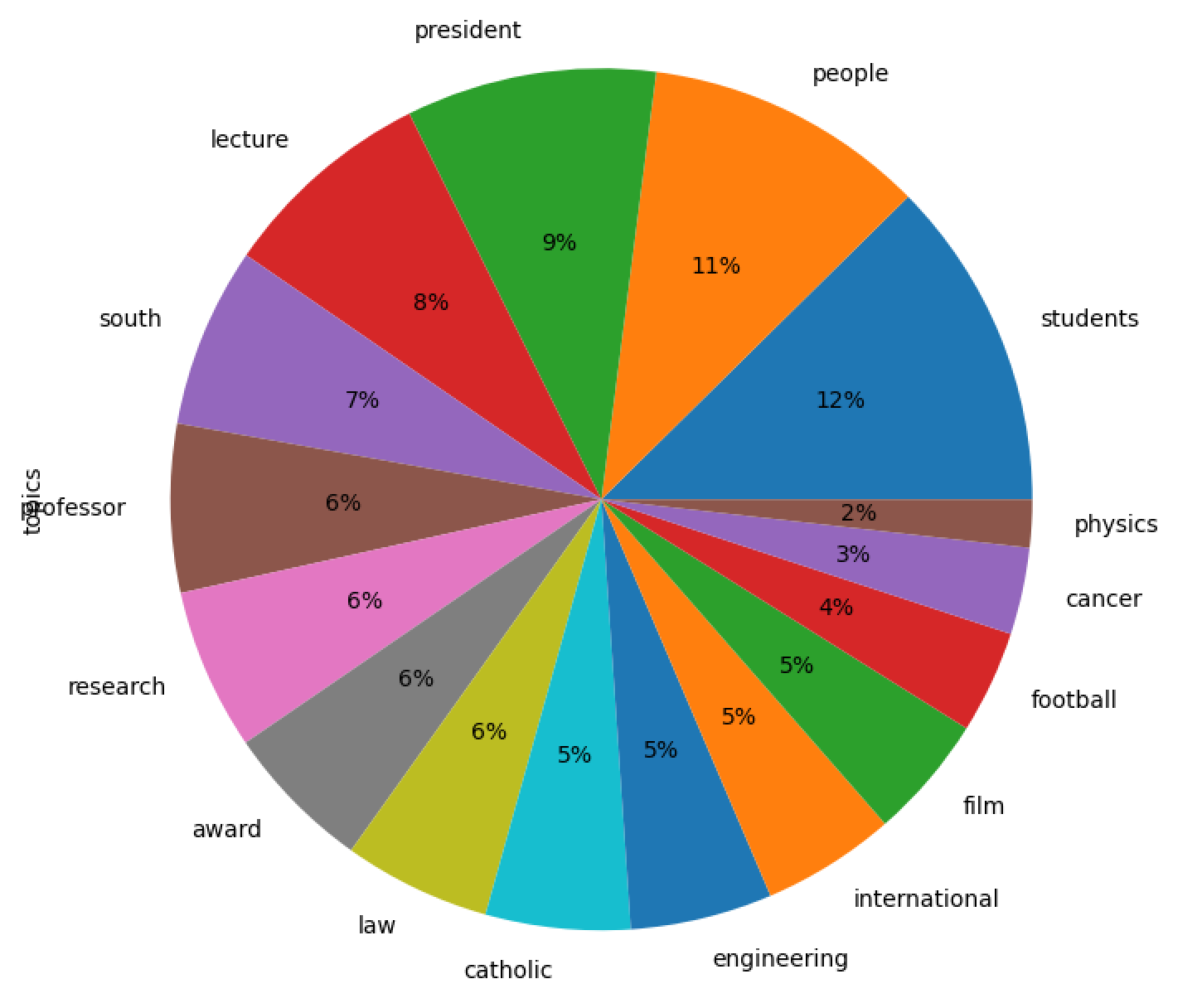
In an effort to learn about the emphases of the University, I used computer technology to read the news. The results (above) are merely bunches o' observations. Interpretations of the observations ought to be accepted with more than a grain of salt. That said, if the news is representative of the University's emphases, then I assert the emphases are people and research, or more specifically: 1) people practicing Catholicism, and 2) research primarily in the areas of science, technology, engineering, and medicine.
This whole process could be improved in a number of ways. First of all, date values could be associated with each news story, and if they were, then trends could be observed over time, but alas, date values are not explicitly represented in the content's metadata. Second, much of the boilerplate content -- headers and footers -- could be removed before processing. This would make the output cleaner, but I doubt the result would change very much.
This data set -- study carrel -- ought to be available for downloading at http://carrels.distantreader.org/curated-notre_dame_news-2022/index.zip.
Fun with data science -- data science with words.
Eric Lease Morgan <emorgan@nd.edu>
Navari Family Center for Digital Scholarship
University of Notre Dame
Date created: February 22, 2022
Date updated: June 1, 2024